




StarRocks在58的实践
--2022-06-08 春雷
1、前言
目前公司有着多种业务场景,例如车业务、房产业务、本地服务、招聘业务、金融业务等等。
随着业务的高速发展,越来越多的分析需求涌现,例如:安全分析、商业智能分析、数仓报表,用户画像等,这些都是体量比较大的分析场景。
为了满足这些分析型的业务,DBA团队21年就开始调研列存数据库StarRocks、TiFlash、ClickHouse等,评测性能及功能。
总体评测下来,StarRocks表现优秀,我们进行了逐步上线应用,表现良好。
2、引入StarRocks的原因
DBA组运维大量的TiDB数据库,集群120套+,TiDB在4.0版本引入了TiFlash 组件,支持HTAP的场景,DBA引入并上线了部分集群。
使用中发现TiFlash的性能无法完全满足业务的需求,例如:
写入性能不能满足
原因:TiFlash 数据同步于TiKV,则写速度受限于TiKV的性能,如果AP的业务比重比较大,则需要很多的TiKV与TiFlash,才能保证性能,造成了资源浪费
读性能不能满足
原因:SQL的执行计划会自动选择TiKV、TiFlash,有时执行计划不准,本应该走TiFlash更快,但是走了TiKV,导致SQL执行时间不稳定;另有些走了TiFlash的性能也无法满足
综上:TiDB主打的HTAP场景,TP为主,AP次要,或者轻量级的AP分析
但是业务有很多纯AP的分析场景,DBA便尝试满足,调研了StarRocks,并对比了ClickHouse
发现StarRocks在性能、功能,易运维上均优于ClickHouse,便进行了引入与落地。
3、StarRocks简介
3.1、简介
StarRocks是⼀款经过业界检验的, 现代化的, ⾯向多种数据分析场景的, 兼容MySQL协议的, ⾼性 能的, 分布式关系型列式数据库。
StarRocks脱胎于百度⼴告业务的实时分析场景, 于2018贡献于Apache开源社区, 之后在美团,小米,字节跳动, 京东等互联网企业被适用于核心业务实时数据分析, 得到了业界的检验.
StarRocks充分吸收关系型OLAP数据库和分布式存储系统在大数据时代的优秀研究成果, 并在业界实践 的基础上, 进⼀步改进, 优化, 架构升级和加⼊新功能, 形成企业级产品.
StarRocks致力于满足企业⽤户的多种数据分析场景. 支持多种数据模型(明细表, 聚合表), 多种导入方式 (批量, 可整合和接⼊多种现有系统(Spark, Flink, Hive, ElasticSearch).
StarRocks兼容MySQL协议, 可使用MySQL客户端和常用BI⼯具都可以对接StarRocks来进行数据分析。
StarRocks采⽤分布式架构, 对table进行水平划分并以多副本存储. 集群规模可以灵活伸缩, 能够支持 10PB级别的数据分析; 支持MPP, 并行加速计算; 支持多副本, 具有弹性容错能力.
StarRocks采用关系模型, 使用严格的数据类型, 使用列式存储引擎, 通过编码和压缩技术, 降低读写放大. 使用向量化执行方式, 充分挖掘多核CPU的并行计算能力, 从而提升显著提升查询性能.
3.2、重要特点
性能好:
写入性能好,broker load导入速度170w/s+
读性能好,大单表,多表关联查询,均优于ClickHouse
易运维:
只有FE、BE、Broker等节点,简单
新建集群 简单,创建FE/BE
扩容、缩容简单,一个命令即可扩缩容;自动均衡数据
数据接入方便
导入途径多种,例如broker load(数据源HDFS),routine load(数据源kafka),stream load(数据源本地文件),外表(数据源MySQL、TiDB、ES、Hive等),Flink,datax等;公司已经支持多种导入途径
支持,兼容MySQL协议
无需更改SQL,直接可以使用,方便
表多种模型:
明细模型,聚合模型,更新模型,主键模型;可以方便业务的明细、聚合等查询需求
高并发:
支持高并发查询
国产数据库
国产数据库,问题反馈解决及时。
4、评测
大致评测方向,从2方面来看,一个是功能上,一个是性能上,涉及数据库:StarRocks,ClickHouse,TiDB&TiFalsh每种数据库都各自有各自的特点~
4.1、功能上
功能 | StarRocks | ClickHouse | TiDB、TiFlash |
标准SQL | 支持,兼容MySQL协议 | 不完全支持 | 支持,兼容MySQL协议 |
分布式join | 支持 | 几乎不支持分布式join,推荐大宽表 | 支持 |
高并发查询 | 现代化MPP,提高并发查询量 | 不支持高并发,官方建议QPS为100 | 支持 |
运维 | 标准版:支持自动扩容、故障恢复。但需要自己实现自动化部署、扩缩容节点、升级等,有一定开发工作。 | 依赖zookeeper,运维成本高 | 运维方便 |
企业版:管理界面,提供集群DashBoard,SQL profile工具和监控报警等功能 | |||
社区 | 社区开发为国人 | 开源社区被俄罗斯公司把持 | 开源社区积极良好,支持给力! |
标准版已经开源 | |||
性能 | 读写性能好 | 单机性能强悍 | TiFlash 4.0版本,轻量级分析良好,量大的分析读性能不如StarRocks |
分布式性能会提升 | 5.0版本,性能提升明显 | ||
读性能同比StarRocks部分SQL差一些 | 写性能受限于TikV,一般 | ||
写性能好 | |||
场景 | 纯分析场景 | 纯分析场景 | 适用HTAP场景 |
其他 | 稳定性比Apache doris 高 | 周边组件丰富 | |
性能比Apache doris 高 3-6倍 | 迁移方便 | ||
稳定性高 |
4.2、性能上
4.2.1、单表查询对比
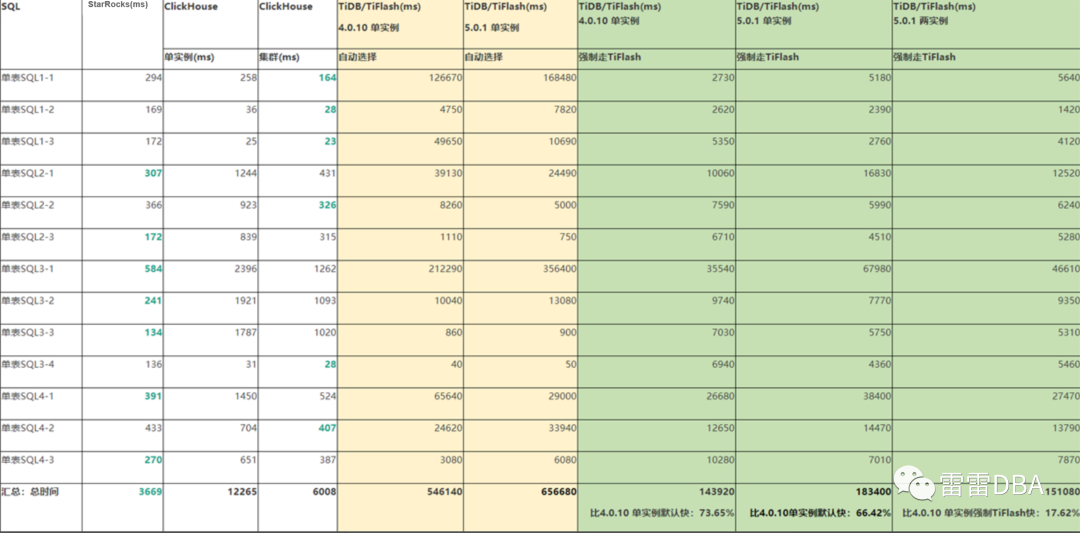
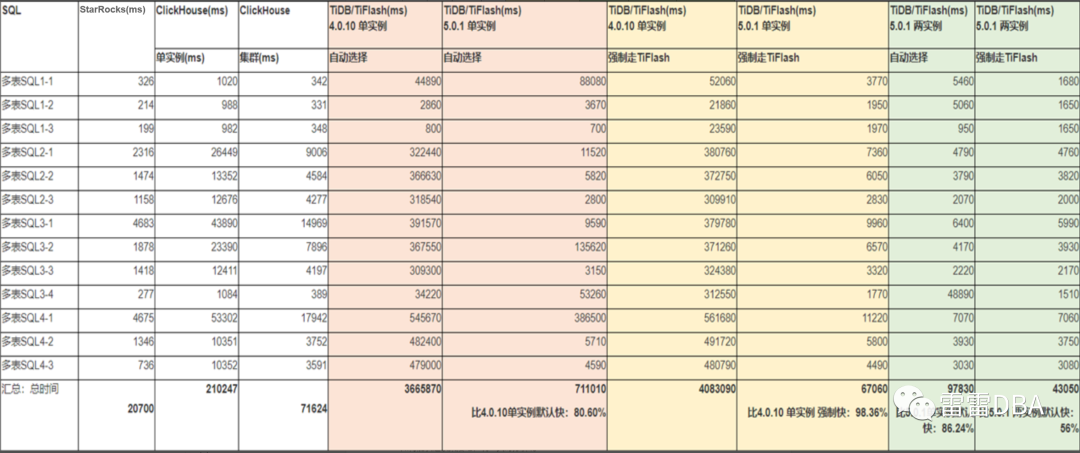
4.2.2、多表关联查询
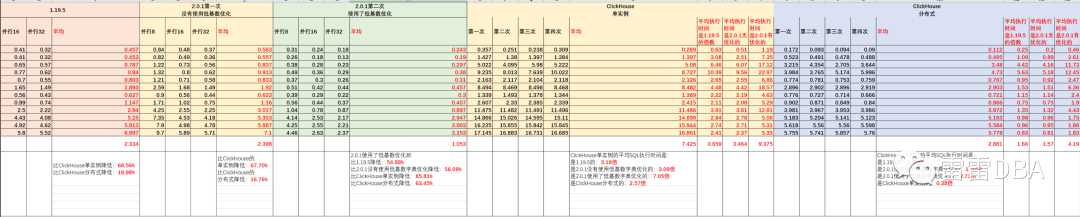
4.2.3、低基数查询性能对比
StarRocks2.0版本引入的低基数优化后,与ClickHouse的SQL查询性能对比
5、业务实践
目前StarRocks已经应用到了所有业务线,涉及了日志流水,用户画像,安全分析,DBA慢SQL,实时数仓,报表系统,监控数据,风控数据分析等。业务类型比较多,下面举例3个业务
5.1、安全分析相关业务
每天服务器上的信息情况,是内部安全人员比较关心的,但是服务器上每天有大量的信息,如何能快速收集落地、统一实时分析呢?
写入的量上的要求,每天大约几亿的数据需要落地
实时分析:快速的分析,例如:最近15分钟,机器信息的情况是怎样的?
定期数据清理
数量累增
因为写入量大及快速分析的需求,我们选择了StarRocks。在使用初期,我们使用了 明细模型,20天左右,数据量就800亿+了,磁盘8T左右,导致一定的性能影响,后与开发商定,不要详细的历史明细,记录指定时间的数量即可,改成 聚合模型,每15分钟进行聚合,次数累增,这样就减少了数据量,且按照时间分区,定期清理分区即可,方便了数据清理且方便了查询~目前每天10亿左右数据,数据量降低了 75%。
5.2、DBA内部业务
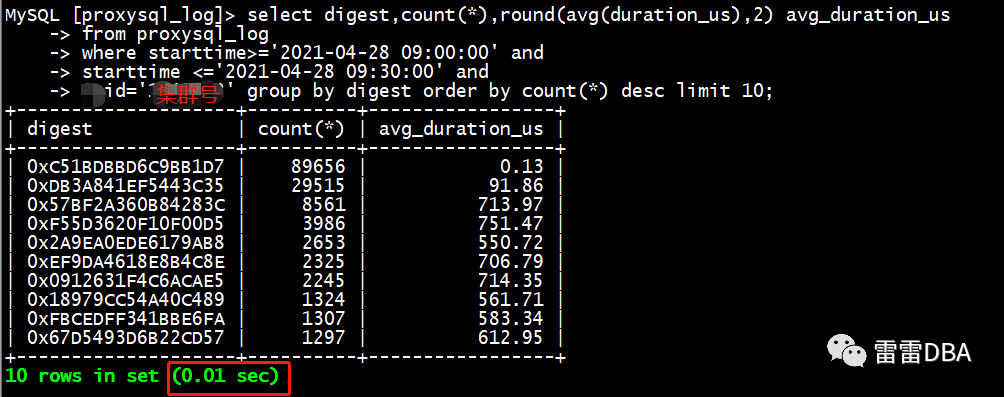
MySQL中间件,我们使用的ProxySQL,ProxySQL支持展示SQL情况,但是每次需要重置下,才重新开始统计,比较麻烦,如何分析指定时间的SQL情况,比较困扰。每个ProxySQL有自己的全日志,我们可以分析全日志来获取需要的信息,第一个架构方案,我们想到了ES,ProxySQL全日志-->filebeat采集-->kafka-->logstash-->ES,但是实际使用,发现查看流水可以,但是分析起来就比较麻烦,不如写SQL的方便。后来架构又改成了
ProxySQL全日志-->filebeat采集-->kafka-->StarRocks,这样就可以快速分析了~
另一个问题,因为线上的ProxySQL的日志量特别大,不能所有集群都开,我们设置了可以选择开启,这样有需要的集群才进行分析。降低存储的压力。
举例:分析某30分钟某集群的SQL执行情况,按照次数排序,查询很快~
5.3、业务报表
某部门的报表系统底层存储使用的是自己搭建的数据库,为Infobright,这是一款基于知识网格的列式数据库,对大批量数据的查询性能非常高。
但是公司要进行成本节约,不允许再申请机器了,且业务需要自己维护数据库,所以需要有一个可以别人支持运维且性能更好的数据库产品进行替代,使用StarRocks,在性能上提升明显,且DBA提供运维,业务便进行了一定的数据迁入。
目前大约迁移了50%左右。
6、管理实践-版本
StarRocks经历了多个版本,1.11到当前的2.2.1 版本,每次新版本的发布都会带来一定的性能提升,bug的修复,在版本上,推荐大家按需升级到最新的版本比较好,优先升级不太重要的业务的集群,分批逐步升级。
7、管理实践-拓扑工具
如何快速知道一个starrocks集群的拓扑,需要有方便展示的工具,我们开发了qstarrocks工具,此工具跟元信息架构紧密相连的,大家逐层设计好元信息表即可,例如集群信息表,实例信息表,业务线信息表,库信息表,负责人信息表,域名信息表,vip信息表等,大家参考各自公司的实现即可。
【功能支持】:
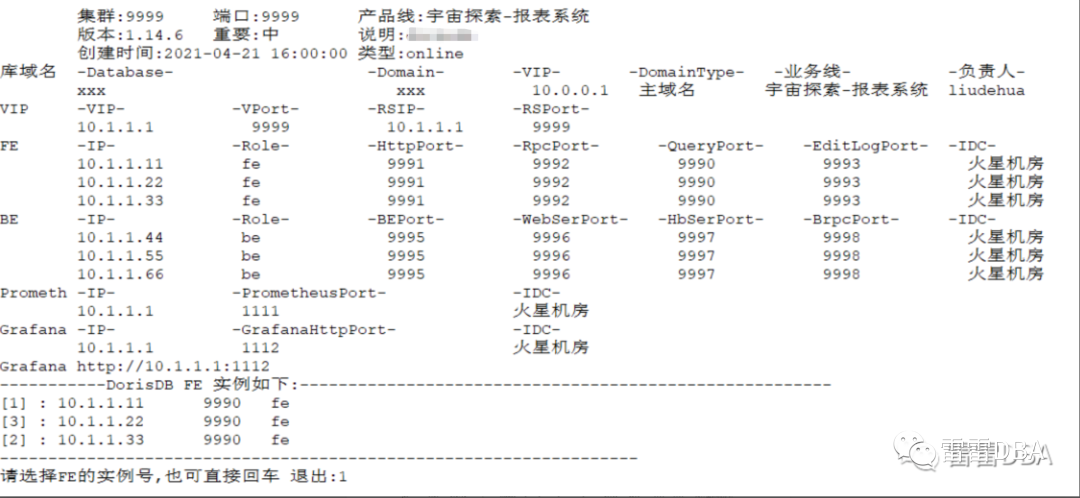
支持集群拓扑信息展示,包括:角色,IP,Port,机房,Domain,VIP,业务线,负责人,重要性,创建时间,监控地址等
支持快速登录指定FE,方便日常操作
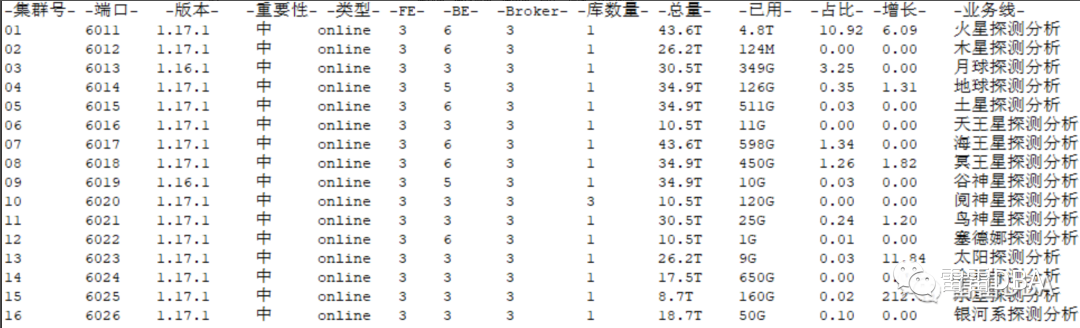
支持集群重点信息展示,集群号,端口,版本,重要性,类型,各节点数量,库数量,磁盘总量,使用量,占比,增速,业务线等
【集群拓扑信息展示】:
【所有集群重点信息展示】:
8、管理实践-集群管理工具
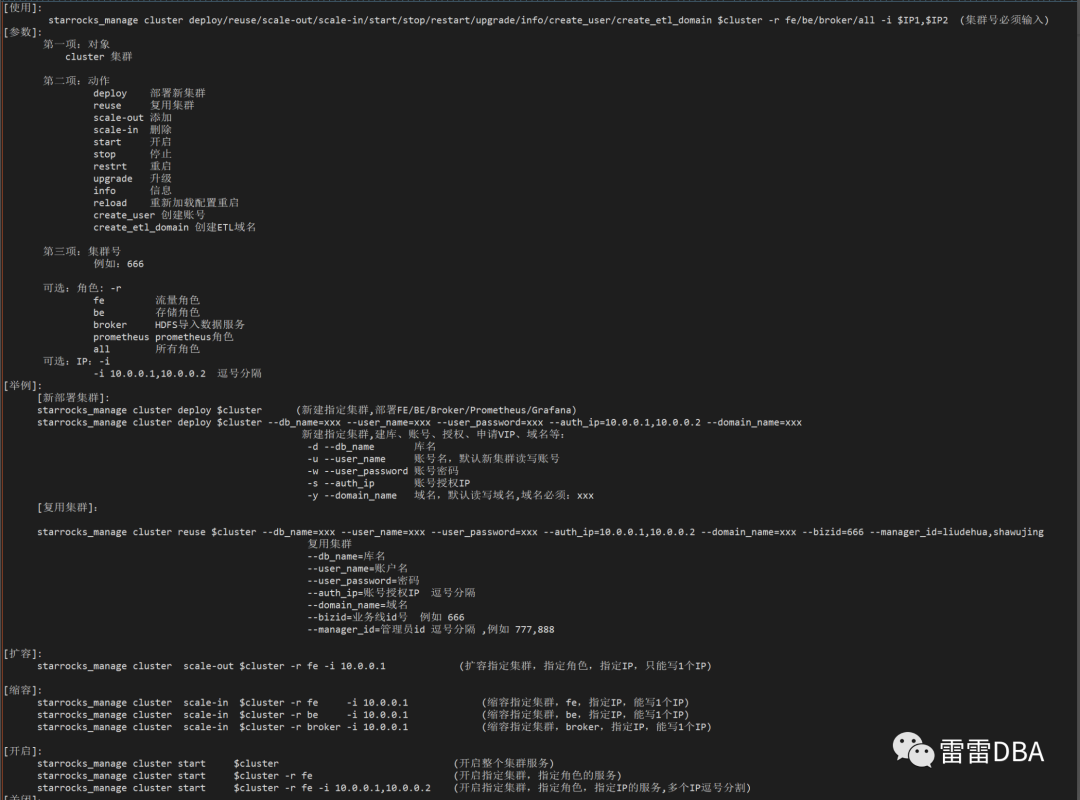
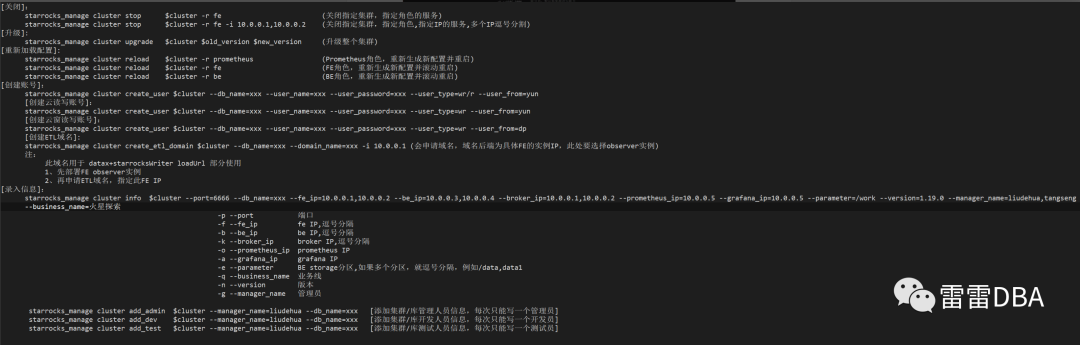
为了应对大量集群的部署,扩缩容,版本升级,开启、管理,维护管理员等操作,需要有一个统一的管理工具,因此我们开发了starrocks_manage工具,支持:
部署新集群
复用集群
添加
删除
开启
停止
重启
升级
信息
重新加载配置重启
创建账号
创建ETL域名
9、管理实践-监控实现
StarRocks监控分为:存活监控 、性能监控。因为之前的TiDB的经验,建设分为:
存活监控:
存活检查工具 方便日常的状态检查
存活监控 任务式采集,报警
性能监控:
根据一定的运维经验,获取重要的监控指标,分为:服务器相关、实例相关的
汇总监控:
因为正常部署是一套集群1套监控,要统一地点看所有集群的重点监控的话,就要汇总到1套 Grafana 上
当前监控工具也可以检查元信息与Zabbix 的差异host,并添加/删除节点
此处为监控的全部架构设计图:

9.1、存活监控
存活监控的节点信息获取是来自于数据库的命令:
SHOW FRONTENDS;
SHOW BACKENDS;
Prometheus+Grafana 是官方推荐的监控架构,所以我们会通过Prometheus的接口来获取节点的存活信息,可以从监控项:up 里面获取FE、BE节点的存活情况,上报到DBA统一监控zabbix,利用zabbix发送报警等。
例如:
up{group="be", instance="10.1.1.1:666", job="starrocksdb_prometheus_666"} | 1 |
up{group="fe", instance="10.1.1.2:777", job="starrocksdb_prometheus_666-1"} | 1 |
【检查工具实现】:
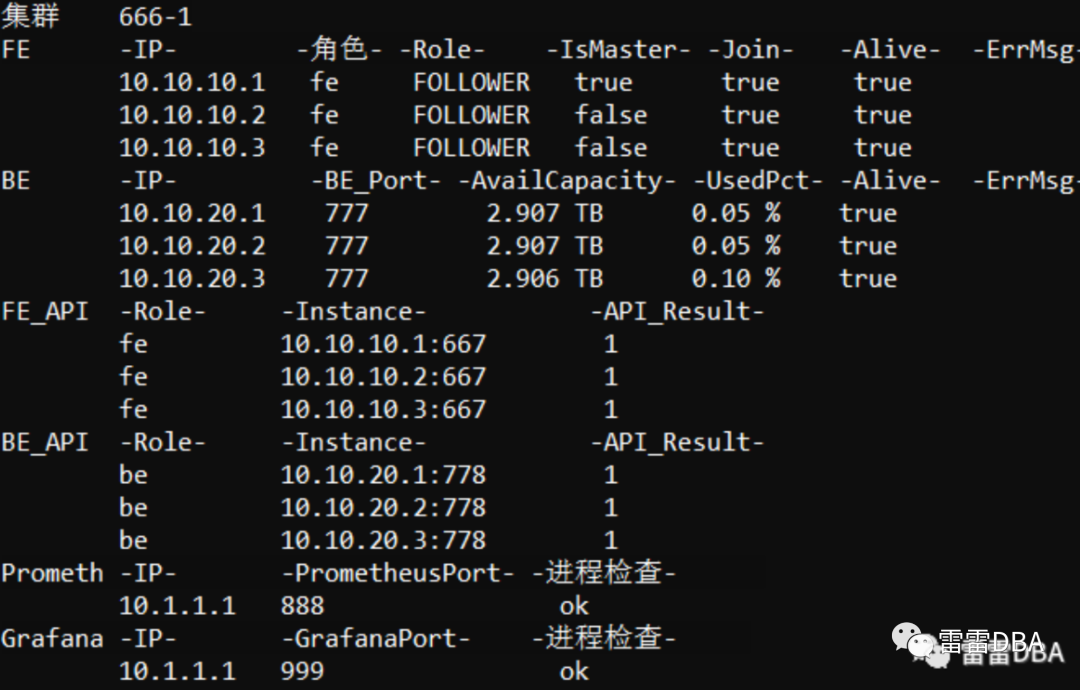
9.2、性能监控
prometheus接口获取重点信息,服务器级别,实例级别,上报到zabbix,利用zabbix实现性能报警等。
当前已经完成了监控项的采集,具体的监控图展示还在开发中
10、管理实践-导入任务管理
在业务使用StarRocks时,有多种接入方式,常见的有flink,datax,kafka,stream load等,其中的kafka直接写入是很方便的一种方式,为routine load;
当前已经在运行的kafka任务超过了120个,急需一个对kafka导入任务的管理体系。
梳理需求如下:
业务人员:工单申请接入kafka,简单的引导方式
DBA:自动化执行kafka工单
开发、DBA:查看
可查看任务运行状态
可查看任务的基本信息
非running等异常状态,可报警
可查看延迟信息及详细的各个partition的延迟信息
可查看创建SQL
可查看导入的条数、报错条数等
开发:操作
可以下线任务
可以重建任务
可以设置报警接收人员
我们开发了快速查看任务创建SQL的工具,qstarrocks,可以通过此命令快速查看任务的状态与创建SQL,进行快速重建。原理就是利用show routine load命令的结果,拼接任务的创建SQL。
【查看集群的所有导入任务状态】:

【查看创建SQL】:
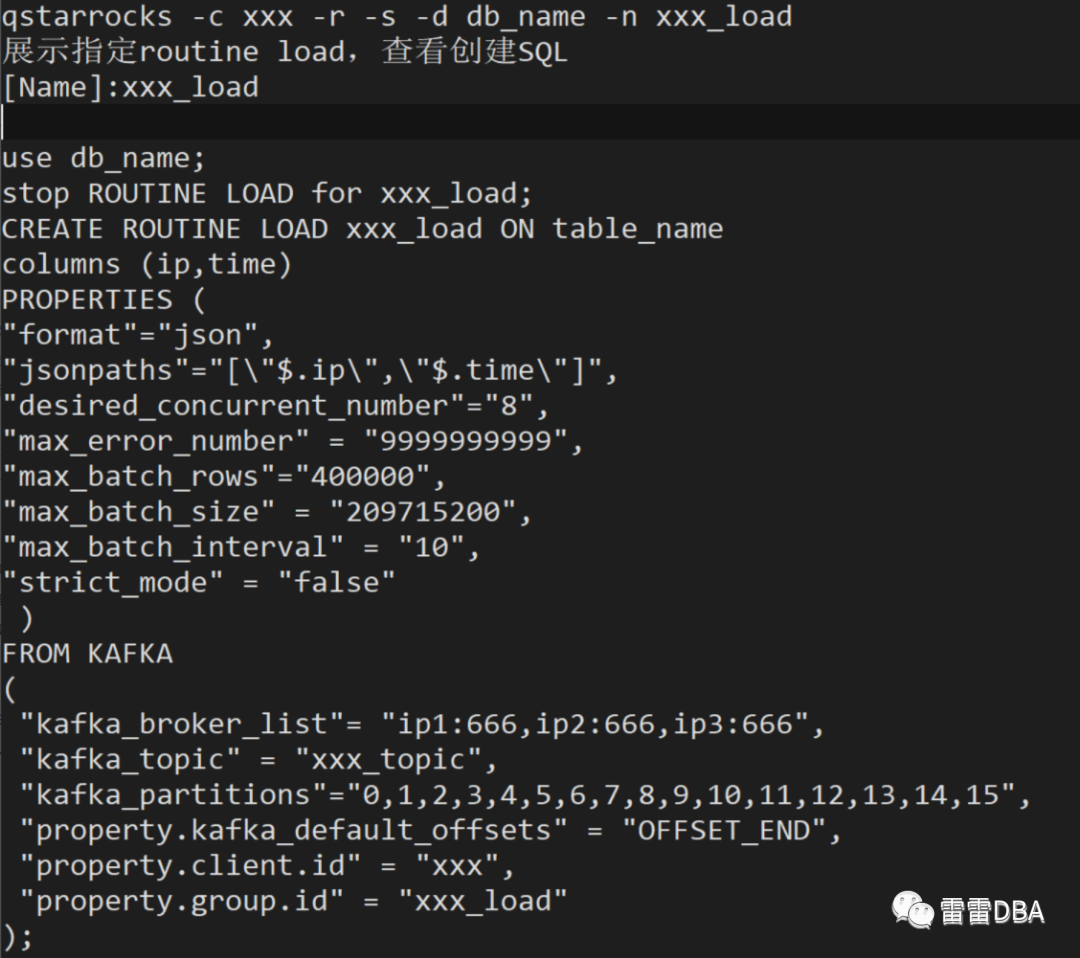
为了更方便开发、DBA详细的了解任务的情况,我们又整体设计了任务的管理,并开发了starrocks_kafka工具。
此工具整合了多种功能:
创建、重建kafka任务
查看kafka的状态:运行状态,延迟状态,消费行数等状态
查看kafka的具体数据
获取创建SQL
监控与报警:DBA与业务负责人
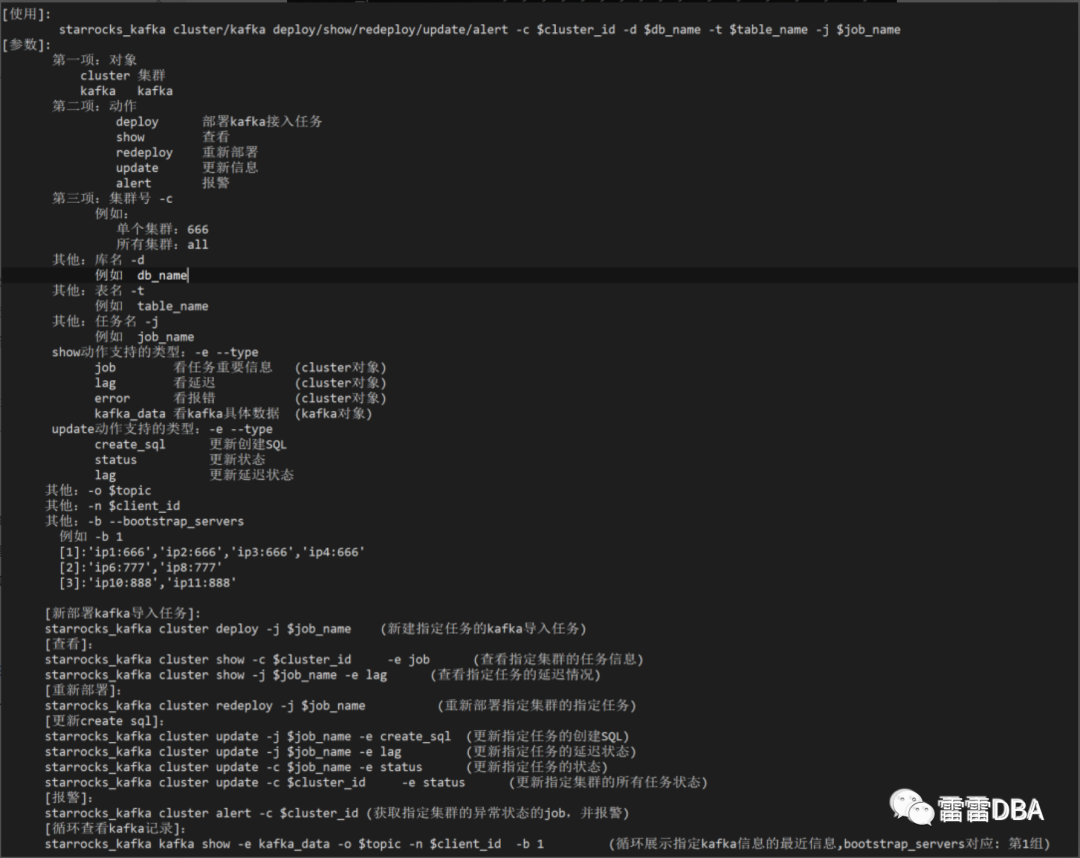
【架构图】:
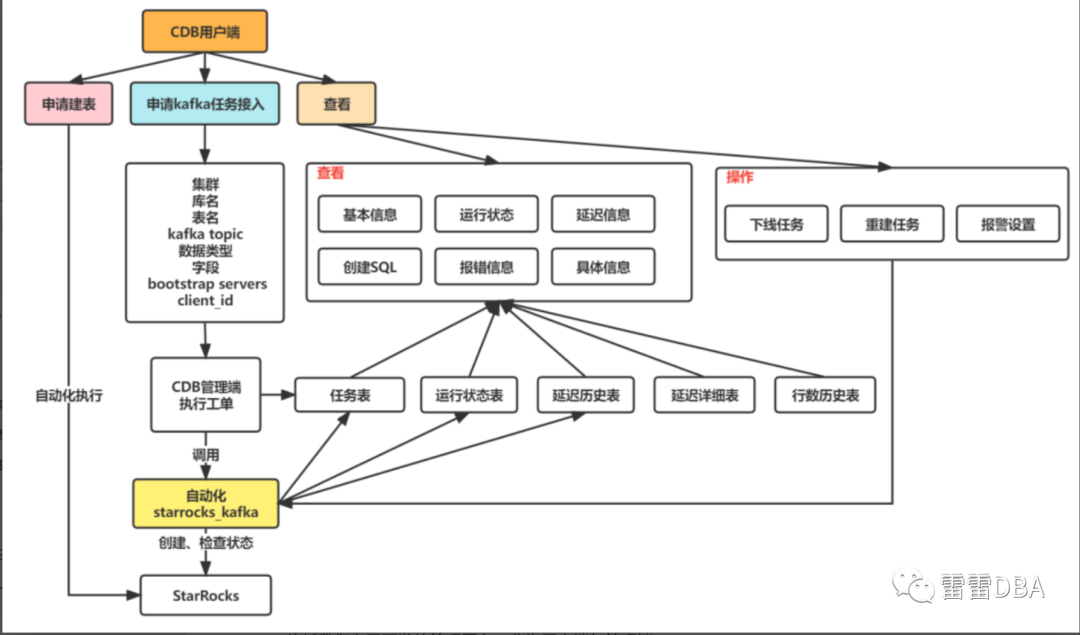
依托我们自己开发的管理平台,分为用户端与管理端。
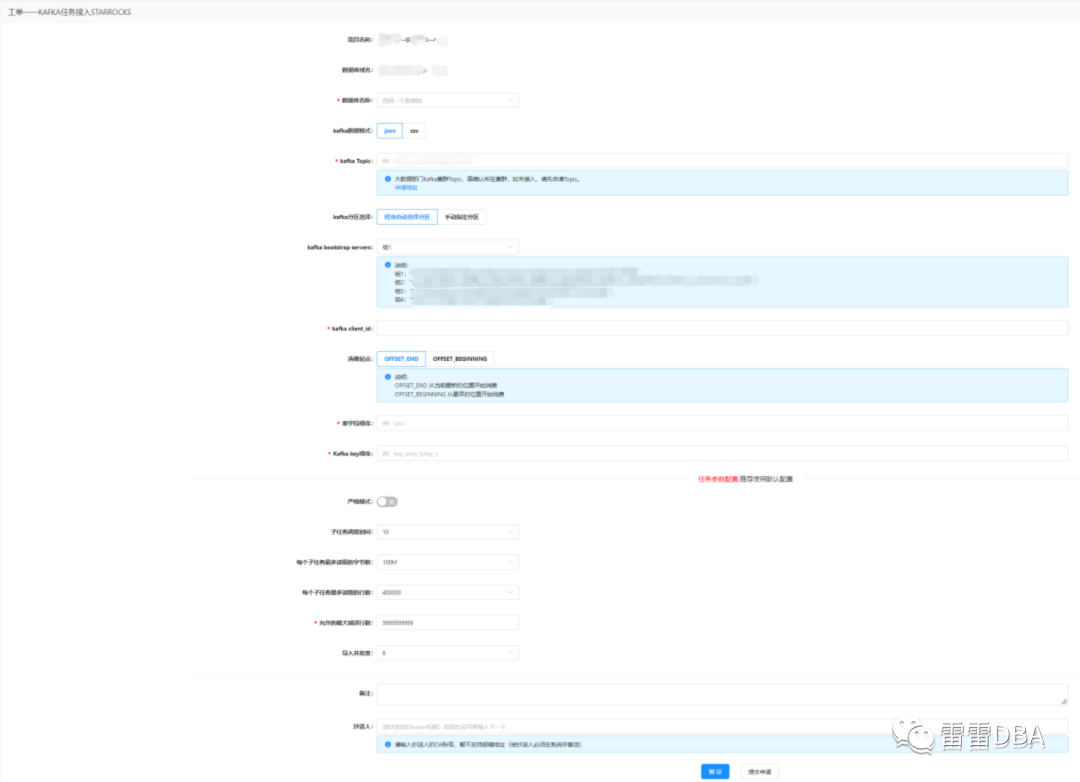
【用户端-申请kafka接入任务的工单】:
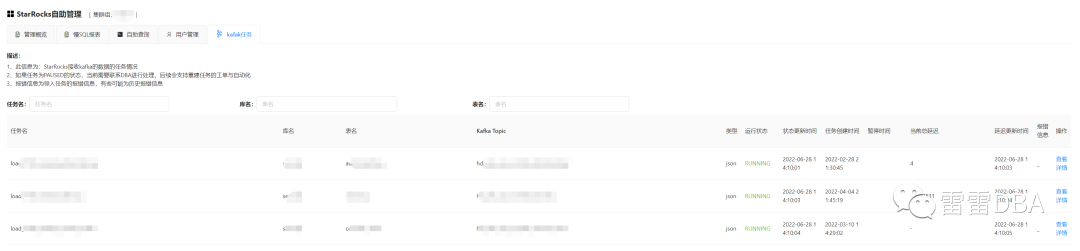
【用户端-任务展示】:
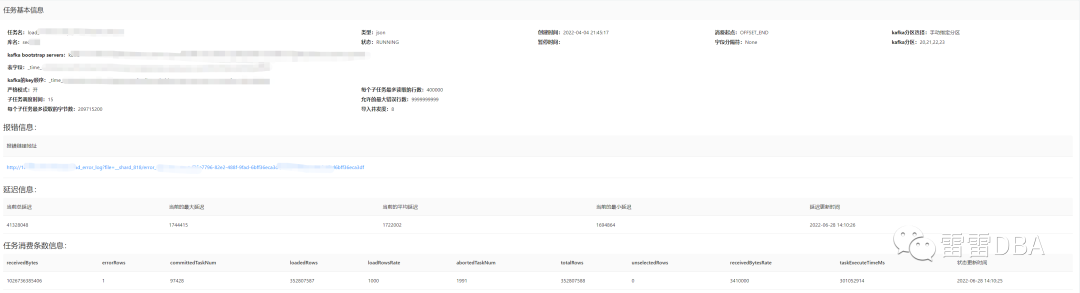
【用户端-具体任务展示】:基本信息 与 报错信息
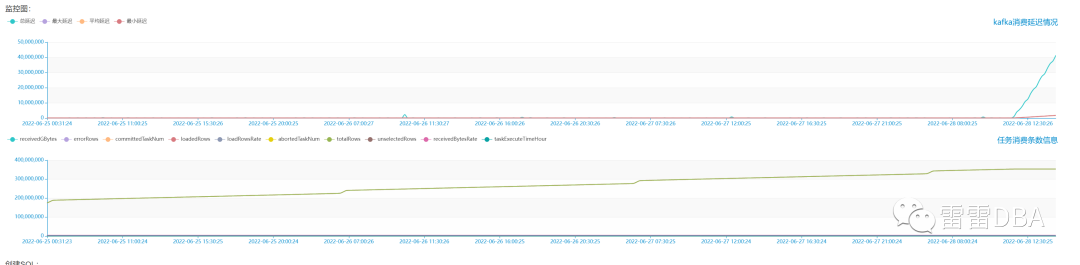
【用户端-具体任务展示】:监控图
【用户端-具体任务展示】:创建SQL

经过以上的一些设计与工具、平台的开发,我们当前可以实现稍微轻松一些的kafka的任务维护了,且可以供业务同学方便的查看任务的相关信息了
11、管理实践-慢SQL管理
11.1、具体实现
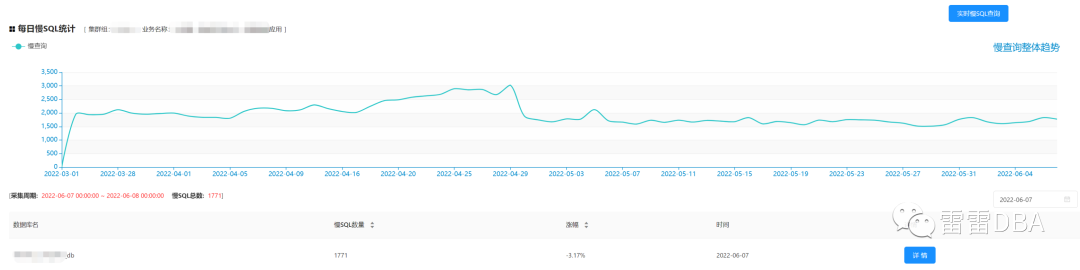
StarRocks的日常使用,我们需要清晰的了解数据库的SQL运行效率,清晰的展示慢SQL的情况,方便DBA与开发查看,分为天级别慢SQL情况,SQL实时流水,支持指定时间汇总展示三部分。
【StarRocks的SQL日志格式】:
fe/log/fe.audit.log
里面有2种日志:[query] 和 [slow_query] ,慢SQL我们过滤slow_query即可
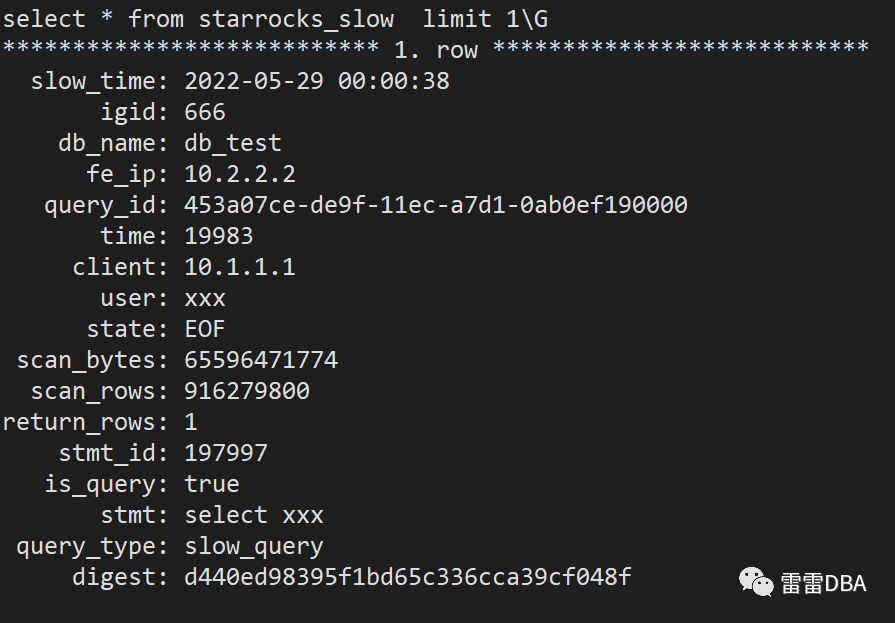
【慢SQL日志举例如下】:
2022-06-08 09:05:49,223 [slow_query] |Client=10.1.1.2:42141|User=default_cluster:xxx|Db=default_cluster:xxx|State=EOF|Time=10|ScanBytes=1339|ScanRows=1|ReturnRows=1|StmtId=43542666|QueryId=edbdd4e3-fd64-11eb-b176-0ab2114db0b3|IsQuery=true|feIp=10.1.1.1|Stmt=SELECT 1|Digest=99fa3a962b9640a78ceb79d81a9e83c0
【具体实现】:
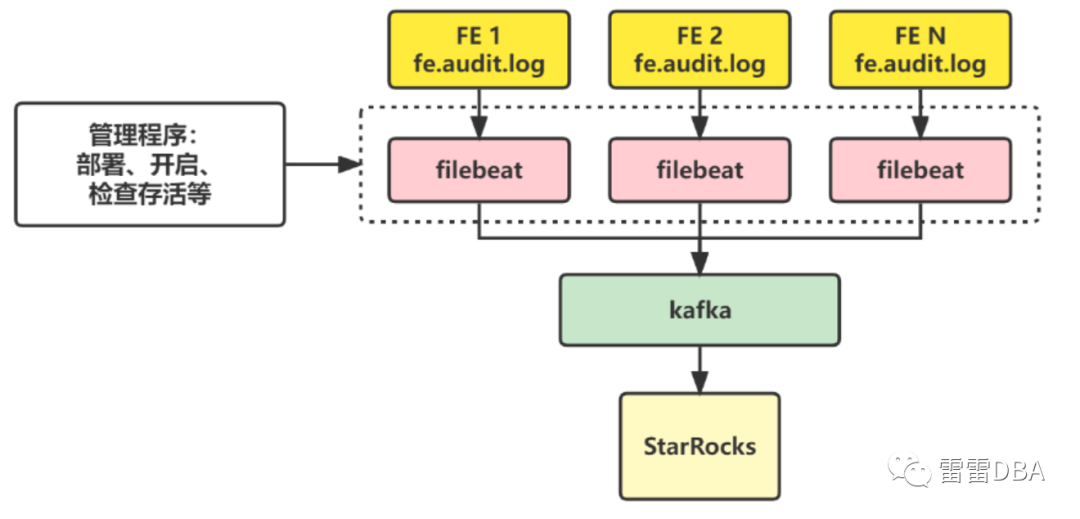
使用通用的日志采集工具,filebeat
StarRocks作为底层的存储,方便分析
kafka接入方式,快速、高效
SQL指纹方便进行分类
【实现架构】:
【filebeat 过滤采集 】--> 【kakfa】 --> 【StarRocks】
【查看录入到库里的慢SQL结果】:
11.2、平台展示
【集群的天级别慢SQL趋势情况】:
【具体慢SQL】:

【实时慢SQL】:
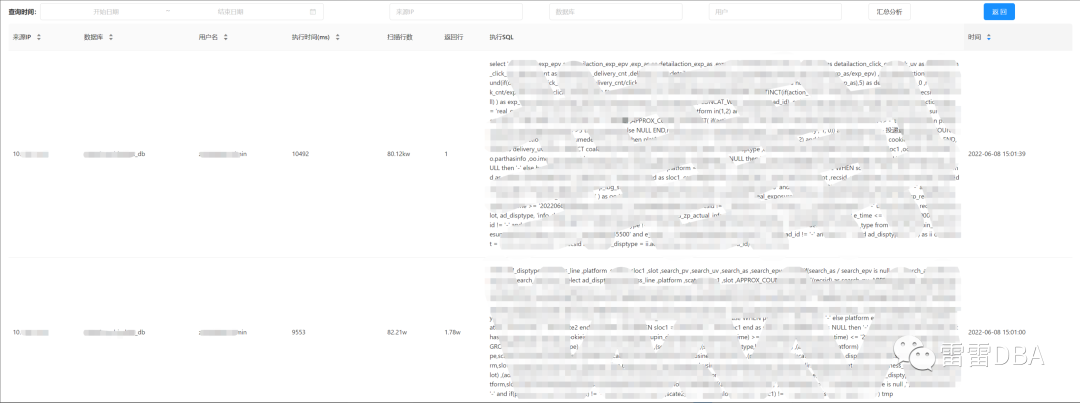
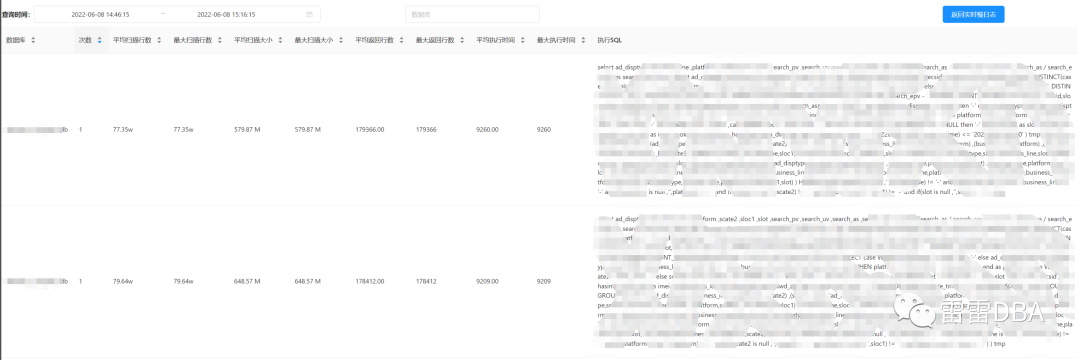
【指定时间的汇总】:
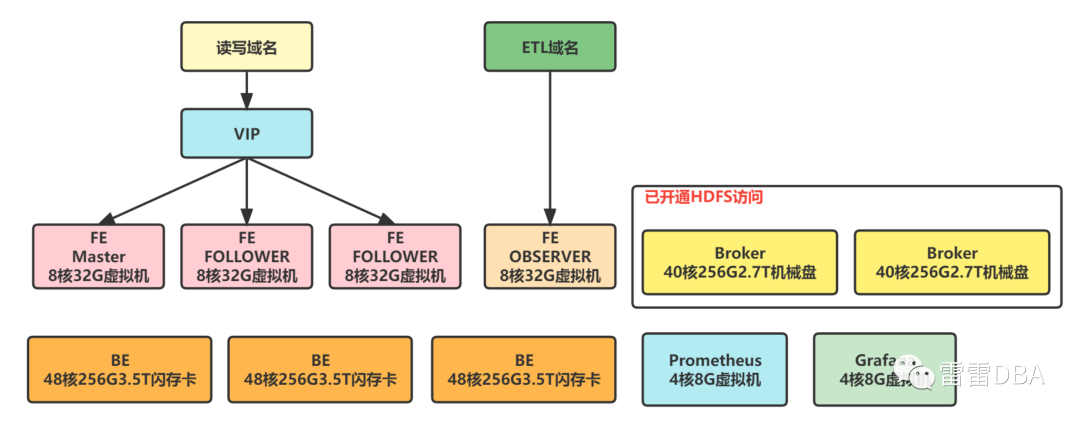
12、云化实践
StarRocks使用初期,我们:BE使用物理机混合部署,FE使用虚拟机部署,虚拟机公司最高的配置为8核32G内存300G磁盘的,架构图如下
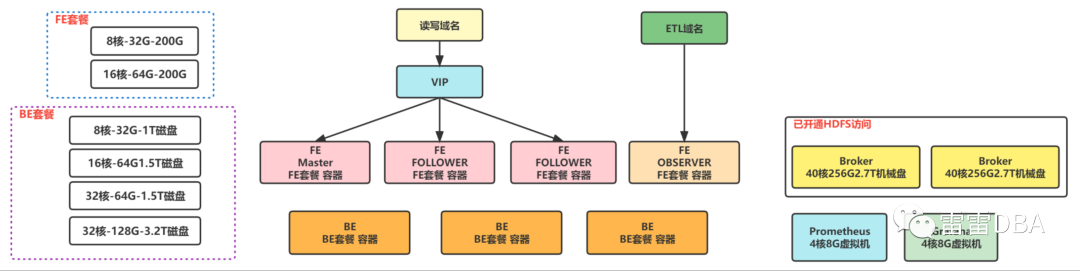
但是随着业务的使用,我们发现总会有FE节点宕掉的情况发生,查看原因为,内存吃满oom 了,有些是慢SQL导致,有些是元信息过大导致的。但是FE已经是公司虚拟机最高的配置了,不能再增加了,此时我们就想到了使用Docker 来部署,于是制定了套餐,以满足不同的业务需求:
FE套餐:
8核-32G内存-200G磁盘
16核-64G内存-200G磁盘
BE套餐:
8核-32G内存-1024G磁盘
16核-64G内存-1500G磁盘
32核-64G内存-1500G磁盘
32核-128G内存-3200G磁盘
【云化的集群架构如下】:
目前已经使用云化部署的集群已经有7套左右了,历史的集群在逐步迁移到云环境上。新的集群默认使用云化环境部署。
其他云化相关管理的工作还在持续开发中,例如云宿主机智能诊断,套餐资源池情况等等,后续会进行分享
13、问题
在使用StarRocks上,我们也发现了很多问题,例如:
【实例oom问题】:
我们发现FE 、BE会存在内存使用过高,导致FE实例oom的问题
FE的oom原因:慢SQL,元信息过大
FE的oom处理:申请更大内存的FE,配置更大的JVM参数,同时优化元信息大小,减少副本数,桶数据,分区数等
BE的oom原因:慢SQL
BE的oom处理:申请更大内存的BE,或增加BE的节点
【BE达到内存限制阈值,无法正常读写】:
BE实例的内存使用越来越大,达到了最大内存的阈值,导致正常SQL都无法执行。
Error querying database. Cause: java.sql.SQLSyntaxErrorException:
Memory of process exceed limit. Start execute plan
fragment. Used: 163680547504, Limit:
163575338803. Mem usage has exceed the limit of BE
【处理】:
快速处理:重启BE,释放内存
长期优化:
优化慢SQL
更换更大内存的BE
【版本与bug】:
目前StarRocks发版迅速,新版本的发布,会减少一些已知的bug,提高一定的性能,带来更多的功能,在StarRocks的版本上,希望大家还是适当跟随新的版本,但也不要频繁升级,这样会对业务影响比较大。
14、未来
StarRocks我们线上已经使用了近1年左右了,性能良好,运维方便,接入也比较方便,但是确实对于开发来说有一定的学习成本,例如表模型,导入方式选择,查询调优等。
希望官方能在这几点上发力,能让大家简单一点的用起来。
未来我们希望StarRocks能够逐步接入更多的业务,方便用户的分析操作。
