




一、关于连接
join合并两个行源(如表或视图)的输出,并返回一个行源。返回的行源是数据集。
join的特征是在SQL语句的where(non-ANSI标准)或FROM…JOIN(ANSI)子句中出现多张表。当FROM子句中存在多个表时,Oracle数据库执行连接操作。
连接条件使用表达式比较两个行源。连接条件定义了表之间的关系。如果该语句没有指定连接条件,则数据库执行笛卡尔连接,将一个表中的每一行与另一个表中的每一行进行拼接。
1.连接树
通常,连接树表示为上下倒置的树结构。
如下图所示,table1是左表,table2是右表。优化器从左到右处理连接。例如,如果此图描述了一个嵌套循环连接,那么table1是外部循环,而table2是内部循环。
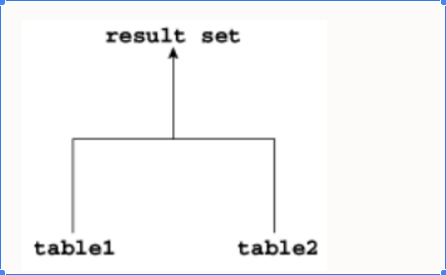
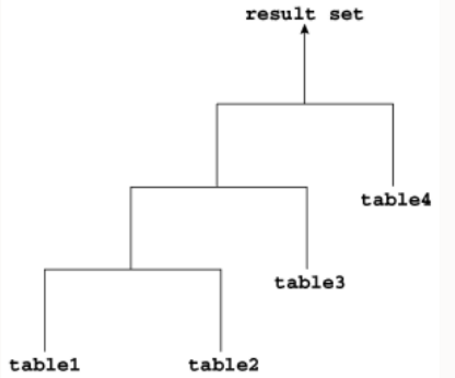
连接的输入可能是前一个连接的结果集。如果连接树的每个内部节点的右子节点是表,那么这个树就是一个左深连接树,如下面的示例所示。大多数连接树都是左深连接。
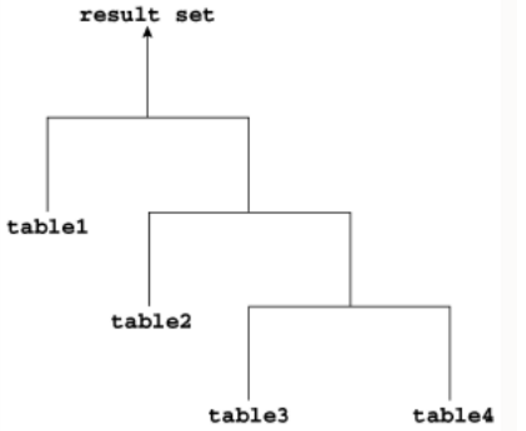
如果连接树的每个内部节点的左子节点是一个表,则该树称为右深连接树,如下图所示。
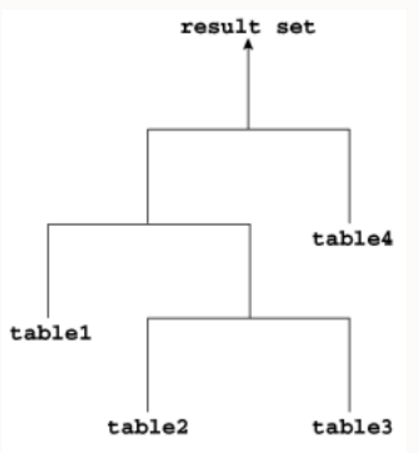
如果连接树的内部节点的左子节点或右子节点可以是连接节点,则该树称为浓密连接树。在下面的示例中,table4是连接节点的右子节点,table1是连接节点的左子节点,而table2是连接节点的左子节点。
2.优化器如何执行连接语句
数据库连接行源对。当FROM子句中存在多个表时,优化器必须为每一个行源对确定哪种连接操作最有效。
优化器必须做出下表中所示的相关决策。
| 操作 | 说明 |
|---|---|
| 访问路径 | 对于简单语句,优化器必须选择一个访问路径来从连接语句中的每个表检索数据。例如,优化器可以在全表扫描或索引扫描之间进行选择。 |
| 连接方法 | 为了连接每一对行源,Oracle数据库必须决定如何做。可能的连接方法有嵌套循环、排序合并和hash连接。每个连接方法都有比其他连接方法更适合的特定情况。 |
| 连接类型 | 连接条件决定连接类型。例如,内部连接只检索符合连接条件的行。而外连接则会检索不符合连接条件的行。 |
| 连接顺序 | 要执行连接两个以上表的语句,Oracle数据库先连接两个表,然后将结果行源连接到下一个表。这个过程一直持续到所有的表都被连接到结果中。 |
3.优化器如何为连接选择执行计划
在确定连接顺序和方法时,优化器的目标是尽早减少行数,以便在整个SQL语句的执行过程中执行更少的工作。
优化器根据可能的连接顺序、连接方法和可用的访问路径生成一组执行计划。然后,优化器估算每个计划的成本,并选择成本最低的计划。在选择执行计划时,优化器会考虑以下因素:
-
优化器首先确定连接两个或多个表是否会产生最多只包含一行的行源。
优化器根据表上的UNIQUE和PRIMARY KEY约束识别这种情况。如果存在这种情况,那么优化器将把这些表放在连接顺序的前面。然后优化器继续优化剩余表集的连接。 -
对于具有外连接条件的连接语句,具有外连接操作符的表通常在连接顺序中位于条件中的其他表之后。
一般来说,优化器不会考虑违反这条准则的连接顺序,尽管在某些情况下优化器会覆盖这种顺序条件。类似地,当子查询被转换为反连接或半连接时,子查询中的表必须位于与它们有关联或相关的外部查询块中的表之后。但是,在某些情况下,hash反连接和半连接能够覆盖此顺序条件。
优化器通过估算的I/O和CPU来估计查询计划的成本。这些I/O操作有特定的成本:一个是单块I/O的成本,另一个是多块I/O的成本。此外,不同的函数和表达式都有与之相关的CPU成本。优化器使用这些指标确定一个查询计划的总成本。在编译时这些指标可能会受到许多初始化参数和会话设置的影响,例如DB_FILE_MULTI_BLOCK_READ_COUNT设置、系统统计信息等等。
例如,优化器通过以下方式估计成本:
- 嵌套循环连接的成本取决于将外部表中每个选定行及其内部表中每个匹配行读入内存的成本。优化器使用数据字典中的统计信息估计这些成本。
- 排序归并连接的成本很大程度上取决于将所有行源读取到内存并排序的成本。
- hash连接的成本在很大程度上取决于在连接的一个输入端构建hash表并使用连接另一端的行来探测hash表的成本。
从概念上讲,优化器会构造了一个连接顺序和方法的矩阵,以及与它们相关的成本。
二、嵌套循环连接
嵌套循环将外部数据集连接到内部数据集。
对于外部数据集中匹配单表谓词的每一行,数据库会检索内部数据集中满足连接谓词的所有行。如果索引可用,则数据库可以使用它按rowid访问内部数据集。
1.优化器在什么时候会考虑嵌套循环连接?
当数据库连接小的数据子集时,当优化器模式设置为FIRST_ROWS,数据库连接大数据集时,或者当连接条件是访问内部表的有效方法时,嵌套循环连接非常有用。
说明:驱动优化器做出决策的是预期连接的行数,而不是底层表的大小。例如,一个查询可能连接两个表,每个表有10亿行,但由于过滤器,优化器认为每个表有5行数据集。
一般来说,嵌套循环连接在连接条件上有索引的小表上工作得最好。如果一个行源只有一行数据,当对主键值进行等值查找(例如,WHERE employee_id=101),则连接是简单查找。优化器总是尝试将最小的行源放在第一位,使其成为驱动表。
有很多因素决定了优化器是否使用嵌套循环。例如,数据库可能从外部行源一次读取几行数据。根据检索到的行数,优化器可以选择对内部行源进行嵌套循环或hash连接。例如,如果某个查询将departments与驱动表employees进行连接,并且如果谓词在employees.last_name中指定了一个值,那么数据库可能会在last_name上的索引中读取足够多的条目,以确定是否超过了一个内部阈值。如果未超过阈值,则优化器会选择嵌套循环连接到departments,如果超过阈值,则数据库执行hash连接,这意味着读取employees剩余部分,对其进行hash运算后放入内存中,然后连接到departments。
如果内循环的访问路径不依赖于外循环,则结果可以是笛卡尔积:对于外部循环的每次迭代,内部循环都会生成相同的行集。
2.嵌套循环连接是如何运作的?
从概念上讲,嵌套循环相当于两个嵌套的for循环。
例如,如果某个查询连接employees和departments,那么可以使用如下伪代码表示嵌套循环:
FOR erow IN (select * from employees where X=Y) LOOP FOR drow IN (select * from departments where erow is matched) LOOP output values from erow and drow END LOOP END LOOP复制
对于外部循环的每一行,内部循环都要被执行。employees表是“外部”数据集,因为它位于外部for循环中。外表有时被称为驱动表。departments表是“内部”数据集,因为它位于内部for循环中。
嵌套循环连接包括以下基本步骤:
(1)优化器确定驱动行源并将其指定为外部循环。
外部循环生成一组行,用于驱动连接条件。行源可以是使用索引扫描、全表扫描或任何其他生成行的操作访问的表。
内部循环的迭代次数取决于外部循环中检索到的行数。例如,如果从外部表中检索到10行数据,则数据库必须在内部表中执行10次查找。如果从外部表中检索到10,000,000行,那么数据库必须在内部表中执行10,000,000次查找。
(2)优化器将另一行源指定为内部循环。
在执行计划中,外循环出现在内循环之前,如下所示:
NESTED LOOPS outer_loop inner_loop复制
(3)对于每个来自客户端的获取请求,基本流程如下:
a、从外部行源中获取一行
b、探测内部行源以查找满足谓词条件的行
c、重复上述步骤,直到获取请求获得所有行
有时,数据库会对rowid进行排序以获得更高效的缓冲区访问模式。
3.嵌套嵌套循环
嵌套循环的外部循环本身可以是由不同的嵌套循环生成的行源。
数据库可以嵌套两个或多个外部循环,以根据需要连接任意多的表。每个循环是一个数据访问方法。下面的样板展示了数据库如何通过三个嵌套循环进行迭代:
SELECT STATEMENT NESTED LOOPS 3 NESTED LOOPS 2 - Row source becomes OUTER LOOP 3.1 NESTED LOOPS 1 - Row source becomes OUTER LOOP 2.1 OUTER LOOP 1.1 INNER LOOP 1.2 INNER LOOP 2.2 INNER LOOP 3.2复制
循环顺序如下:
(1)数据库通过NESTED LOOPS 1进行迭代:
NESTED LOOPS 1 OUTER LOOP 1.1 INNER LOOP 1.2复制
NESTED LOOP 1的输出是一个行源。
(2)数据库通过NESTED LOOPS 2进行迭代,使用NESTED LOOPS 1生成的行源作为其外部循环:
NESTED LOOPS 2 OUTER LOOP 2.1 - Row source generated by NESTED LOOPS 1 INNER LOOP 2.2复制
NESTED LOOPS 2的输出是另一个行源。
(3)数据库通过NESTED LOOPS 3进行迭代,使用NESTED LOOPS 2生成的行源作为其外部循环:
NESTED LOOPS 3 OUTER LOOP 3.1 - Row source generated by NESTED LOOPS 2 INNER LOOP 3.2复制
假设您按照如下方式连接employees和departments表:
SELECT /*+ ORDERED USE_NL(d) */ e.last_name, e.first_name, d.department_name FROM employees e, departments d WHERE e.department_id=d.department_id AND e.last_name like 'A%';复制
该计划显示优化器选择了两个嵌套循环(步骤1和步骤2)来访问数据:
SQL_ID ahuavfcv4tnz4, child number 0 ------------------------------------- SELECT /*+ ORDERED USE_NL(d) */ e.last_name, d.department_name FROM employees e, departments d WHERE e.department_id=d.department_id AND e.last_name like 'A%' Plan hash value: 1667998133 ---------------------------------------------------------------------------------- |Id| Operation |Name |Rows|Bytes|Cost(%CPU)|Time| ---------------------------------------------------------------------------------- | 0| SELECT STATEMENT | | | |5 (100)| | | 1| NESTED LOOPS | | | | | | | 2| NESTED LOOPS | | 3|102|5 (0)|00:00:01| | 3| TABLE ACCESS BY INDEX ROWID BATCHED| EMPLOYEES | 3| 54|2 (0)|00:00:01| |*4| INDEX RANGE SCAN | EMP_NAME_IX | 3| |1 (0)|00:00:01| |*5| INDEX UNIQUE SCAN | DEPT_ID_PK | 1| |0 (0)| | | 6| TABLE ACCESS BY INDEX ROWID | DEPARTMENTS | 1| 16|1 (0)|00:00:01| ---------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 4 - access("E"."LAST_NAME" LIKE 'A%') filter("E"."LAST_NAME" LIKE 'A%') 5 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")复制
在本例中,基本流程如下:
(1)数据库开始通过内部嵌套循环迭代(步骤2),如下所示:
a、数据库在emp_name_ix中搜索所有姓氏以A开头的rowid(步骤4)。例如:
Abel,employees_rowid Ande,employees_rowid复制
b、使用上一步中的rowid,数据库从employees表中检索一批行(第3步)。例如:
Abel,Ellen,80 Abel,John,50复制
这些行成为最内层嵌套循环的外部行源。
批处理步骤通常是自适应执行计划的一部分。为了确定嵌套循环是否比hash连接更好,优化器需要确定从行源返回的行数。如果返回的行数太多,那么优化器将切换到不同的连接方法。
c、对于外部行源中的每一行,数据库扫描dept_id_pk索引,获取匹配的部门ID所在departments表中的rowid(步骤5),并将其连接到employees行上。例如:
Abel,Ellen,80,departments_rowid Ande,Sundar,80,departments_rowid复制
这些行成为外部嵌套循环的外部行源(步骤1)。
(2)数据库在外层嵌套循环中迭代如下:
a、数据库读取外部行源中的第一行。例如:
Abel,Ellen,80,departments_rowid复制
b、数据库使用departments rowid从departments中检索相应的行(步骤6),然后连接改结果以获得请求的值(步骤1),例如:
Abel,Ellen,80,Sales复制
c、数据库读取外部行源中的下一行,使用departments rowid从departments中检索对应的行(步骤6),并重复循环直到检索到所有行。
4.嵌套循环连接的当前实现
Oracle数据库11g引入了嵌套循环的新实现,减少了物理I/O的总体延迟。
当索引块或表块不在缓冲区缓存中,且需要它来处理连接时,则需要一次物理I/O。数据库可以批量处理多个物理I/O请求,并使用向量I/O(数组)来处理它们,而不是一次一个。数据库将一个rowid数组发送给操作系统,由操作系统执行读取操作。
作为新实现的一部分,连接行源时可能会在执行计划中出现两个嵌套循环,而在之前的版本中只有一个出现。
探讨如下查询:
SELECT e.first_name, e.last_name, e.salary, d.department_name FROM hr.employees e, hr.departments d WHERE d.department_name IN ('Marketing', 'Sales') AND e.department_id = d.department_id;复制
在当前的实现中,这个查询的执行计划可能如下:
------------------------------------------------------------------------------------- | Id | Operation | Name |Rows|Bytes|Cost%CPU| Time | ------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 19 | 722 | 3 (0)|00:00:01| | 1 | NESTED LOOPS | | | | | | | 2 | NESTED LOOPS | | 19 | 722 | 3 (0)|00:00:01| |* 3 | TABLE ACCESS FULL | DEPARTMENTS | 2 | 32 | 2 (0)|00:00:01| |* 4 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 10 | | 0 (0)|00:00:01| | 5 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 10 | 220 | 1 (0)|00:00:01| ------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - filter("D"."DEPARTMENT_NAME"='Marketing' OR "D"."DEPARTMENT_NAME"='Sales') 4 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")复制
在本例中,hr.departments表中的行构成了内部嵌套循环(步骤2)的外部行源(步骤3)。索引emp_department_ix是内部嵌套循环的内部行源(步骤4)。内部嵌套循环的结果构成外部嵌套循环(步骤1)的内部行源(步骤2)。
对于每次获取请求,基本流程如下:
(1)数据库通过内部嵌套循环(步骤2)迭代获取要请求的行:
a、数据库读取departments的第一行,获取名为Marketing或Sales的department_id(步骤3)。例如:
Marketing,20复制
这个行集是外循环。数据库将这些数据缓存到PGA中。
b、数据库扫描emp_department_ix,它是employees表上的一个索引,以查找与这个department_id相对应的employees rowid(步骤4),然后连接该结果(步骤2)。结果集的形式如下:
Marketing,20,employees_rowid Marketing,20,employees_rowid Marketing,20,employees_rowid复制
c、数据库读取departments中的下一行,扫描emp_department_ix找到与该部门ID相对应的employees rowid,然后重复循环,直到满足客户端请求。
在这个例子中,数据库只对外循环进行两次迭代,因为departments表中只有两行数据满足谓词过滤器。
这些行成为外部嵌套循环的外部行源(步骤1)。该行集缓存在PGA中。
(2)数据库会对上一步获得的rowid进行组织,以便更有效地在缓存中访问它们。
(3)数据库开始通过外层嵌套循环迭代,如下所示:
a、数据库从上一步获得的行集中检索第一行,如下例所示:
Marketing,20,employees_rowid复制
b、使用rowid,数据库从employees中检索一行,以获得请求的值(步骤1)。例如:
Michael,Hartstein,13000,Marketing复制
c、数据库从行集中检索下一行,使用rowid探测employees以获取与之匹配的行,然后重复循环,直到所有行被检索。
在某些情况下,没有分配第二个连接行源,并且执行计划看起来与Oracle Database 11g之前的执行计划相同。下面的列表描述了这些情况:
- 连接内部所需的所有列都出现在索引中,并且不需要访问表。在这种情况下,Oracle数据库只分配一个连接行源。
- 返回的行顺序可能与Oracle Database 12c之前版本中的返回顺序不同。因此,当Oracle数据库试图维护特定的行顺序时,例如,为了消除ORDER BY排序的需要,Oracle数据库可能会使用嵌套循环连接的原始实现。
- 初始化参数OPTIMIZER_FEATURES_ENABLE设置为Oracle数据库11g之前的版本。在这种情况下,Oracle数据库使用嵌套循环连接的原始实现。
5.嵌套循环连接的原始实现
针对同一个SQL语句,在Oracle 11g之前的版本中,这个查询的执行计划可能如下所示:
------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes |Cost (%CPU)|Time | ------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 19 | 722 | 3 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 10 | 220 | 1 (0)| 00:00:01 | | 2 | NESTED LOOPS | | 19 | 722 | 3 (0)| 00:00:01 | |* 3 | TABLE ACCESS FULL | DEPARTMENTS | 2 | 32 | 2 (0)| 00:00:01 | |* 4 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 10 | | 0 (0)| 00:00:01 | ------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - filter("D"."DEPARTMENT_NAME"='Marketing' OR "D"."DEPARTMENT_NAME"='Sales') 4 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")复制
对于每个获取(fetch)请求,基本流程如下:
(1)数据库通过重复循环来获取fetch中请求的行:
a、数据库读取departments表的第一行,以获取名为Marketing或Sales的部门的department_id(步骤3)。例如:
Marketing,20复制
这个行集是外部循环。数据库在PGA中缓存该行。
b、数据库扫描emp_department_ix,这是employees.department_id列上的索引,以查找与上述department_id对应的employees表的rowid(步骤4),然后连接该rowid(步骤2)。例如:
Marketing,20,employees_rowid Marketing,20,employees_rowid Marketing,20,employees_rowid复制
c、数据库继续读取departments表的下一行,然后扫描emp_department_ix以查找与该department_id对应的employees表的rowid,并遍历循环,直到客户端请求得到满足。
(2)根据具体情况,数据库可能会组织在前一步中获得的缓存rowid,以便能够更有效地访问它们。
(3)对于嵌套循环产生的结果集中的每个employees的rowid,数据库会从employees中检索一行以获得请求的值(步骤1)。
因此,基本处理流程是读取rowid并检索匹配的employees行,读取下一个rowid并检索匹配的employees行,以此类推。
6.嵌套循环的控制
您可以添加USE_NL提示,以指示优化器使用嵌套循环连接将每个指定表连接到另一个行源,并使用指定表作为内部表。
相关的提示USE_NL_WITH_INDEX(table index)指示优化器将指定的表连接到另一个行源,使用指定的表作为内部表进行嵌套循环连接。索引是可选的。如果未指定索引,则嵌套循环连接使用至少具有一个连接谓词的索引作为索引键。
假设优化器为以下查询选择了一个hash连接:
SELECT e.last_name, d.department_name FROM employees e, departments d WHERE e.department_id=d.department_id;复制
执行计划看起来像下面这样:
--------------------------------------------------------------------------- |Id | Operation | Name | Rows| Bytes |Cost(%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 5 (100)| | |*1 | HASH JOIN | | 106 | 2862 | 5 (20)| 00:00:01 | | 2 | TABLE ACCESS FULL| DEPARTMENTS | 27 | 432 | 2 (0)| 00:00:01 | | 3 | TABLE ACCESS FULL| EMPLOYEES | 107 | 1177 | 2 (0)| 00:00:01 | ---------------------------------------------------------------------------复制
要使用departments作为内部表强制进行嵌套循环连接,可以添加USE_NL提示,如下所示:
SELECT /*+ ORDERED USE_NL(d) */ e.last_name, d.department_name FROM employees e, departments d WHERE e.department_id=d.department_id;复制
执行计划看起来像下面这样:
--------------------------------------------------------------------------- | Id | Operation | Name | Rows |Bytes |Cost (%CPU)|Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 34 (100)| | | 1 | NESTED LOOPS | | 106 | 2862 | 34 (3)| 00:00:01 | | 2 | TABLE ACCESS FULL| EMPLOYEES | 107 | 1177 | 2 (0)| 00:00:01 | |* 3 | TABLE ACCESS FULL| DEPARTMENTS | 1 | 16 | 0 (0)| | --------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - filter("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")复制
数据库获取结果集的步骤如下:
(1)在嵌套循环中,数据库读取employees表以获取员工的last_name和department_id(步骤2)。例如:
De Haan,90复制
(2)对于上一步获得的行,数据库扫描departments以查找与员工department_id匹配的department_name(步骤3),并连接该结果(步骤1)。例如:
De Haan,Executive复制
(3)数据库检索employees中的下一行,然后检索departments中的匹配行,重复此过程,直到检索到所有行。
详细信息请参考:https://docs.oracle.com/en/database/oracle/oracle-database/19/tgsql/joins.html
