




排序在工作中是经常需要使用的一个需求,比如按照id升/降序排序数据,或者按照更新时间升/降序排列数据,排序的过程是怎样的以及怎样优化排序?分页场景中的limit是否能有效减少扫描行数?
create table test_sort(id bigint(20) primary key auto_increment,name varchar(255),address varchar(255),order_num int(11),key idx_order_num(order_num));DROP PROCEDUREIFEXISTS sort_insert;DELIMITER;;CREATE PROCEDURE sort_insert ( ) BEGINDECLAREi INT DEFAULT 0;WHILEi < 100000 DOinsert into test_sort(name, address, order_num)values (concat('bear', i), concat('kang', i), 100000 - i);set i = i + 1;END WHILE;COMMIT;END;;CALL sort_insert ();复制
创建测试排序表如下,其中id为主键,sort_num有索引,往表里面插入10万行测试数据。首先看根据name字段排序结果取前100条的执行计划。

可以看到执行计划显示using filesort表示使用文件排序,即磁盘临时表排序,并且预估扫描行数超过十万,表示该排序会走全表扫描,这个排序过程是MySQL取出一整行放在sort buffer,假设可以放10000行,则将此一万行按name排序之后写入磁盘临时表,接着取下一个10000行,重复此步骤直到100000行全部排序完毕即分为10个临时表,然后根据归并排序取出100行数据返回。
可以看出排序过程中产生的临时文件个数是 总行数/一次放入sort buffer的行数,因此一次放入的数据行越多,那么生成的磁盘临时表也就越少,这样效率也就会越高,根据上面分析不难看出,sort buffer能放多少行,取决于sort buffer的大小和需要放入的排序数据的长度,需要放入的排序数据一般是排序字段+额外字段,参数max_length_for_sort_data用来设置用于排序字段的最大长度,假设设置为50,那么sort buffer一次可能可以放入30000行,然后根据name排序生成临时文件,再使用归并排序取出结果行(如果需要回表的场景则将id排序回表取出完整数据,避免磁盘随机读),这种排序跟全字段排序相比优势在于减少了磁盘临时表,但是增加了一次回表的开销,因此效率也不会很高,并且limit也不能有效限制扫描行数。
上面的排序之所以算法复杂是因为数据本身是无序的,前面索引已经说过了许多数据本身是有序的,如果我们的排序字段本身有序,那么排序本身这个过程就不是必要的了,而是一次链表的连续读取。比如根据id或者order_num字段排序,因为索引本身有序,结果集就是有序,且limit明确的知道前100行即为结果集,停止向后扫描,因此扫描行数也就是100,执行计划如下。
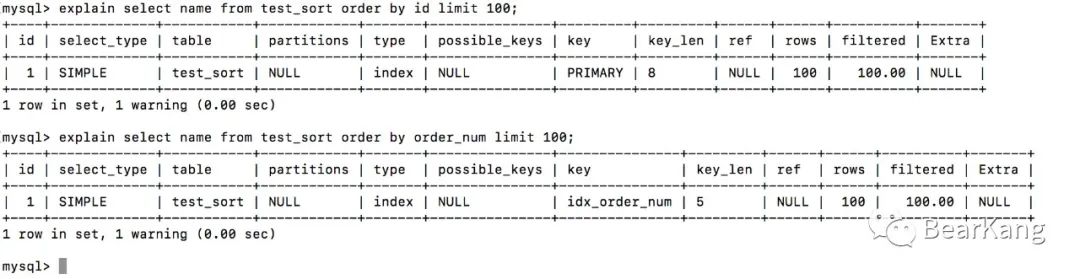
关于排序,MySQL可能会根据数据量的不同而选择不用的排序算法,因此如果排序字段没有索引的情况下,如果MySQL刚好使用了非原地排序算法,那么翻页的过程中可能会出现数据重复的现象,如果排序字段没有索引,要格外注意这个bug,可以额外添加一个id字段规避,或者根据业务做合理规避。
总结
1.若数据本身有序,则不需要额外排序。
2.若数据无序,且max_length_for_sort_data允许的情况下,MySQL会使用全字段排序,因为优先使用内存而不是磁盘。
3.若数据无序,且max_length_for_sort_data不能放入结果集的字段,MySQL会使用row id排序。
4.磁盘临时表的生成是先内存排序转向磁盘的过程,select语句如果跟随sql_big_result可以显示告诉引擎结果集很大,内存临时表无法满足,而直接生成磁盘临时表,省去内存临时表的开销, 此种方式一般适用于带有group 的条件中。
