开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群。

最近一段工作很少优化SQL ,实际
上7-8年前的确有一段疯狂优化的“美好时光”。 最近一个同事提出一个问题,他的一个POSTGRESQL 的SQL 在运行中因为客户的需要,将语句添加limit 1 ,但是在添加完毕后,整体语句运行时间超过原有的语句少则9倍,多则20多倍,从不到2秒,变成了23秒。
下面是语句的修改版,不少部分已经改名了。
gb.market_price "marketPrice",gb.discount_rate * 100 "discountRate",gb.income_money "ticketIncomeMoney",gb.div_ticket_name "divTicketName",btpg.ticket_count "ticketCount",
btpg.pay_money "payMoney",
( gb.market_price - gb.price ) * btpg.ticket_count "discMoney",
WHEN btpg.ticket_sale * btpg.ticket_count > btpg.pay_money ELSE btpg.ticket_sale * btpg.ticket_count btpg.no_give_change "noGiveChange",
btpg.ticket_code "ticketCode",
btpg.create_time "useTime",
bb.settle_bizzz_date "settlebizzzDate",
COALESCE ( btpg.income_overchange, 0 ) "incomeOverChange" ,
pw_detail_id as "ticketRowId"
REPLACE ( REPLACE ( REPLACE ( REPLACE ( ticket_code_serials, '["', '' ), '"]', '' ), '"', '' ), ',', ';' ) AS ticket_code,
WHERE create_shop_id IN ( SELECT ID FROM dbi_shop WHERE center_id = 83726 AND manage_type_id IN ( 301, 302, 304 ) )
AND modify_time >= '2023-03-02 00:00:00'
AND modify_time <'2023-03-03 00:00:00'
INNER JOIN (SELECT ID,code,settle_bizzz_date FROMcreate_shop_id IN ( SELECT ID FROM dbi_shop WHERE center_id = 83726 AND manage_type_id IN ( 301, 302, 304 ) ) AND settle_time >='2023-03-02 00:00:00' AND settle_time < '2023-03-03 00:00:00'AND STATE = 1
AND delflg = 0 ) bb ON btpg.bs_id = bb.
INNER JOIN ( SELECT ID FROM arch_pay c WHERE payc_type_id = 509 ) ap ON btpg.payc_id = ap.IDLEFT JOIN ( SELECT deal_id, belong_shop_id, title, market_price, price, discount_rate, income_money, synchron_time, div_ticket_name WHERE create_shop_id = 83726 ) gb ON btpg.ticket_id = gb.deal_id AND btpg.create_shop_id = gb.belong_shop_idINNER JOIN ( SELECT deal_id, belong_shop_id, MAX ( synchron_time ) synchron_time WHERE create_shop_id = 83726 GROUP BY belong_shop_id, deal_id ) gbTicketFilter ON gb.deal_id = gbTicketFilter.deal_id AND gb.belong_shop_id = gbTicketFilter.belong_shop_id AND gb.synchron_time = gbTicketFilter.synchron_timeINNER JOIN ( SELECT payc_id, NAME FROM arch_o2o_seller ) os ON os.payc_id = btpg.payc_idLEFT JOIN dbi_shop shop ON shop.ID = btpg.create_shop_id
"shopName","ticketName","marketPrice","ticketRowId";
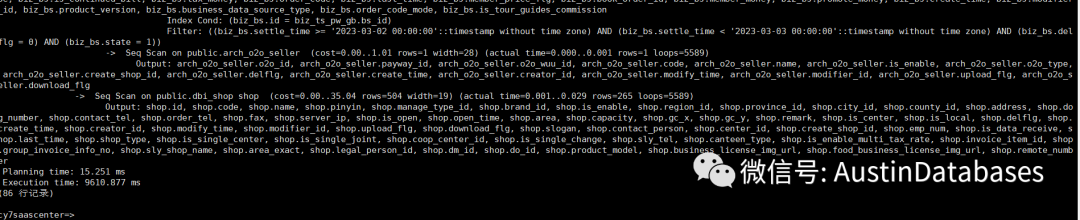
首先比对执行计划,虽然仅仅是一个limit 的添加但是整体的执行计划都改变了,在没有添加LIMIT 1的情况下,整体的语句的查询中是没有 大量的seq scan ,基本上整体整体的语句中对于数据处理都是在index scan.
在添加LIMIT 1 后,整体的语句的执行顺序,与原先的顺序不同了,不添加limit 1 ,首先处理了语句中最大的表,由于最大的表的数据过滤的条件多,所以对于排除数据起到了相关的提前过滤的作用。而添加了limit 1后,整体的语句处理的顺序和语句撰写的从上到下的语句关联的顺序基本一致,导致处理从小表开始进行预先处理。最终导致小表驱动大表的情况。在不添加LIMIT 1 的情况下,整体上层的 语句中的计算部分使用中由于,执行顺序的问题,让大表的数据过滤后,在被上层使用,减少了计算的数据量,而反观添加了LIMIT 1 后的语句,计算中过滤的行较多。导致计算成本升高。
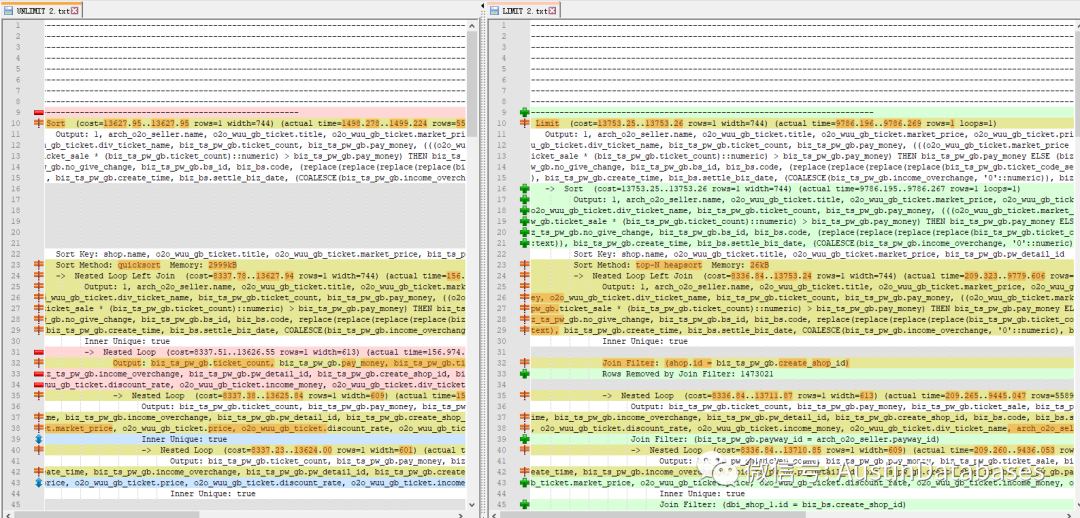
sort 的部分中的语句执行的整体计划的顺序,与加入了limit 的整体计划的顺序是错位的。SORT 没有limit 的部分,中的驱动表与驱动表之间是通过index 关联的方式进行的处理。
limit 而在末尾加入了limit 后,整体的执行计划,驱动表和被驱动表的位置互换了,通知对于驱动表的执行的方式变为了扫描方式。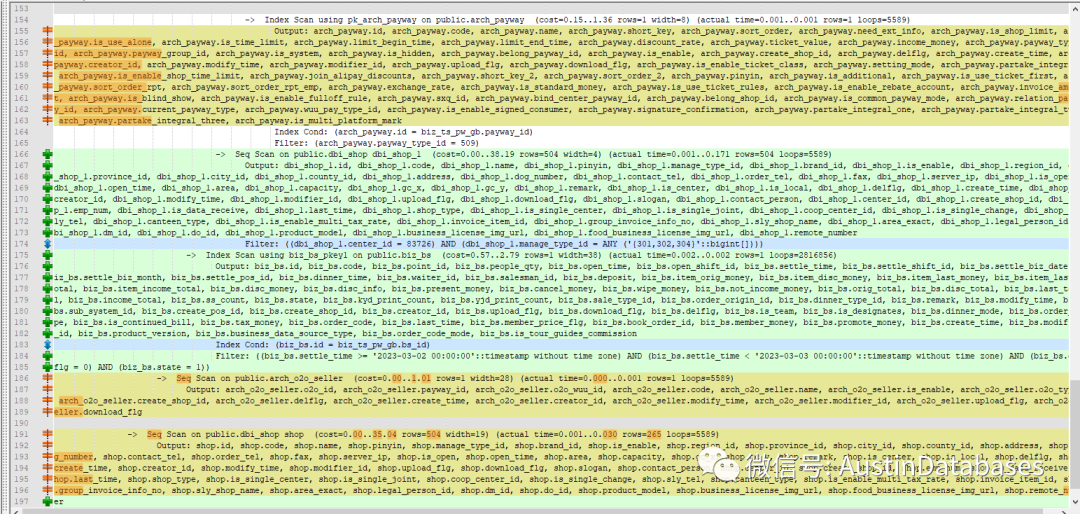
由于语句是否的复杂,如果要非常的明白的分析出来,则需要很长的时间,实际上抓住了两点
1 复杂的语句如果使用了limit 1,需要注意在POSTGRESQL 13中的语句是否还能通过优化器,优先判断对数据进行大表过滤,由于使用LIMIT 1 这样的语句,导致语句优化和执行系统对于提取的数据的有序性判断过于复杂,导致优化器,按照语句的撰写方式进行了数据的执行,保证提取数据的优秀和有效性,同时多个不同表的字段最终进行排序,加重了执行分析器的负担,导致执行分析器躺平,做了保守的执行计划的操作。
2 业务逻辑是否需要对于LIMIT 1 的语句进行排序的分析,这点非常有必要,在语句的执行中大部分语句的撰写尤其类似这样OLAP 很重的语句一般都带有排序,但是如果只是在结果中取一个结果 limit 1 则是否有必要进行排序这点非常有必要进行确认。一般根据语句的逻辑,是没有必要进行排序在LIMIT 1,因为你是随机取和顺序是无关的。
这个语句实际上最后优化的手段就是去掉ORDER BY ,最终去掉后比原先的同样的条件,执行的效率提高了 62倍,在 150毫秒左右就将结果计算出来,同时还有一个因素是如果你在撰写语句的时候带有LIMIT 1 则POSTGRESQL 的优化器会优先选择计算成本中,第一个启动成本较低的执行计划而不是整体成本较低的执行计划,所以建议在一些语句中,考虑业务的需求的情况下,分析是否有必要进行排序,慎用在复杂语句中的排序导致的执行效率低下的问题。
另外这里还有一个在使用LIMIT 1 后导致的PG执行计划的倾向性的问题,你造吗 !