





阅读本条漫需要5分钟,Spark实时计算,得Shuufle者得天下!
1 、以数据之名 简介
微信公众号、今日头条知乎和稀土掘金,主体均为“以数据之名”; 欢迎扫码关注,回复「666」加入“以数据之名”微信交流群; 本文主要为如何基于Spark Push Shuffle Service,做到存算分离、计算稳定和高效性能。

2 、背景概要
针对Spark的实时计算项目,都不得不面临以下3个问题:
如何保证Spark作业的运行稳定问题?
如何提升Spark作业的计算性能问题?
如何实施Spark作业存算分离架构?
要解决上述三个问题,就必须要解决Shuffle问题。那么什么是Shuffle呢?
2.1 Shuffle 是什么
Shuffle是大数据计算中最为重要的算子。
首先,覆盖率高,超过50%的作业都包含至少一个Shuffle。
其次,资源消耗大,阿里内部平台Shuffle的CPU占比超过20%,LinkedIn内部Shuffle Read导致的资源浪费高达15%,单Shuffle数据量超100T。
最后,不稳定,硬件资源的稳定性CPU>内存>磁盘≈网络,而Shuffle的资源消耗是倒序。OutOfMemory和Fetch Failure可能是Spark作业最常见的两种错误,前者可以通过调参解决,而后者需要系统性重构Shuffle。
2.2 Shuffle 传统架构
Mapper把Shuffle数据按PartitionId排序写盘后交给External Shuffle Service(ESS)管理,Reducer从每个Mapper Output中读取属于自己的Block。
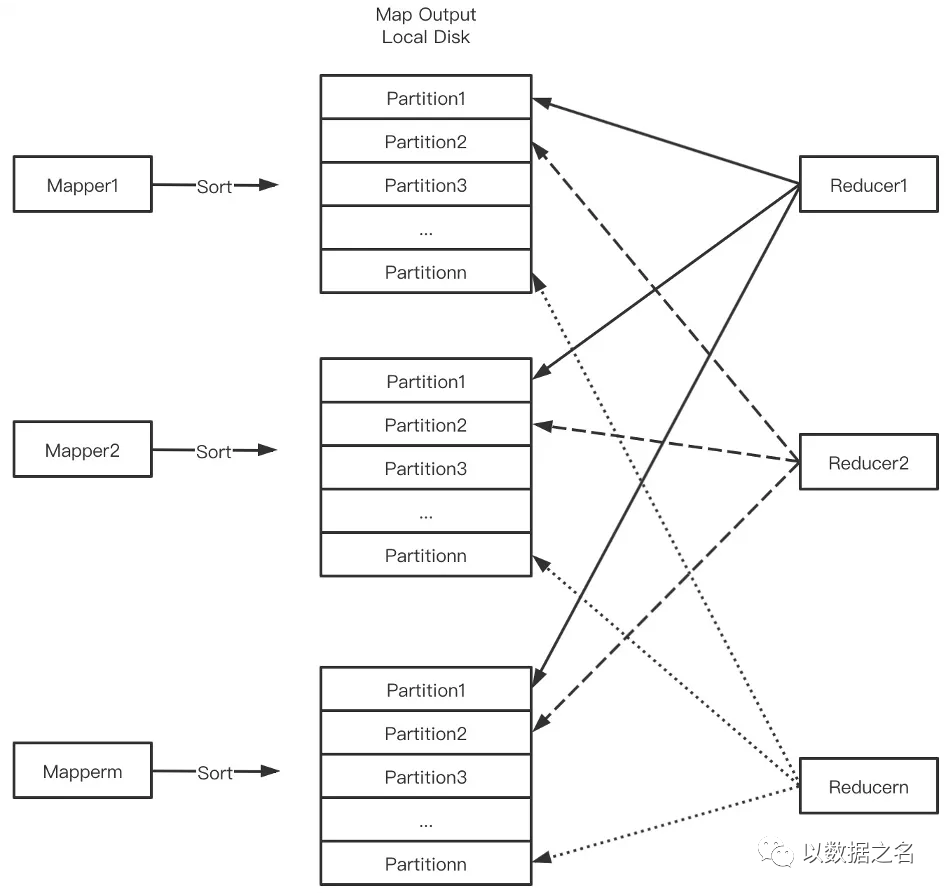
2.3 Shuffle 传统架构问题
传统的Shuffle架构存在一些问题,具体如下:
本地盘依赖限制了存算分离。存算分离是近年来兴起的新型架构,它解耦了计算和存储,可以更灵活地做机型设计:计算节点强CPU弱磁盘,存储节点强磁盘强网络弱CPU。计算节点无状态,可根据负载弹性伸缩。存储端,随着对象存储(OSS、S3)+数据湖格式(Hudi、Iceberg、Delta)+本地/近地缓存等方案的成熟,可当作容量无限的存储服务。用户通过计算弹性+存储按量付费获得成本节约。然而,Shuffle对本地盘的依赖限制了存算分离。
写放大。当Mapper Output数据量超过内存时触发外排,从而引入额外磁盘IO。
大量随机读。Mapper Output属于某个Reducer的数据量很小,如Output 128M,Reducer并发2000,则每个Reducer只读64K,从而导致大量小粒度随机读。对于HDD,随机读性能极差;对于SSD,会快速消耗SSD寿命。
高网络连接数,导致线程池消耗过多CPU,带来性能和稳定性问题。
Shuffle数据单副本,大规模集群场景坏盘/坏节点很普遍,Shuffle数据丢失引发的Stage重算带来性能和稳定性问题。
3 、阿里云RSS
Aliyun Remote Shuffle Service(RSS)致力于提高不同map-reduce引擎的效率和弹性。RSS 为 shuffle 数据提供了一种弹性、高效的管理服务。
3.1 技术架构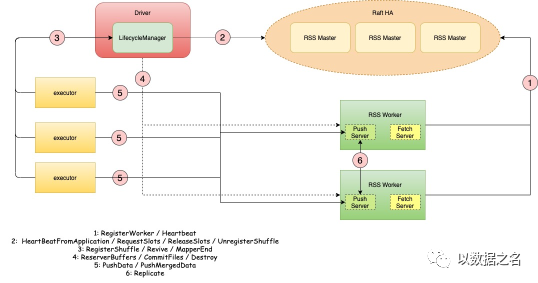
RSS 具有三个主要组件:Master、Worker 和 Client。Master 管理所有资源,并基于 Raft 相互同步分片状态。Worker 处理读写请求并为每个 reducer 合并数据。LifecycleManager 维护每个 shuffle 的元数据并在 Spark 驱动程序中运行。
3.2 技术特征
分解计算和存储。
基于推送的随机写入和合并随机读取。
高可用性和高容错性。
3.3 Shuffle 过程
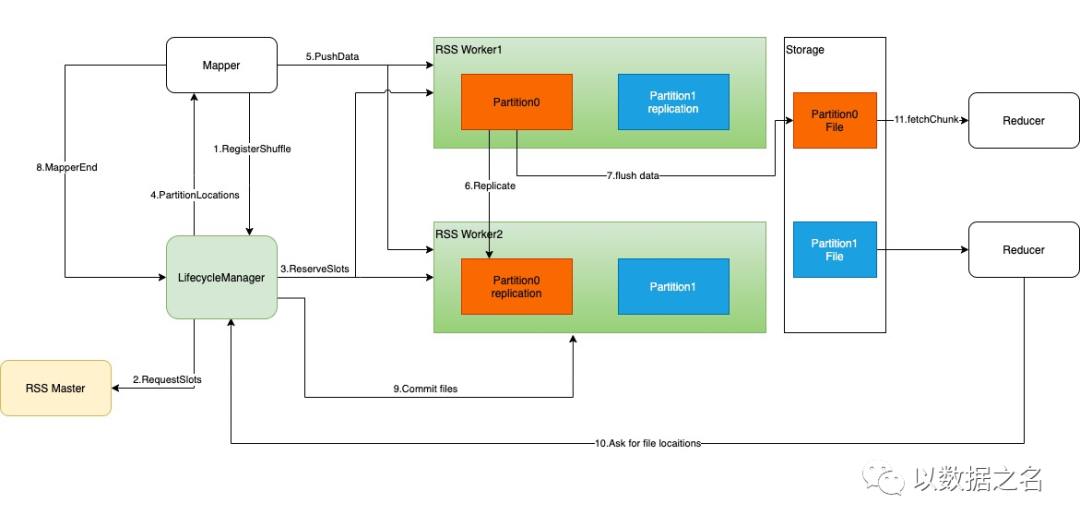
Mappers 懒惰地要求 LifecycleManager 注册 Shuffle。
LifecycleManager 向 Master 请求插槽。
工人保留槽并创建相应的文件。
映射器从 LifecycleManager 获取工作人员位置。
映射器将数据推送到指定的工作人员。
工作人员将数据合并并复制到其对等方。
工作人员定期刷新到磁盘。
Mapper 任务完成并触发 MapperEnd 事件。
当所有映射器任务完成后,工作人员提交文件。
减速器要求文件位置。
Reducers 读取 shuffle 数据。
3.4 负债均衡
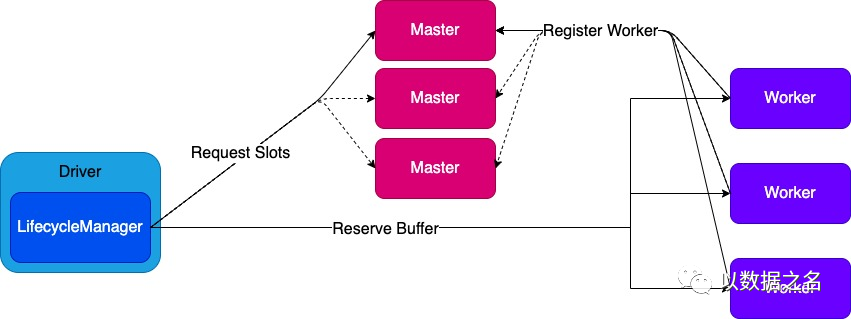
我们引入槽来实现负载均衡Load Balance。我们将通过跟踪插槽使用情况在每个 RSS 工作人员上平均分配分区。Slot 是 RSS Worker 中的一个逻辑概念,表示每个 RSS Worker 上可以分配多少个分区。RSS Worker 的槽数由rss.worker.numSlots 或 rss.worker.flush.queue.capacity * (number of RSS Worker storage directories) 决定rss.worker.numSlots。分配分区时 RSS 工作器的插槽计数会减少,而释放分区时会增加。
3.5 构建部署
RSS支持Spark2.x(>=2.4.0)、Spark3.x(>=3.0.1),只在Java8(JDK1.8)下测试。
1、为 Spark 2 构建./dev/make-distribution.sh -Pspark-22、为 Spark 3 构建./dev/make-distribution.sh -Pspark-3将生成包 rss-${project.version}-bin-release.tgz。复制
3.6 项目源码
源码地址
https://github.com/alibaba/RemoteShuffleService
包详情
构建过程将创建一个压缩包。
├── RELEASE
├── bin
├── conf
├── master-jars
├── worker-jars
├── sbin
└── spark
//Spark client jars复制
兼容性
RSS 服务器兼容 Spark2 和 Spark3。您可以使用同一个 RSS 服务器同时运行 Spark2 和 Spark3。RSS 服务器是用 -Pspark-2 还是 -Pspark-3 编译的都没有关系。但是,RSS 客户端必须与 Spark 的版本保持一致。也就是说,如果你运行的是Spark2,你必须用-Pspark-2编译RSS客户端;如果您正在运行 Spark3,则必须使用 -Pspark-3 编译 RSS 客户端。
3.7 实战部署
RSS 支持 HA 模式部署。
部署 RSS
解压包到$RSS_HOME
修改 $RSS_HOME/conf/rss-env.sh 中的环境变量
#!/usr/bin/env bash
RSS_MASTER_MEMORY=4g
RSS_WORKER_MEMORY=2g
RSS_WORKER_OFFHEAP_MEMORY=4g复制
修改 $RSS_HOME/conf/rss-defaults.conf 中的配置
示例:单主集群
rss.master.address master-host:port
rss.metrics.system.enable true
rss.worker.flush.buffer.size 256k
rss.worker.flush.queue.capacity 512
rss.worker.base.dirs mnt/disk1/,/mnt/disk2复制
示例:HA 集群
rss.metrics.system.enable true
rss.worker.flush.buffer.size 256k
rss.worker.flush.queue.capacity 4096
rss.worker.base.dirs mnt/disk1/,/mnt/disk2
rss.master.port 9097
rss.ha.enable true
rss.ha.service.id dev-cluster
rss.ha.nodes.dev-cluster node1,node2,node3
rss.ha.address.dev-cluster.node1 host1
rss.ha.address.dev-cluster.node2 host2
rss.ha.address.dev-cluster.node3 host3
rss.ha.storage.dir mnt/disk1/rss_ratis/
rss.ha.master.hosts host1,host2,host3复制
将 RSS 和配置复制到所有节点
启动 RSS 大师 $RSS_HOME/sbin/start-master.sh
启动 RSS 工作者 $RSS_HOME/sbin/start-worker.sh
如果 RSS 启动成功,Master 的日志输出应该是这样的:
21/12/21 20:06:18,964 INFO [main] Dispatcher: Dispatcher numThreads: 64
21/12/21 20:06:18,994 INFO [main] TransportClientFactory: mode NIO threads 8
21/12/21 20:06:19,113 WARN [main] ServerBootstrap: Unknown channel option 'TCP_NODELAY' for channel '[id: 0x8a9442f6]'
21/12/21 20:06:19,129 INFO [main] Utils: Successfully started service 'MasterSys' on port 9097.
21/12/21 20:06:19,150 INFO [main] HttpServer: HttpServer started on port 7001.
21/12/21 20:06:21,615 INFO [netty-rpc-connection-0] TransportClientFactory: Successfully created connection to 172.16.159.100:40115 after 4 ms (0 ms spent in bootstraps)
21/12/21 20:06:21,661 INFO [dispatcher-event-loop-9] Master: Registered worker
Host: 172.16.159.100
RpcPort: 40115
PushPort: 35489
FetchPort: 35689
TotalSlots: 4096
SlotsUsed: 0
SlotsAvailable: 4096
LastHeartBeat: 0
WorkerRef: NettyRpcEndpointRef(ess://WorkerEndpoint@172.16.159.100:40115)
.
21/12/21 20:06:23,785 INFO [netty-rpc-connection-1] TransportClientFactory: Successfully created connection to 172.16.159.98:39151 after 1 ms (0 ms spent in bootstraps)
21/12/21 20:06:23,817 INFO [dispatcher-event-loop-17] Master: Registered worker
Host: 172.16.159.98
RpcPort: 39151
PushPort: 40193
FetchPort: 37455
TotalSlots: 4096
SlotsUsed: 0
SlotsAvailable: 4096
LastHeartBeat: 0
WorkerRef: NettyRpcEndpointRef(ess://WorkerEndpoint@172.16.159.98:39151)
.
21/12/21 20:06:25,948 INFO [netty-rpc-connection-2] TransportClientFactory: Successfully created connection to 172.16.159.99:41955 after 1 ms (0 ms spent in bootstraps)
21/12/21 20:06:26,009 INFO [dispatcher-event-loop-25] Master: Registered worker
Host: 172.16.159.99
RpcPort: 41955
PushPort: 37587
FetchPort: 46865
TotalSlots: 4096
SlotsUsed: 0
SlotsAvailable: 4096
LastHeartBeat: 0
WorkerRef: NettyRpcEndpointRef(ess://WorkerEndpoint@172.16.159.99:41955)复制
部署 Spark 客户端
将 $RSS_HOME/spark/*.jar 复制到 $SPARK_HOME/jars/复制
Spark 配置
要使用 RSS,应添加以下 spark 配置。
spark.shuffle.manager org.apache.spark.shuffle.rss.RssShuffleManager
# must use kryo serializer because java serializer do not support relocation
spark.serializer org.apache.spark.serializer.KryoSerializer
# if you are running HA cluster ,set spark.rss.master.address to any RSS master
spark.rss.master.address rss-master-host:9097
spark.shuffle.service.enabled false
# optional:hash,sort
spark.rss.shuffle.writer.mode hash
# we recommend set spark.rss.push.data.replicate to true to enable server-side data replication
spark.rss.push.data.replicate true
# Note: RSS didn`t support Spark AQE now, but we`ll support it soon.
spark.sql.adaptive.enabled false
spark.sql.adaptive.localShuffleReader.enabled false
spark.sql.adaptive.skewJoin.enabled false复制
最佳实践
如果你想建立一个生产就绪的 RSS 集群,你的集群应该至少有 3 个 master 和至少 4 个 worker。Masters和works可以部署在同一个节点上,但不能在同一个节点上部署多个masters或workers。在配置中查看更多详细信息
支持 Spark 动态分配
我们提供了一个补丁,使用户能够通过动态分配和远程随机播放服务来使用 Spark。对于 Spark2.x 检查Spark2 Patch。
对于 Spark3.x,设置spark.dynamicAllocation.shuffleTracking.enabled=true.
5 、腾讯Firestorm
Firestorm是一种远程Shuffle服务,它为Apache Spark应用程序提供了在远程服务器上存储Shuffle数据的功能。
5.1 技术架构
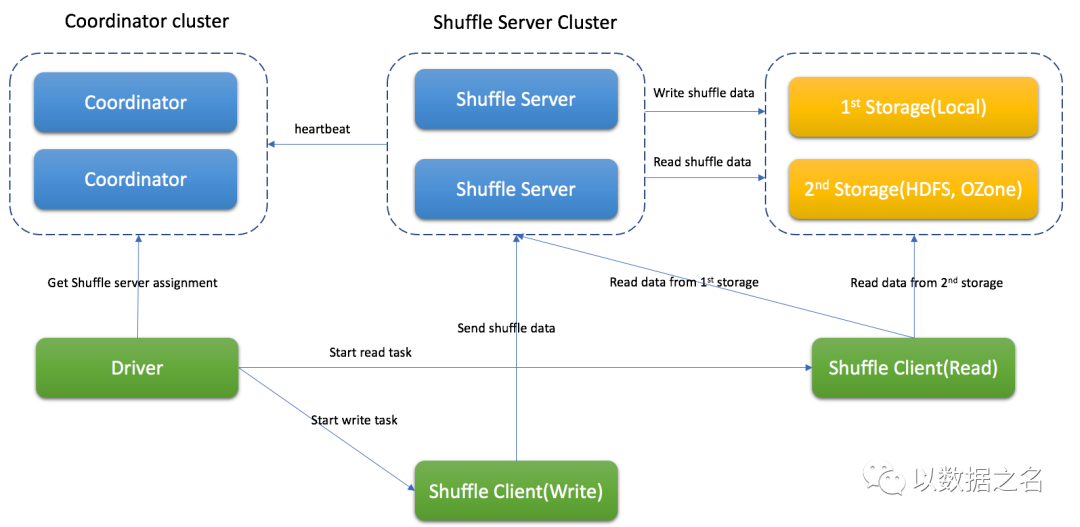
Firestorm包含协调器群集、Shuffle服务器群集和远程存储 (如HDFS) 。协调员将收集Shuffle服务器的状态并完成工作分配。
Shuffle服务器将接收Shuffle数据,将它们合并并写入存储。根据不同情况,Firestorm可以支持内存和本地、内存和远程存储 (例如HDFS) 、仅本地、仅远程存储。
5.2 Shuffle 过程
Spark driver ask coordinator to get shuffle server for shuffle process
Spark task write shuffle data to shuffle server with following step:
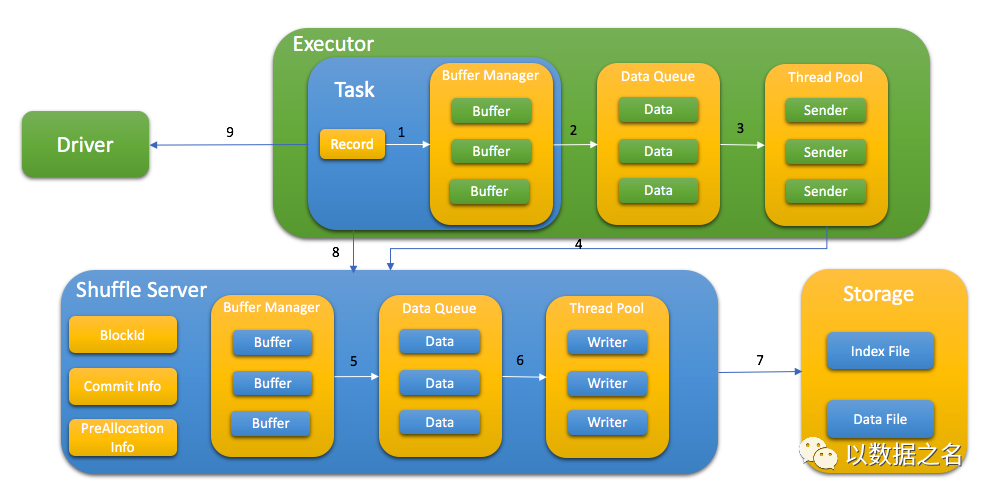
Send KV data to buffer
Flush buffer to queue when buffer is full or buffer manager is full
Thread pool get data from queue
Request memory from shuffle server first and send the shuffle data
Shuffle server cache data in memory first and flush to queue when buffer manager is full
Thread pool get data from queue
Write data to storage with index file and data file
After write data, task report all blockId to shuffle server, this step is used for data validation later
Store taskAttemptId in MapStatus to support Spark speculation
Depend on different storage type, spark task read shuffle data from shuffle server or remote storage or both of them.
5.3 Shuffle 文件格式
The shuffle data is stored with index file and data file. Data file has all blocks for specific partition and index file has metadata for every block.

5.4 Spark 支持版本
Current support Spark 2.3.x, Spark 2.4.x, Spark3.0.x, Spark 3.1.x
Note: To support dynamic allocation, the patch(which is included in client-spark/patch folder) should be applied to Spark
5.5 Firestorm 构建
Firestorm is built using Apache Maven. To build it, run:
mvn -DskipTests clean package复制
To package the Firestorm, run:
./build_distribution.sh复制
rss-xxx.tgz will be generated for deployment
5.6 Firestorm 部署
Deploy Coordinator
unzip package to RSS_HOME
update RSS_HOME/bin/rss-env.sh, eg,
JAVA_HOME=<java_home>
HADOOP_HOME=<hadoop home>
XMX_SIZE="16g"复制
update RSS_HOME/conf/coordinator.conf, eg,
rss.rpc.server.port 19999
rss.jetty.http.port 19998
rss.coordinator.server.heartbeat.timeout 30000
rss.coordinator.app.expired 60000
rss.coordinator.shuffle.nodes.max 5
rss.coordinator.exclude.nodes.file.path RSS_HOME/conf/exclude_nodes复制
start Coordinator
bash RSS_HOME/bin/start-coordnator.sh复制
Deploy Shuffle Server
unzip package to RSS_HOME
update RSS_HOME/bin/rss-env.sh, eg,
JAVA_HOME=<java_home>
HADOOP_HOME=<hadoop home>
XMX_SIZE="80g"复制
update RSS_HOME/conf/server.conf, the following demo is for memory + local storage only, eg,
rss.rpc.server.port 19999
rss.jetty.http.port 19998
rss.rpc.executor.size 2000
rss.storage.type MEMORY_LOCALFILE
rss.coordinator.quorum <coordinatorIp1>:19999,<coordinatorIp2>:19999
rss.storage.basePath data1/rssdata,/data2/rssdata....
rss.server.flush.thread.alive 5
rss.server.flush.threadPool.size 10
rss.server.buffer.capacity 40g
rss.server.read.buffer.capacity 20g
rss.server.heartbeat.timeout 60000
rss.server.heartbeat.interval 10000
rss.rpc.message.max.size 1073741824
rss.server.preAllocation.expired 120000
rss.server.commit.timeout 600000
rss.server.app.expired.withoutHeartbeat 120000复制
start Shuffle Server
bash RSS_HOME/bin/start-shuffle-server.sh复制
Deploy Spark Client
Add client jar to Spark classpath, eg, SPARK_HOME/jars/
The jar for Spark2 is located in <RSS_HOME>/jars/client/spark2/rss-client-XXXXX-shaded.jar
The jar for Spark3 is located in <RSS_HOME>/jars/client/spark3/rss-client-XXXXX-shaded.jar
Update Spark conf to enable Firestorm, the following demo is for local storage only, eg,
spark.shuffle.manager org.apache.spark.shuffle.RssShuffleManager
spark.rss.coordinator.quorum <coordinatorIp1>:19999,<coordinatorIp2>:19999
spark.rss.storage.type MEMORY_LOCALFILE复制
Support Spark dynamic allocation
To support spark dynamic allocation with Firestorm, spark code should be updated. There are 2 patches for spark-2.4.6 and spark-3.1.2 in spark-patches folder for reference.
After apply the patch and rebuild spark, add following configuration in spark conf to enable dynamic allocation:
spark.shuffle.service.enabled false spark.dynamicAllocation.enabled true复制
5.7 Firestorm 配置
The important configuration is listed as following.
Coordinator 参数配置
属性名 | 默认值 | 描述 |
rss.coordinator.server.heartbeat.timeout | 30000 | Timeout if can't get heartbeat from shuffle server |
rss.coordinator.assignment.strategy | BASIC | Strategy for assigning shuffle server, only BASIC support |
rss.coordinator.app.expired | 60000 | Application expired time (ms), the heartbeat interval should be less than it |
rss.coordinator.shuffle.nodes.max | 9 | The max number of shuffle server when do the assignment |
rss.coordinator.exclude.nodes.file.path | - | The path of configuration file which have exclude nodes |
rss.coordinator.exclude.nodes.check.interval.ms | 60000 | Update interval (ms) for exclude nodes |
rss.rpc.server.port | - | RPC port for coordinator |
rss.jetty.http.port | - | Http port for coordinator |
Shuffle Server 参数配置
属性名 | 默认值 | 描述 |
rss.coordinator.quorum | - | Coordinator quorum |
rss.rpc.server.port | - | RPC port for Shuffle server |
rss.jetty.http.port | - | Http port for Shuffle server |
rss.server.buffer.capacity | - | Max memory of buffer manager for shuffle server |
rss.server.memory.shuffle.highWaterMark.percentage | 75.0 | Threshold of spill data to storage, percentage of rss.server.buffer.capacity |
rss.server.memory.shuffle.lowWaterMark.percentage | 25.0 | Threshold of keep data in memory, percentage of rss.server.buffer.capacity |
rss.server.read.buffer.capacity | - | Max size of buffer for reading data |
rss.server.heartbeat.interval | 10000 | Heartbeat interval to Coordinator (ms) |
rss.server.flush.threadPool.size | 10 | Thread pool for flush data to file |
rss.server.commit.timeout | 600000 | Timeout when commit shuffle data (ms) |
rss.storage.type | - | Supports MEMORY_LOCALFILE, MEMORY_HDFS, MEMORY_LOCALFILE_HDFS |
rss.server.flush.cold.storage.threshold.size | 64M | The threshold of data size for LOACALFILE and HDFS if MEMORY_LOCALFILE_HDFS is used |
Spark Client 参数配置
属性名 | 默认值 | 描述 |
spark.rss.writer.buffer.size | 3m | Buffer size for single partition data |
spark.rss.writer.buffer.spill.size | 128m | Buffer size for total partition data |
spark.rss.coordinator.quorum | - | Coordinator quorum |
spark.rss.storage.type | - | Supports MEMORY_LOCAL, MEMORY_HDFS, LOCALFILE, HDFS, LOCALFILE_HDFS |
spark.rss.client.send.size.limit | 16m | The max data size sent to shuffle server |
spark.rss.client.read.buffer.size | 32m | The max data size read from storage |
spark.rss.client.send.threadPool.size | 10 | The thread size for send shuffle data to shuffle server |
5.8 项目源码
项目地址:https://github.com/Tencent/Firestorm
6 、回首岁月
6.1 数据库专题
6.2 Kettle专题
Kettle插件开发之KafkaConsumerAssignPartition篇
6.3 方法论专题
6.4 节日专题
6.1童心未泯,自由翱翔
6.5 数据湖专题
6.6 MQ专题
6.7 缓存专题
6.8 JVM专题
6.9 Python专题
6.10 CDC专题
CDC葵花宝典系列之OGG MySQL For Kafka实战
6.11 Elasticsearch专题
6.12 漏洞修复专题
6.13 数据资产管理专题
小编心声
虽小编一己之力微弱,但读者众星之光璀璨。小编敞开心扉之门,还望倾囊赐教原创之文,期待之心满于胸怀,感激之情溢于言表。一句话,欢迎联系小编投稿您的原创文章!
欢迎关注,欢乐交流,共同成长
