




一、背景介绍
道虽迩,不行不至;事虽小,不为不成。翻滚吧,Kettle;奔涌吧,Kafka。
首先,我们回顾下上面文件“Kettle插件开发之MQToSQL”关于Ogg For Kafka的介绍,Ogg For Kafka作为增量变化捕获CDC的关键环节,负责连续不断地从事务日志捕获到的增量数据并推送到Kafka集群,为我们后续定制业务逻辑异步处理统一了数据源,同时降低了ETL对数据源的侵入性和源与ETL耦合度。
言归正传,既然要探讨如何开发KafkaConsumer的Kettle插件,那么我们必须要首先弄清楚以下几个疑问:
1、如何对Kafka数据进行消费呢?
2、如何做到指定Offset重复消费呢?
3、如何做到故障恢复Failover呢?
4、如何保证消费组件的高性能呢?
二、消费者模型
带着我们Kafka数据消费插件的四连问,我们从消费者模型切入,来循序渐进的揭开消费插件的神秘面纱。
2.1、模型架构图
从如下Kafka消费者模型架构图中,可知从consumer与partition对应关系上可分为分区消费者模型和组消费者模型。
2.2、分区消费者模型
2.2.1、分区消费模型说明
通过分区消费者模型架构图, 可知: 本Kafka集群有3节点Broker Server, 主题TpoicA总共有6个分区, 分区消费者模型就是每个分区和每个消费者实例建立1对1的关系,6个分区就需要启用6个消费者实例, 正如图中所示, 不一定 Consumer1就要对应P0, 它可以对应P1~P5任意一个。
2.2.2、分区消费伪代码描述
main()获取分区的size, 首先得知道topic的分区数是多少for index=0 to size 为每个分区创建一个线程或者进程create thread(or process) consumer(index)第index个线程(进程)consumer(index)创建Kafka broker的连接: KafkaClient(host, port)指定消费参数构建consumer: SimpleConsumer(topic, partitions)设备消费offset: consumer.seek(offset, 0) 每条消息对应一个偏移量, 即kafka的消息是按照偏移量来进行组织, 所以需要初始化起始偏移量。while True消费指定topic第index个分区的数据处理记录当前消息的offset指交当前offset(可选)复制
2.3、组消费模型
2.3.1、组消费模型说明
通过组消费模型架构图, 可知:本Kafka集群有3节点Broker Server, 主题TpoicA总共有6个分区, 有Consumer Group A与Consumer Group B两个组, Consumer Group A里面有Consumer1和Consumer2两个消费线程,每个线程消费3个分区;Consumer Group B里面有 Consumer1到 Consumer6六个消费线程, 每个线程消费1个分区。A,B两个消费者组都能获取当前topicA下面的全量数据。
2.3.2、组消费伪代码描述
main()获取设置创建的流数N(每个consumer组里面有多少个consumer实例)for index=0 to N 为每个分区创建一个线程或者进程create thread(or process) consumer(index)第index个线程(进程)consumer(index)创建Kafka broker的连接: KafkaClient(host, port)指定消费参数构建consumer: SimpleConsumer(topicA, partitions)我们需要消费哪个主题下面的哪个分区, 就要指定哪个主题哪个分区下的哪个偏移量进行消费设置从头消费还是从最新消费(smallest或largest)while True消费指定topic第index个分区的数据处理客户端自动提交offset到zk集群Consumer分配算法:消费者组A有2个Consumer实例, 消费者组B有6个Consumer实例, 集群topicA有6个分区, 具体实例与分区的对应关系由consumer分配算法来确定let N = size(PT)/size(CG)复制
2.4、消费模型的对比分析
2.4.1、消息传递语义
最多一次(at most once):消息可能会丢失,但绝不会被重复发送
至少一次(at least once):消息不会丢失,但有可能被重复发送
精确一次(exactly once):消息不会丢失,也不会被重复发送
Kafka 默认提供的交付可靠性保障是第二种,即至少一次
2.4.2、分区消费模型特点
分区消费模型更加灵活,但是需要自己管理offset(以实现消息传递的其他语义)和处理各种异常情况。
2.4.3、组消费模型特点
组消费模型更加简单, 但是只能实现kafka默认的至少一次消息传递语义。
三、KafkaConsumer插件
第二节探讨了消费者模型,那我们接下来今天的主角“KafkaConsumer插件”,该插件使用的是组消费模型架构来构建主体服务的。本插件支持用户自定义单批次消费超时时间timeout和消费消息行limit组合配置参数,任意参数超过阈值,都将结束当批次数据消费线程。
3.1、KafkaConsumerData
数据类,负责存储元数据对象
复制
public class KafkaConsumerData extends BaseStepData implementsStepDataInterface {ConsumerConnector consumer;//high-level Consumer APIList<KafkaStream<byte[], byte[]>> kafkaStreams;//kafka消息流对象RowMetaInterface outputRowMeta;//输出行元数据RowMetaInterface inputRowMeta;//输入行元数据boolean canceled;//取消标识AtomicInteger processed;//计数器int numThreads;//线程数ExecutorService executor;//执行器}复制
3.2、KafkaConsumerDialog
对话框类,主要负责从UI配置信息读取消费者元配置信息,及自定义配置信息
复制
/*** Copy information from the meta-data input to the dialog fields.*/private void getData(KafkaConsumerMeta consumerMeta, boolean copyStepname) {if (copyStepname) {wStepname.setText(stepname);}wTopicName.setText(Const.NVL(consumerMeta.getTopic(), ""));wFieldName.setText(Const.NVL(consumerMeta.getField(), ""));wKeyFieldName.setText(Const.NVL(consumerMeta.getKeyField(), ""));wPartitionName.setText(Const.NVL(consumerMeta.getPartition(), ""));wOffsetName.setText(Const.NVL(consumerMeta.getOffset(), ""));wOffsetVal.setText(Const.NVL(consumerMeta.getOffsetVal(), ""));wLimit.setText(Const.NVL(consumerMeta.getLimit(), ""));wTimeout.setText(Const.NVL(consumerMeta.getTimeout(), ""));wStopOnEmptyTopic.setSelection(consumerMeta.isStopOnEmptyTopic());TreeSet<String> propNames = new TreeSet<String>();propNames.addAll(Arrays.asList(KafkaConsumerMeta.KAFKA_PROPERTIES_NAMES));propNames.addAll(consumerMeta.getKafkaProperties().stringPropertyNames());Properties kafkaProperties = consumerMeta.getKafkaProperties();int i = 0;for (String propName : propNames) {String value = kafkaProperties.getProperty(propName);TableItem item = new TableItem(wProps.table, i++ > 1 ? SWT.BOLD: SWT.NONE);int colnr = 1;item.setText(colnr++, Const.NVL(propName, ""));String defaultValue = KafkaConsumerMeta.KAFKA_PROPERTIES_DEFAULTS.get(propName);if (defaultValue == null) {defaultValue = "(default)";}item.setText(colnr++, Const.NVL(value, defaultValue));}wProps.removeEmptyRows();wProps.setRowNums();wProps.optWidth(true);wStepname.selectAll();}复制
复制
3.3、KafkaConsumerMeta
元数据类,负责从kettle文件资源库和转换XML序列化元数据信息,生成kafkaProperties对象
复制
public static final String[] KAFKA_PROPERTIES_NAMES = new String[] {"zookeeper.connect", "group.id", "consumer.id","socket.timeout.ms", "socket.receive.buffer.bytes","fetch.message.max.bytes", "auto.commit.interval.ms","queued.max.message.chunks", "rebalance.max.retries","fetch.min.bytes", "fetch.wait.max.ms", "rebalance.backoff.ms","refresh.leader.backoff.ms", "auto.commit.enable","auto.offset.reset", "consumer.timeout.ms", "client.id","zookeeper.session.timeout.ms", "zookeeper.connection.timeout.ms","zookeeper.sync.time.ms" };复制
复制
| Property | Default | Description |
| zookeeper.connect | zk服务端集群地址,根据实际集群配置 | |
group.id | 消费者组ID,自定义唯一ID | |
| consumer.id | 一般采用默认值,自动产生 | |
| socket.timeout.ms | 30*1000 | 一般采用默认值,网络请求的超时限制。真实的超时限制是max.fetch.wait+socket.timeout.ms |
| socket.receive.buffer.bytes | 64*1024 | 一般采用默认值,socket用于接收网络请求的缓存大小 |
| fetch.message.max.bytes | 1024*1024 | 一般采用默认值,每次fetch请求中,针对每次fetch消息的最大字节数。这些字节将会用于每个partition的内存中,因此,此设置将会控制consumer所使用的memory大小。这个fetch请求尺寸必须至少和server允许的最大消息尺寸相等,否则,producer可能发送的消息尺寸大于consumer所能消耗的尺寸。 |
| auto.commit.interval.ms | 60*1000 | 一般采用默认值,consumer向zk提交offset的频率 |
| queued.max.message.chunks | 2 | 一般采用默认值,用于缓存消息的最大数目,以供consumption。每个chunk必须和fetch.message.max.bytes相同 |
| rebalance.max.retries | 4 | 一般采用默认值,当新的consumer加入到consumer group时,consumers集合试图重新平衡分配到每个consumer的partitions数目。如果consumers集合改变了,当分配正在执行时,这个重新平衡会失败并重入 |
| fetch.min.bytes | 1 | 一般采用默认值,每次fetch请求时,server应该返回的最小字节数。如果没有足够的数据返回,请求会等待,直到足够的数据才会返回。 |
| fetch.wait.max.ms | 100 | 一般采用默认值,如果没有足够的数据能够满足fetch.min.bytes,则此项配置是指在应答fetch请求之前,server会阻塞的最大时间。 |
| rebalance.backoff.ms | 2000 | 一般采用默认值,在重试reblance之前backoff时间 |
| refresh.leader.backoff.ms | 200 | 一般采用默认值,在试图确定某个partition的leader是否失去他的leader地位之前,需要等待的backoff时间 |
| auto.commit.enable | true | 如果为真,consumer所fetch的消息的offset将会自动的同步到zk。这项提交的offset将在进程挂掉时,由新的consumer使用 |
| auto.offset.reset | largest | zk中没有初始化的offset时,如果offset是以下值的回应:smallest:自动复位offset为smallest的offset,largest:自动复位offset为largest的offset,anything else:向consumer抛出异常 |
| consumer.timeout.ms | -1 | 如果没有消息可用,即使等待特定的时间之后也没有,则抛出超时异常 |
| exclude.internal.topics | true | 是否将内部topics的消息暴露给consumer |
| paritition.assignment.strategy | range | 选择向consumer 流分配partitions的策略,可选值:range,roundrobin |
| client.id | group id value | 是用户特定的字符串,用来在每次请求中帮助跟踪调用。它应该可以逻辑上确认产生这个请求的应用 |
| zookeeper.session.timeout.ms | 6000 | zk会话的超时限制。如果consumer在这段时间内没有向zk发送心跳信息,则它会被认为挂掉了,并且reblance将会产生 |
| zookeeper.connection.timeout.ms | 6000 | 客户端在建立zk通信连接中的最大等待时间 |
| zookeeper.sync.time.ms | 2000 | zk follower可以落后zk leader的最大时间 |
3.4、KafkaConsumerStep
步骤类,负责处理以下核心数据处理流程:
从源数据类getKafkaPropertiescreate初始化kafka连接配置信息consumerConfig
利用ConsumerConfig,调用Consumer Api方法createJavaConsumerConnector得到ConsumerConnector连接器
初始化Topic信息、每个分区的起始Offset参数
手动提交对应分区的对应offset,使用ConsumerConnector连接器,创建消息流createMessageStreams
根据分区数,动态创建执行线程数
复制
public boolean init(StepMetaInterface smi, StepDataInterface sdi) {super.init(smi, sdi);KafkaConsumerMeta meta = (KafkaConsumerMeta) smi;KafkaConsumerData data = (KafkaConsumerData) sdi;Properties properties = meta.getKafkaProperties();Properties substProperties = new Properties();for (Entry<Object, Object> e : properties.entrySet()) {substProperties.put(e.getKey(), environmentSubstitute(e.getValue().toString()));}if (meta.isStopOnEmptyTopic()) {// If there isn't already a provided value, set a default of 1sif (!substProperties.containsKey(CONSUMER_TIMEOUT_KEY)) {substProperties.put(CONSUMER_TIMEOUT_KEY, "1000");}} else {if (substProperties.containsKey(CONSUMER_TIMEOUT_KEY)) {logError(Messages.getString("KafkaConsumerStep.WarnConsumerTimeout"));}}ConsumerConfig consumerConfig = new ConsumerConfig(substProperties);logBasic(Messages.getString("KafkaConsumerStep.CreateKafkaConsumer.Message",consumerConfig.zkConnect()));data.consumer = Consumer.createJavaConsumerConnector(consumerConfig);String topic = environmentSubstitute(meta.getTopic());String offset = environmentSubstitute(meta.getOffsetVal());String[] offsets = offset.split("[,]");logBasic("Kafka partition length is {0}.", offsets.length);int partitions = offsets.length;Map<TopicAndPartition, OffsetAndMetadata> partitionOffset = new HashMap<TopicAndPartition, OffsetAndMetadata>();for (int i = 0; i < partitions; i++) {TopicAndPartition tap = new TopicAndPartition(topic, i);if (offsets[i] == null || offsets[i].equals("")) {offsets[i] = "0";}OffsetMetadata om = new OffsetMetadata(Long.valueOf(offsets[i]) + 1, null);OffsetAndMetadata oam = new OffsetAndMetadata(om,org.apache.kafka.common.requests.OffsetCommitRequest.DEFAULT_TIMESTAMP,org.apache.kafka.common.requests.OffsetCommitRequest.DEFAULT_TIMESTAMP);partitionOffset.put(tap, oam);}data.consumer.commitOffsets(partitionOffset, true);Map<String, Integer> topicCountMap = new HashMap<String, Integer>();topicCountMap.put(topic, partitions);Map<String, List<KafkaStream<byte[], byte[]>>> streamsMap = data.consumer.createMessageStreams(topicCountMap);logDebug("Received streams map: " + streamsMap);data.kafkaStreams = streamsMap.get(topic);data.numThreads = partitions;data.executor = Executors.newFixedThreadPool(partitions);data.processed = new AtomicInteger(0);return true;}复制
复制
数据流处理核心逻辑代码,完成线程内消费超时时间逻辑判断和消费行超过阈值逻辑判断,并格式化输出消息对象,包含消息内容:message,消息Key:key,分区:partition, 位移:offset 四个字段。
复制
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi)throws KettleException {Object[] r = getRow();if (r == null) {/** If we have no input rows, make sure we at least run once to* produce output rows. This allows us to consume without requiring* an input step.*/if (!first) {setOutputDone();return false;}r = new Object[0];} else {incrementLinesRead();}final Object[] inputRow = r;KafkaConsumerMeta meta = (KafkaConsumerMeta) smi;final KafkaConsumerData data = (KafkaConsumerData) sdi;if (first) {first = false;data.inputRowMeta = getInputRowMeta();// No input rows means we just dummy dataif (data.inputRowMeta == null) {data.outputRowMeta = new RowMeta();data.inputRowMeta = new RowMeta();} else {data.outputRowMeta = getInputRowMeta().clone();}meta.getFields(data.outputRowMeta, getStepname(), null, null, this);}try {long timeout;String strData = meta.getTimeout();try {timeout = KafkaConsumerMeta.isEmpty(strData) ? 0 : Long.parseLong(environmentSubstitute(strData));} catch (NumberFormatException e) {throw new KettleException("Unable to parse step timeout value",e);}logDebug("Starting message consumption with overall timeout of "+ timeout + "ms");List<Future<?>> futures = new ArrayList<Future<?>>();for (int i = 0; i < data.numThreads; i++) {KafkaConsumerCallable kafkaConsumer = new KafkaConsumerCallable(meta, data, this, data.kafkaStreams.get(i)) {protected void messageReceived(byte[] key, byte[] message,int partition, long offset) throws KettleException {Object[] newRow = RowDataUtil.addRowData(inputRow.clone(),data.inputRowMeta.size(),new Object[] { message, key,Long.valueOf(partition), offset });putRow(data.outputRowMeta, newRow);if (isRowLevel()) {logRowlevel(Messages.getString("KafkaConsumerStep.Log.OutputRow",Long.toString(getLinesWritten()),data.outputRowMeta.getString(newRow)));}}};Future<?> future = data.executor.submit(kafkaConsumer);futures.add(future);}if (timeout > 0) {logDebug("Starting timed consumption");try {for (int i = 0; i < futures.size(); i++) {try {futures.get(i).get(timeout, TimeUnit.MILLISECONDS);} catch (TimeoutException e) {} catch (Exception e) {throw new KettleException(e);}}} finally {data.executor.shutdown();}} else {try {for (int i = 0; i < futures.size(); i++) {try {futures.get(i).get();} catch (Exception e) {throw new KettleException(e);}}} finally {data.executor.shutdown();}}data.consumer.commitOffsets();setOutputDone();} catch (KettleException e) {if (!getStepMeta().isDoingErrorHandling()) {logError(Messages.getString("KafkaConsumerStep.ErrorInStepRunning", e.getMessage()));setErrors(1);stopAll();setOutputDone();return false;}putError(getInputRowMeta(), r, 1, e.toString(), null, getStepname());}return true;}复制
复制
复制
/*** Called when new message arrives from Kafka stream** @param message* Kafka message* @param key* Kafka key* @param partition* Kafka partition* @param offset* Kafka offset*/protected abstract void messageReceived(byte[] key, byte[] message,int partition, long offset) throws KettleException;public Object call() throws KettleException {long processed = 0;try {long limit;String strData = meta.getLimit();try {limit = KafkaConsumerMeta.isEmpty(strData) ? 0 : Long.parseLong(step.environmentSubstitute(strData));} catch (NumberFormatException e) {throw new KettleException("Unable to parse messages limit parameter", e);}if (limit > 0) {step.logDebug("Collecting up to " + limit + " messages");} else {step.logDebug("Collecting unlimited messages");}ConsumerIterator<byte[], byte[]> itr = stream.iterator();while (itr.hasNext() && !data.canceled&& (limit <= 0 || processed < limit)) {MessageAndMetadata<byte[], byte[]> messageAndMetadata = itr.next();messageReceived(messageAndMetadata.key(),messageAndMetadata.message(),messageAndMetadata.partition(),messageAndMetadata.offset());++processed;data.processed.getAndIncrement();}} catch (ConsumerTimeoutException cte) {step.logDebug("Received a consumer timeout after " + processed+ " messages");if (!meta.isStopOnEmptyTopic()) {// Because we're not set to stop on empty, this is an abnormal// timeoutthrow new KettleException("Unexpected consumer timeout!", cte);}}// Notify that all messages were read successfully// data.consumer.commitOffsets();return null;}复制
复制
3.5、plugin配置
复制
<?xml version="1.0" encoding="UTF-8"?><pluginid="KafkaConsumer"iconfile="logo.png"description="Apache Kafka Consumer"tooltip="This plug-in allows reading messages from a specific topic in a Kafka stream"category="Input"classname="com.ruckuswireless.pentaho.kafka.consumer.KafkaConsumerMeta"><libraries><library name="pentaho-kafka-consumer.jar"/><library name="lib/jline-0.9.94.jar"/><library name="lib/jopt-simple-3.2.jar"/><library name="lib/junit-3.8.1.jar"/><library name="lib/kafka_2.10-0.8.2.1.jar"/><library name="lib/kafka-clients-0.8.2.1.jar"/><library name="lib/log4j-1.2.16.jar"/><library name="lib/lz4-1.2.0.jar"/><library name="lib/metrics-core-2.2.0.jar"/><library name="lib/netty-3.7.0.Final.jar"/><library name="lib/scala-library-2.10.4.jar"/><library name="lib/slf4j-api-1.7.2.jar"/><library name="lib/slf4j-log4j12-1.6.1.jar"/><library name="lib/snappy-java-1.1.1.6.jar"/><library name="lib/xercesImpl-2.9.1.jar"/><library name="lib/xml-apis-1.3.04.jar"/><library name="lib/zkclient-0.3.jar"/><library name="lib/zookeeper-3.4.6.jar"/></libraries><localized_category><category locale="en_US">Input</category></localized_category><localized_description><description locale="en_US">Apache Kafka Consumer</description></localized_description><localized_tooltip><tooltip locale="en_US">This plug-in allows reading messages from a specific topic in a Kafka stream</tooltip></localized_tooltip></plugin>复制
复制
四、插件说明
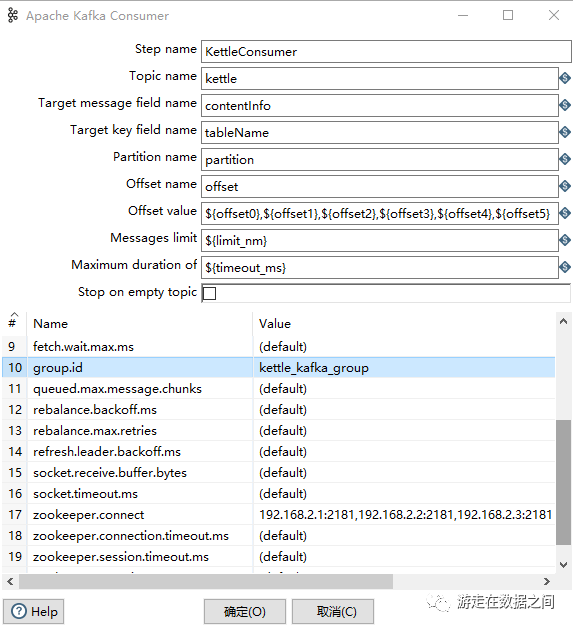
复制
①Topic name:要消费的topic名称(必选)②Target message field name:消息message对应的输出字段名称(必选)③Target key field name:消息key对应的输出字段名称(必选)④Partition name:消息partition对应的输出字段名称(必选)⑤Offset name:消息offset对应的输出字段名称(必选)⑥Offset value:初始化对应partition的offset值,多个分区用逗号隔开(必选)⑦JMessages limit:当次消费限制的消息行阈值,默认0不限制(必选)⑧Maximum duration of:当次消费限制的超时时间阈值,默认0不限制,单位毫秒(必选)⑨Stop on empty topic:topic为空时是否停止任务(可选)复制
复制
五、总结
本次KafkaConsumer插件开发探讨,是基于服务端集群版本kafka_2.12-0.10.2.0和客户端版本kafka-clients-0.8.2.1来构建整个插件体系的。下次我们基于分区消费模型构建“Kafka单分区消费Kettle插件”。
如果你需要源码或者了解更多自定义插件及集成方式,抑或有开发过程或者使用过程中的任何疑问或建议,请关注小编公众号"游走在数据之间",回复2查看源代码,回复3获取入门视频。
