




2024.03.15修订 因刘老师指出错误对最终的SQL进行了修订
1、问题
今天刷墨天轮的问答,刷到一个优化问题
原问题 SQL 求助,如下sql怎么改写可以快起来
以下为原问题
/tabs表数据量5000w,会持续增长;
time列有索引;
end_time 非空时两行数有联系,end_time d列数值比 start_time 多 1;
where 条件只能基于end_time判断/
SELECT *
FROM (SELECT a,
b,
c,
t.time start_time,
LEAD (t.time, 1, SYSDATE)
OVER (PARTITION BY a, b ORDER BY time) end_time
FROM tabs)
WHERE end_time > = SYSDATE - 8 / 24
ORDER BY 1, 2;
2、复现
原问题是在oracle中的。我不会oracle,我在MySQL中重现它。
我的表行数量与索引如下
mall_message 表 有数据 500W行
我创建了两个索引
KEYidx_profileid_did(profileid,did,createtime),
KEYidx_createtime(createtime)
SELECT *
FROM (SELECT profileid,did,isread,createtime as start_time,
LEAD(createtime, 1,now()) OVER(PARTITION BY profileid, did ORDER BY createtime) as end_time
FROM mall_message
) as t
WHERE end_time >= now() - 8 / 24
ORDER BY 1, 2;
复制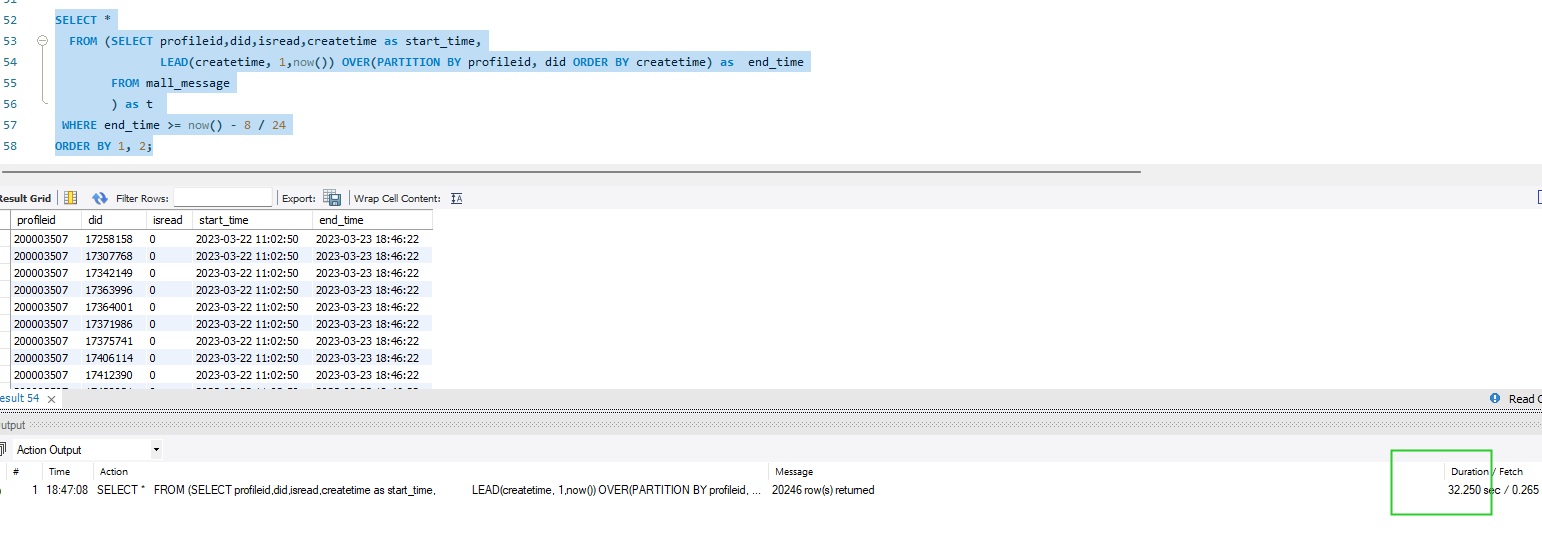
执行时间为32S
3、优化思考
分析上面SQL我们可以获得两条信息
1、每个分组的最后一行是肯定会符合条件的
2、除了每个分组的最后一条外,其它行就可以把外部查询的条件带入到子查询中
第二条如果把外部的过滤条件带入子查询 那么createtime > now() - 8 / 24 将走索引,由于题主说了是历史表。所以外部条件的带入走createtime索引,会带来性能大提升
第一条。我们要利用MySQL的松散扫描来优化
取每个分组的最后一条
explain
select profileid,did,max(createtime) as end_time
from mall_message
group by profileid,did
复制
查看执行计划 extra中 带有 Using index for group-by
MySQL官方的GROUP BY Optimization 文档中有下面一句话。
GROUP BY Optimization官方链接
If Loose Index Scan is applicable to a query, the EXPLAIN output shows Using index for group-by in the Extra column.
把上面两个结果再union all 起来。那么原语句的结果了
4、验证
explain
select a.profileid,a.did,a.createtime,a.isread,now() as end_time from mall_message a
inner join
(
select profileid,did,max(createtime) as end_time
from mall_message
group by profileid,did
) b
on a.profileid = b.profileid and a.did= b.did and a.createtime = b.end_time
union all
select a.profileid,a.did,t.createtime,a.isread,a.createtime from mall_message a
inner join LATERAL(select b.createtime from mall_message b where a.profileid = b.profileid and a.did = b.did and b.createtime <a.createtime order by b.createtime desc limit 1 ) as t
where a.createtime > now() - 8 / 24
复制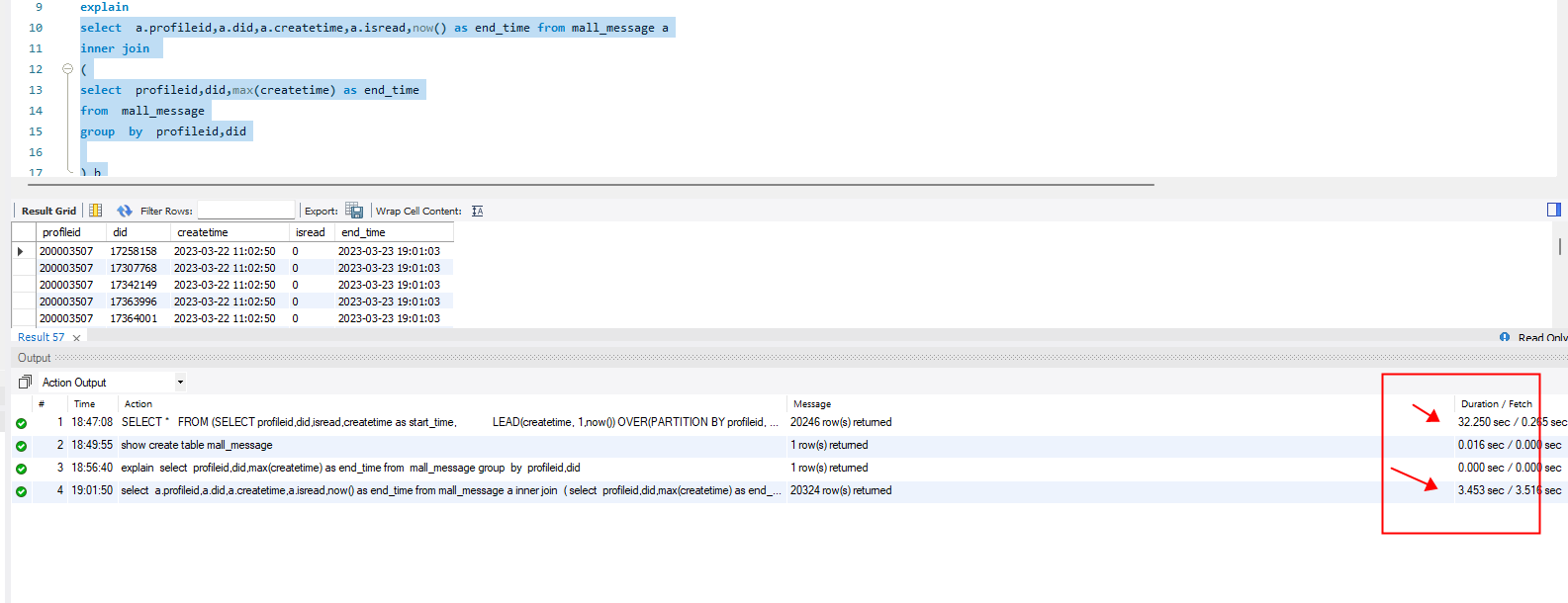
性能从32.25S提升到了3.45S 有9.3倍的性能提升。
随着数据量的增加,提升的倍数还能再扩大
文章被以下合辑收录
评论

 1 1
1 1 1 1 0 点赞
1 1 0 点赞 0 点赞
0 点赞 0 点赞
0 点赞