




我们都知道索引是有序的,索引存储键值,那么如果需要通过索引找到表中某行数据,pg和oracle是通过什么方式定位,以及对表进行插入、更新操作不同。 主要内容如下:
PG中表的insert、update、truncate的介绍
Oracle中表的insert、update、truncate的介绍
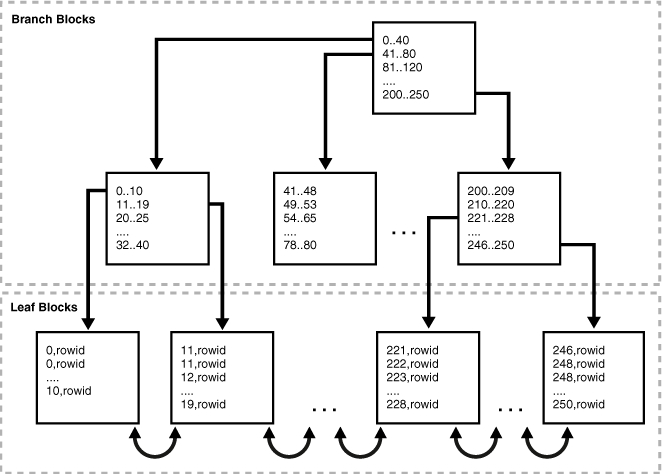
Oracle 除了存储键值,还存储了一个定位到表数据的rowid
ROWID 记录 物理对象号、相对文件号、块号、行号,表中不存储
Postgresql除了存储键值,还存储了定位到表数据库的 ctid
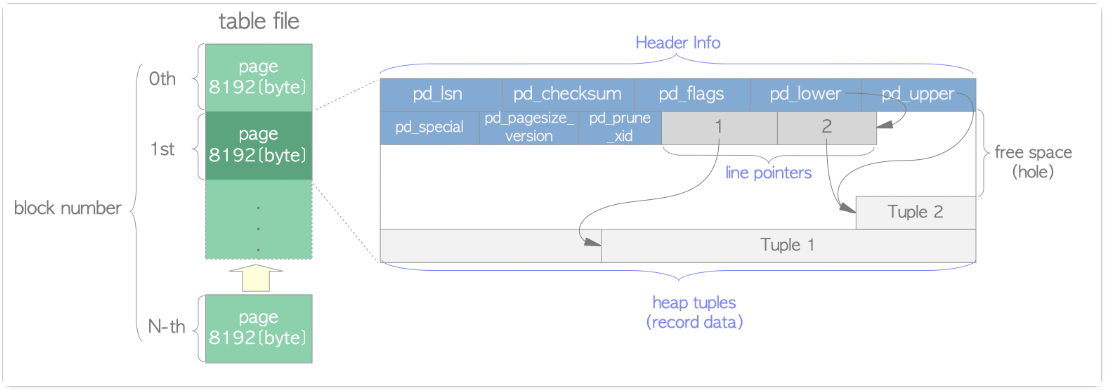
postgres=# select lp,lp_off,t_xmin,t_xmax,t_ctid,
tuple_data_split('t1'::regclass,t_data,t_infomask,t_infomask2,t_bits)
from heap_page_items(get_raw_page('t1',0));
lp | lp_off | t_xmin | t_xmax | t_ctid | tuple_data_split
----+--------+--------+--------+--------+-------------------------------------
1 | 8152 | 7731 | 7735 | (0,13) | {"\\x01000000","\\x0b79616e67"}
2 | 11 | | | |
3 | 8112 | 7715 | 0 | (0,3) | {"\\x03000000","\\x0f5a5a5a5a5a5a"}
4 | 8072 | 7715 | 0 | (0,4) | {"\\x04000000","\\x0f505050505050"}
5 | 8032 | 7715 | 0 | (0,5) | {"\\x05000000","\\x0f555555555555"}
6 | 7992 | 7715 | 0 | (0,6) | {"\\x06000000","\\x0f454545454545"}
7 | 7952 | 7715 | 0 | (0,7) | {"\\x07000000","\\x0f525252525252"}
8 | 7912 | 7715 | 0 | (0,8) | {"\\x08000000","\\x0f474747474747"}
9 | 7872 | 7715 | 0 | (0,9) | {"\\x09000000","\\x0f4d4d4d4d4d4d"}
10 | 7832 | 7715 | 0 | (0,10) | {"\\x0a000000","\\x0f585858585858"}
11 | 7800 | 7732 | 0 | (0,11) | {"\\x02000000","\\x0561"}
12 | 7768 | 7729 | 0 | (0,12) | {"\\x0b000000","\\x076c69"}
13 | 7728 | 7735 | 0 | (0,13) | {"\\x01000000","\\x0b79797979"}
(13 rows)
--如果更新非索引列,索引不变
postgres=# select * from bt_page_items('idx_t1_id',1);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | tids
------------+--------+---------+-------+------+-------------------------+------+--------+------
1 | (0,1) | 16 | f | f | 01 00 00 00 00 00 00 00 | f | (0,1) |
2 | (0,2) | 16 | f | f | 02 00 00 00 00 00 00 00 | f | (0,2) |
3 | (0,3) | 16 | f | f | 03 00 00 00 00 00 00 00 | f | (0,3) |
4 | (0,4) | 16 | f | f | 04 00 00 00 00 00 00 00 | f | (0,4) |
5 | (0,5) | 16 | f | f | 05 00 00 00 00 00 00 00 | f | (0,5) |
6 | (0,6) | 16 | f | f | 06 00 00 00 00 00 00 00 | f | (0,6) |
7 | (0,7) | 16 | f | f | 07 00 00 00 00 00 00 00 | f | (0,7) |
8 | (0,8) | 16 | f | f | 08 00 00 00 00 00 00 00 | f | (0,8) |
9 | (0,9) | 16 | f | f | 09 00 00 00 00 00 00 00 | f | (0,9) |
10 | (0,10) | 16 | f | f | 0a 00 00 00 00 00 00 00 | f | (0,10) |
11 | (0,12) | 16 | f | f | 0b 00 00 00 00 00 00 00 | f | (0,12) |
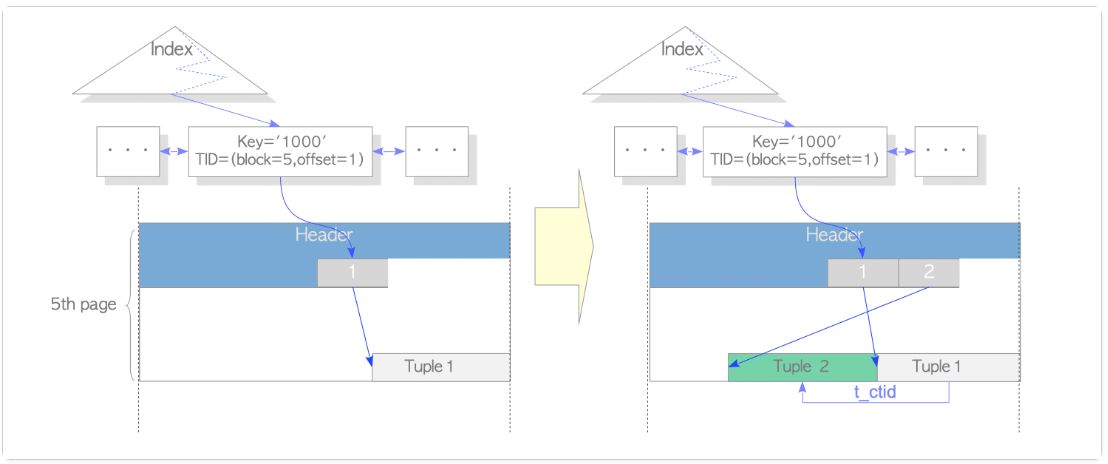
12 | (0,14) | 16 | f | f | 0c 00 00 00 00 00 00 00 | f | (0,14) | 复制另一个提醒点,是pg中有个功能叫HOT,更新时为了减少索引变动,ctid不变,通过旧行调整至新行,如果更新多次,在一定条件下旧数据行也是可以被清理,碎片整理(如执行select操作后,可能就将行指针重定向了),减少一些空间占用,比vacuum轻量一些。Old versions of updated rows can be completely removed during normal operation, including SELECTs, instead of requiring periodic vacuum operations. (This is possible because indexes do not reference their page item identifiers.)
截断,直接将操作系统表文件删除,创建一个新的文件,即relfilenode变了
postgres=# select relname,oid,relfilenode from pg_class where relname='t1';
relname | oid | relfilenode
---------+-------+-------------
t1 | 74508 | 74511
(1 row)
--截断后,表结构还在,物理文件-操作系统文件丢失了,无法恢复
postgres=# select pg_relation_filepath('t1');
pg_relation_filepath
----------------------
base/13892/74511
(1 row)复制

pct_free(剩余多少空间,用于update,默认10%) ,pct_use
Oracle表中行的更新跟pg类似,都是新插入一行,将原来数据标志为已删除,行号不变,块中位置改变,块头中有记录行位置的指针,也会更新;被修改的原数据放入undo表空间,以供其他查询查看和回滚等。
行迁移,假如更新太大,原块容量不够,新数据迁移至新块,更新的原块包含指向新块的指针。
这里跟PG有个不同点,update的旧数据行理论上可以被复用(原位置复用),undo提供一致性查询和回滚,回滚是逻辑操作,写入新的地址。但行号也就是rowid不变。
截断 (oracle 采用的是表空间-数据文件方式,表存放在数据文件中,truncate时,是修改表头相关信息及更新了字典信息,数据文件中还存在数据,如果没被覆盖,可通过其他方式将数据文件中数据恢复出来)
SQL> select object_name,object_id,data_object_id from
user_objects where object_name='T4';
OBJECT_NAME OBJECT_ID DATA_OBJECT_ID
-------------------- ---------- --------------
T4 263770 263770
SQL> truncate table t4;
Table truncated.
SQL> select object_name,object_id,data_object_id from
user_objects where object_name='T4';
OBJECT_NAME OBJECT_ID DATA_OBJECT_ID
-------------------- ---------- --------------
T4 263770 263772 --这个id也变了,类似pg,数据库层面物理位置发生变化。复制pg中没有单独的undo,对于表/行的可见性记录在一个单独的文件中,后缀为_VM
如果检索数据都在索引中,可以很高效访问,但由于pg的索引中不记录事务信息,如果我们只访问pg中存储的列,还需要参照可见性那个文件,去检索,如果某page未被标记可见,就需要访问数据块,为了保证一致性。如果表中死元组较多,建议vacuum
postgres=# select relname,relpages,relallvisible from pg_class where relname='t2'; relname | relpages | relallvisible ---------+----------+--------------- t2 | 16386 | 16372 (1 row)
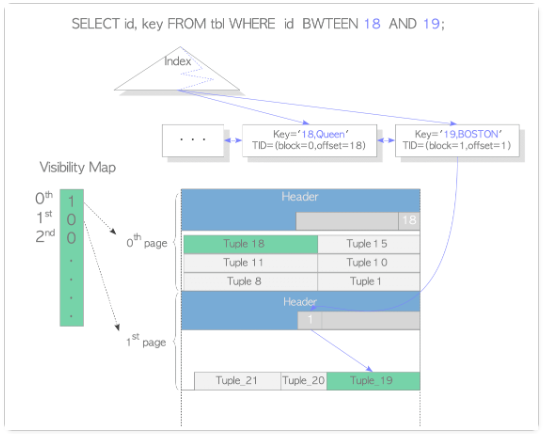
Oracle索引的块头存储事务槽,可以只通过索引扫描提高效率。
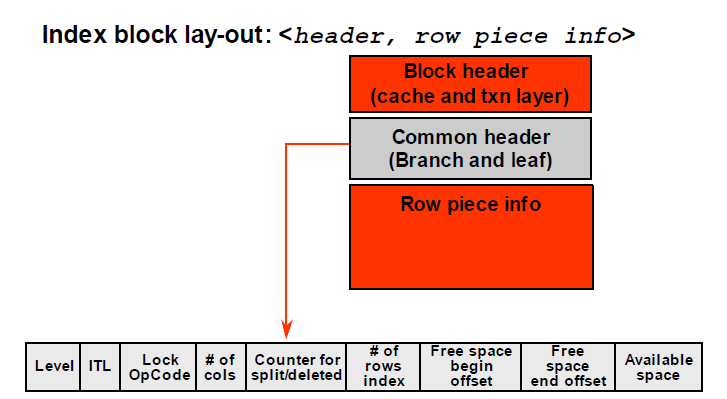
pg提供了 vacuum 和vacuum full 方式收缩表,如果不执行,表膨胀厉害。vacuum主要是清理表中死元组,使空间可复用
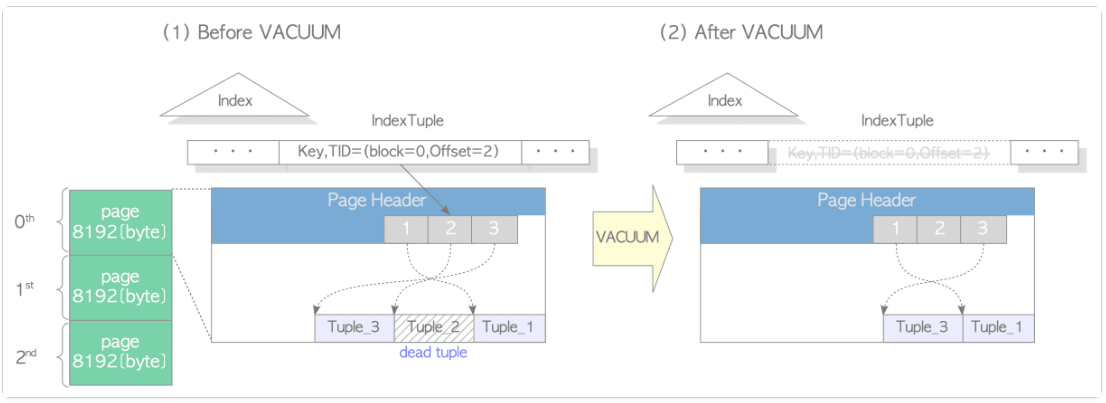
Oracle 中即使不执行收缩,表中被删除的行或者更新的旧数据行都可以被复用,如果执行收缩,会整理、移动行数据,部分rowid会变,索引需要更新。(当然,如果一些碎片无法存放insert或者update的新数据,就无法复用)
Pg中的vacuum full类似 Oracle中的 alter table move 操作,但Oracle move会使索引失效,需要手动重建。
除了整理块(page)中的死元组之类的数据,还会整理行链接、行迁移,Oracle中,update时本块空间无法满足,则造成行迁移。行链接是一行数据量太大,一个块无法存放。
PG数据库中,通过TOAST方式(大于2kb)避免行链接,update更新时,如果本page无法存放,直接迁移至其他行,(HOT方式不支持跨块),索引依然不变,通过ctid 进行链接跳转,执行vacuum之后,索引更新。
也可参考视频:https://www.bilibili.com/video/BV1fg4y1H7FM/?spm_id_from=333.999.0.0
