




客户问: 我们觉得oracle数据库运行的sql有点慢,是不是迁移到分布式数据库会快一些?
老虎刘答:一般情况下,oracle数据库能满足大部分场景的业务需求. 建议对问题系统做个性能分析, 看看是不是做个优化就能解决问题. 到目前为止, 本人经手的绝大部分系统都可以通过性能优化(主要是SQL优化)达到预期性能指标, 不需要迁移到分布式数据库.
下面列举几个SQL优化案例.
案例1: 设计与SQL写法
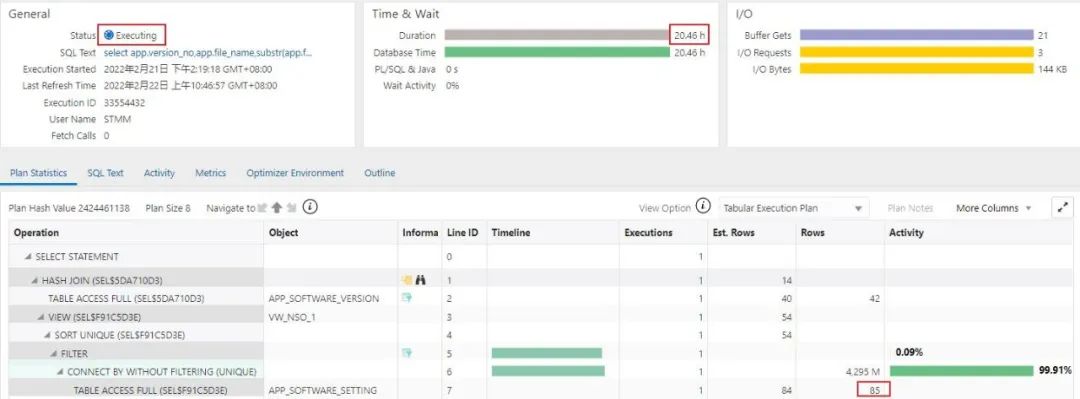
从下图的执行计划可以看到, 这个sql执行了20+小时还没有执行完, 中间结果集高达42.95亿,而涉及的表记录数只有85条.
sql文本:
select *
from app_software_version app
where app.version_status='2'
and app.version_no in
(select distinct regexp_substr(up_version, '[^,]+', 1, level) up_version
from app_software_setting ---这个表只有85条记录
where version_no ='0000001' ----version_no是主键
connect by level <= regexp_count(up_version, ',') +1
);
问题与分析:
因为在表的字段设计上违反了第一范式(将多个version信息以逗号分隔的方式存储在up_version字段中), 为了拆分up_version为多条记录, 使用了connect by+正则表达式的写法.
如果是处理单个字符串, 这个写法没有问题. 开发人员误以为处理的是通过主键返回的一条记录,殊不知这个where条件是在connect by之后才执行的, 用这种处理单个字符串的写法实际上处理的是全表85条记录,写法上的错误导致了一个巨大中间结果集的生成,出现了严重的性能问题.
这种情况只需要把sql写法调整好(connect by前面的select .. where部分加个括号就行了),执行时间在0.0x秒内是完全没有问题的.
案例2: SQL写法
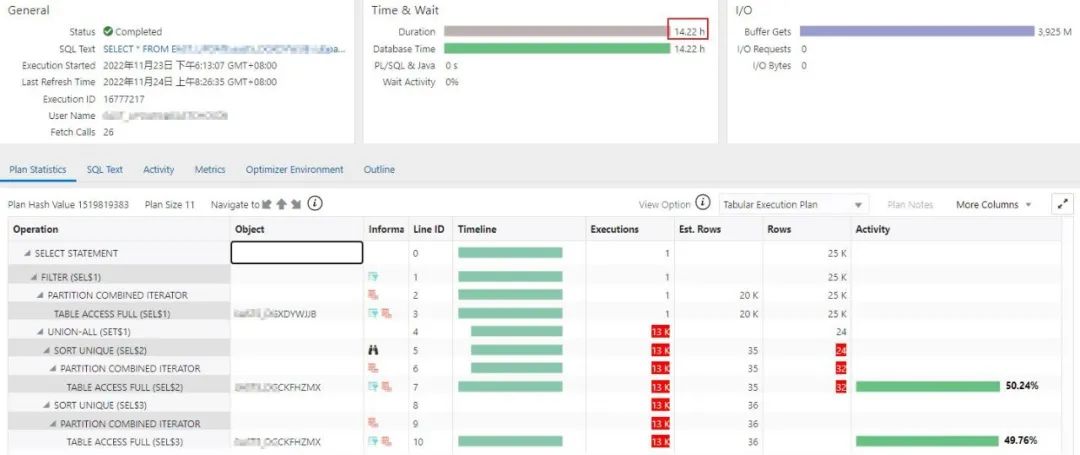
下面这个sql执行了14+小时:
我用下面sql做了简单模拟(注意: 可以用dba_objects做数据源,CTAS来生成t1 t2两表. 两表的关联字段默认都没有定义为not null, t2表的object_id和data_object_id都分别创建了单字段索引):
select * from t1 a
where a.object_id is not null
and a.object_id not in
(select object_id from t2
union all
select data_object_id from t2
);
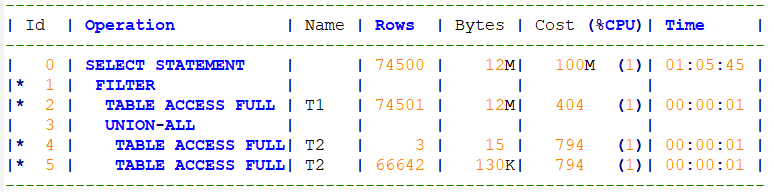
生成的执行计划是下面这样的(T2表要做几万次的全表扫描, 有索引也用不上):
优化方法:
在两个t2 后面分别增加where object_id is not null 和where data_object_id is not null 后, 执行效率会提升几百倍.
分析与点评:
增加is not null条件后的sql与原sql是不等价的, 但是改写后的写法也是最符合业务逻辑要求的. 也就是说, 因为原sql的逻辑不严谨(一旦子查询表关联字段上的某条记录值为null,则整个查询返回空结果集), 从而导致了低效执行计划的生成.
案例3: 索引的作用
这是一个运行在oracle一体机exadata上的数据库, top 1 sql平均执行时间51秒, 单个sql的消耗(DBTime)占整个数据库的87.77%:

sql文本如下:
SELECT * FROM CUSTOM_APPLY_360
WHERE
(
(TO_DATE(:1,'YYYYMMDDHH24MISS')>= TO_DATE(CREATE_TIME,'YYYYMMDDHH24MISS') AND PUSH_CREDIT_FLAG = 'I')
OR
(PUSH_CREDIT_FLAG = 'F' AND PUSH_CREDIT_COUNT < 3)
)
AND (CREDIT_REPORT_TYPE = '1' or CREDIT_REPORT_TYPE is null);
表上存在一个三字段联合索引: (CREATE_TIME,PUSH_CREDIT_COUNT,PUSH_CREDIT_FLAG). 但是这个索引没有被使用(因为如果使用这个索引,SQL执行效率会更差), 执行计划使用的是全表扫描.
测试人员根据我的建议, 在测试环境里为表新建了一个两字段联合索引(这里省略了查看相关字段数据分布的步骤): (PUSH_CREDIT_FLAG , CREDIT_REPORT_TYPE) , 反馈如下:

一个简单的索引调整, 效率提升2.5万倍. sql执行效率的提升, 不但提升了客户感知, 同时也大大降低了资源的使用(CPU/存储/内存).
点评:
这个sql如果放到分布式数据库, 肯定也能有几倍的提升, 但是消耗的资源还是差不多的. 联合索引选哪些字段做组合, 字段的先后顺序都是大有讲究的.
案例4: 写法与索引配合
这是oracle原厂Chris Saxon大师(国内官方公众号有很多他的视频课程)最近出的一个小题目:
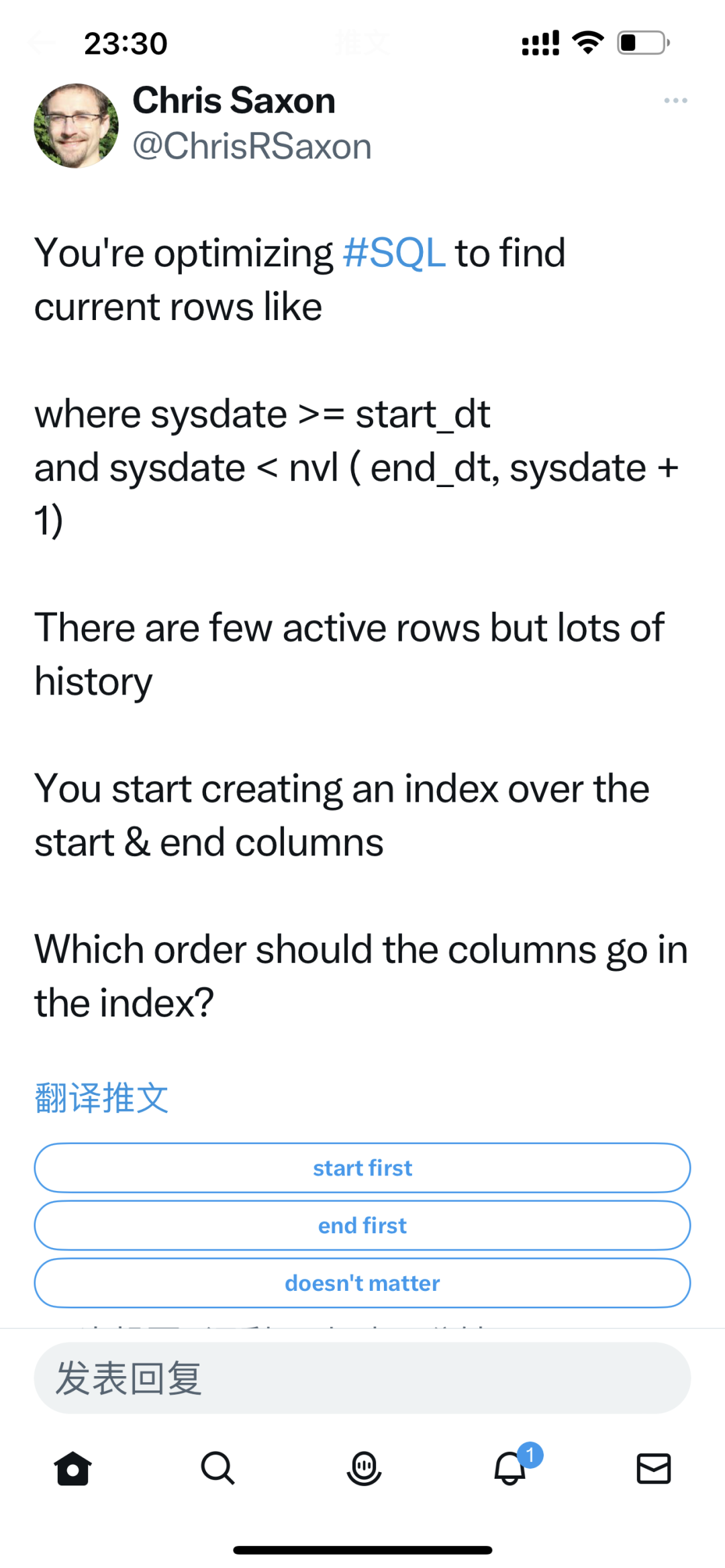
我理解的active rows: 即符合current rows SQL里面的条件 ,较少
我理解的history: end_dt<sysdate 较多
你的选择是?
(这里读者可以思考一下再往下看)
这种sql,很多开发人员可能不管谓词字段的数据分布情况, 直接创建(start_dt,end_dt)两字段联合索引, 因为有上面的条件,这个索引是低效的,优化器可能宁可全表扫描, 也不用这个索引.
我想出题者的本意应该是让大家选"end first", 但是我认为原sql的写法, 没有合适的索引能实现优化的目的, 因为没法创建nvl(end_dt,sysdate+1) 这样的函数索引.
我给出的优化方法是需要改写,然后再配合索引:
改写SQL, 将SQL改成
where sysdate>=start_dt and (end_dt>sysdate or end_dt is null);
创建(end_dt,0) 联合索引. 不需要start_dt字段的参与, 因为start_dt<=sysdate这个条件没有过滤性.
优化方法见仁见智, 如有不妥, 请指正, 在此感谢!
总结:
现在的DBA水平普遍都比较高, 数据库的性能优化主要就是优化SQL.很多生产系统, Top SQL都或多或少存在性能问题, 大部分情况我们都能通过创建索引或是改写SQL来实现优化目的, 一般不需要大动干戈去迁移到分布式数据库.
如果没有好的设计,合适的SQL写法和索引的配合, 即使是使用oracle数据库,可能也达不到预期的效果; 而如果有好的设计,配合正确的SQL写法和合适的索引, 即便是使用国产数据库, 也能得到较好的性能.
顺便打个广告:
如果你想深入学习sql写法和索引相关技术, 错过了之前的培训也没有关系, 这些培训都有ppt和录屏,也可以加入学员微信群学习讨论, 跟之前参加培训没有任何区别. 培训材料购买链接--> 老虎刘<oracle性能优化>培训材料
(全文完)



