




PolarDB MySQL版8.0版本重磅推出弹性并行查询框架,当您的查询数据量到达一定阈值,就会自动启动并行查询框架,从而使查询耗时指数级下降。
弹性并行查询(Elastic Parallel Query,ePQ)目前支持单机并行和多机并行两种并行引擎,单机并行引擎等效于原有的并行查询,多机并行引擎支持集群内跨节点的自适应弹性调度。
PolarDB MySQL版8.0.1版本支持单机并行查询,查询时在存储层将数据分片到不同的线程上,单个节点内多个线程并行计算,将结果流水线汇总到总线程。最后总线程做简单归并返回给用户,提高查询效率。
PolarDB MySQL版8.0.2版本除了支持原有的单机并行查询,又将线性加速能力提升了一个等级,引入了多节点分布式并行计算能力,即多机并行查询。基于代价将执行计划优化为更灵活的并行执行计划,改进了单机并行查询可能存在的Leader单点瓶颈和Worker负载不均衡的问题,同时突破了单个节点在CPU、Memory、IO上的资源瓶颈。基于多节点的资源视图,自适应的调度并行计算任务,在大幅提升并行计算能力、降低查询延迟的同时,平衡了各节点的资源负载,提升集群整体的资源利用率。
弹性并行查询(Elastic Parallel Query)针对云上用户实例CPU资源利用率较低、使用不均衡的特征,充分挖掘集群中多核CPU的并行处理能力,以8核32 GB(独享规格)的PolarDB MySQL版集群版为例,示意图如下所示:

前提条件
PolarDB集群版本需为PolarDB MySQL版8.0版本且修订版本需满足如下条件:
- 单机并行:8.0.1.0.5或以上。
- 单机并行:8.0.2.1.4.1或以上。
- 多机并行:8.0.2.2.6或以上。
如何查看集群版本,请参见查询版本号。
应用场景
并行查询适用于大部分SELECT语句,例如大表查询、多表连接查询、计算量较大的查询。对于非常短的查询,效果并不显著。同时由于并行方式的多样化,可以适用于多种广泛而灵活的应用场景:
- 海量数据分析场景
在中等及更大规模数据量的情况下,分析类业务的报表查询SQL通常复杂且比较耗费时间,通过开启并行查询可以线性降低查询的响应时间。
- 资源负载不均衡场景
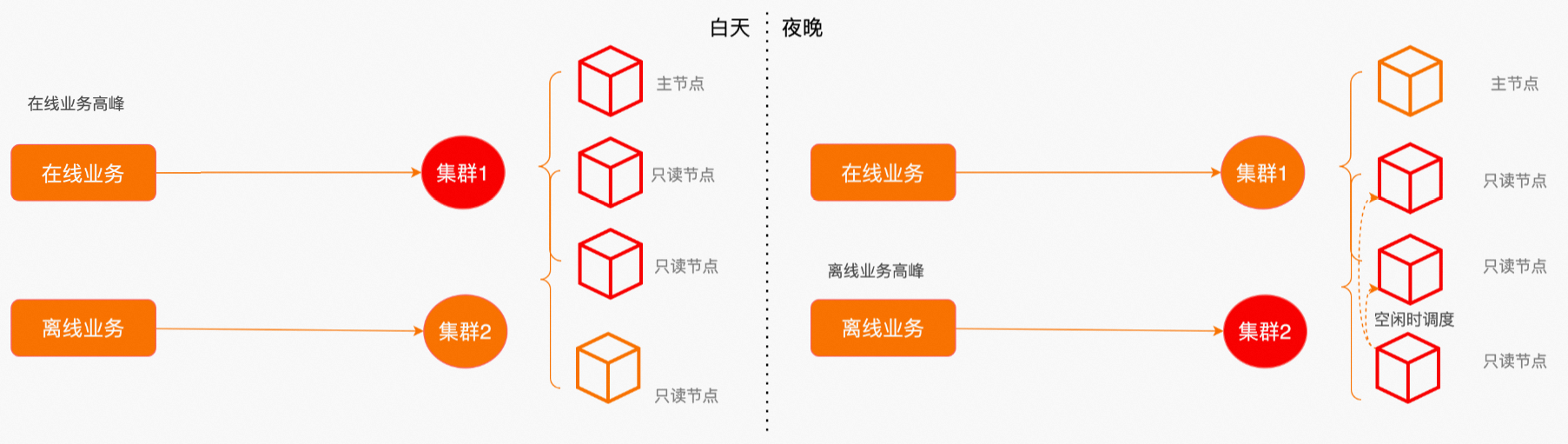
集群内的多个节点可以借助数据库代理的负载均衡能力,使每个节点的并发连接数大致相同。但由于不同查询的计算复杂度、资源使用方式各有差异,基于连接数的load balance无法完全避免节点间负载不均衡的问题。同所有分布式数据库一样,热点节点也会对PolarDB造成一定的负面影响:
- 如果RO节点过热使得查询执行过慢,可能造成RW节点无法purge undo log导致磁盘空间膨胀。
- 如果RO节点过热导致redo apply过慢,会导致RW节点无法刷脏降低RW节点的写吞吐性能。
弹性多机并行引入全局资源视图机制,并基于该视图做自适应调度,依据各节点的资源利用率和数据亲和性反馈,将查询的部分甚至全部子任务调度到有空闲资源的节点上,在保证目标并行度的基础上均衡集群资源使用率。
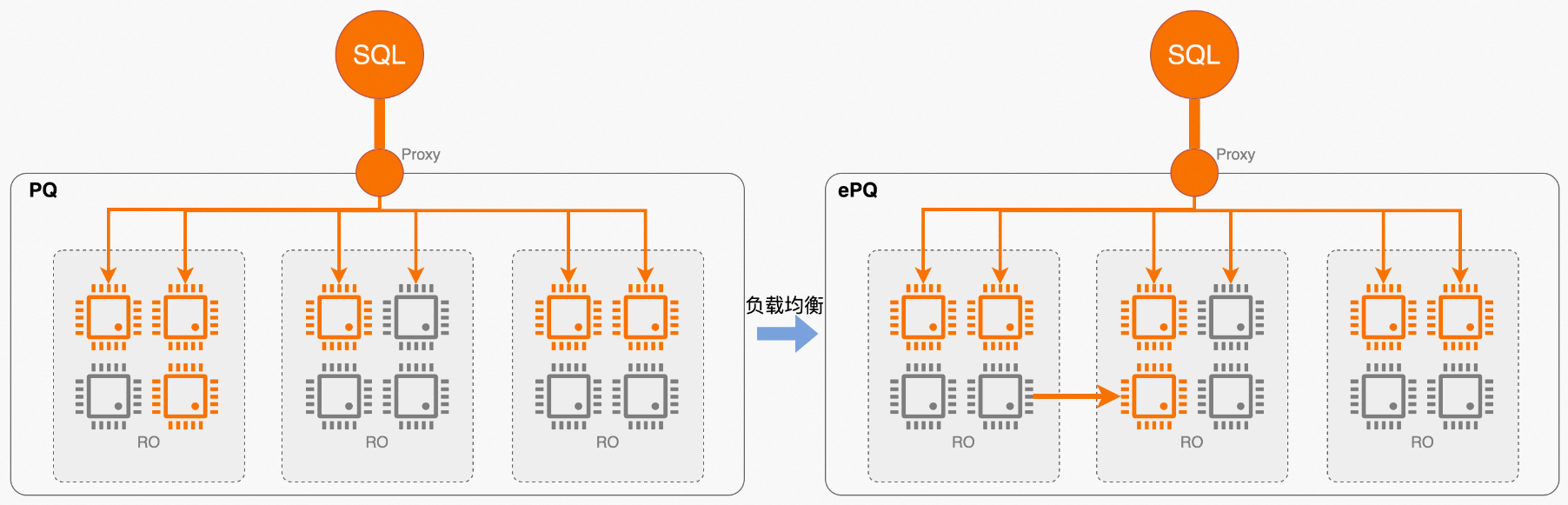
- 弹性计算场景
如前所述,弹性是云原生数据库的PolarDB的核心能力之一,自动扩、缩容功能提供了对短查询类业务非常友好的弹性能力,但之前并不适用于复杂分析类业务,因为对于大查询场景,单条查询仍无法通过增加节点实现提速。而现在开启弹性并行查询(ePQ)的集群,新扩展的节点会自动加入到集群分组中共享计算资源,弥补了之前弹性能力上的这一短板。
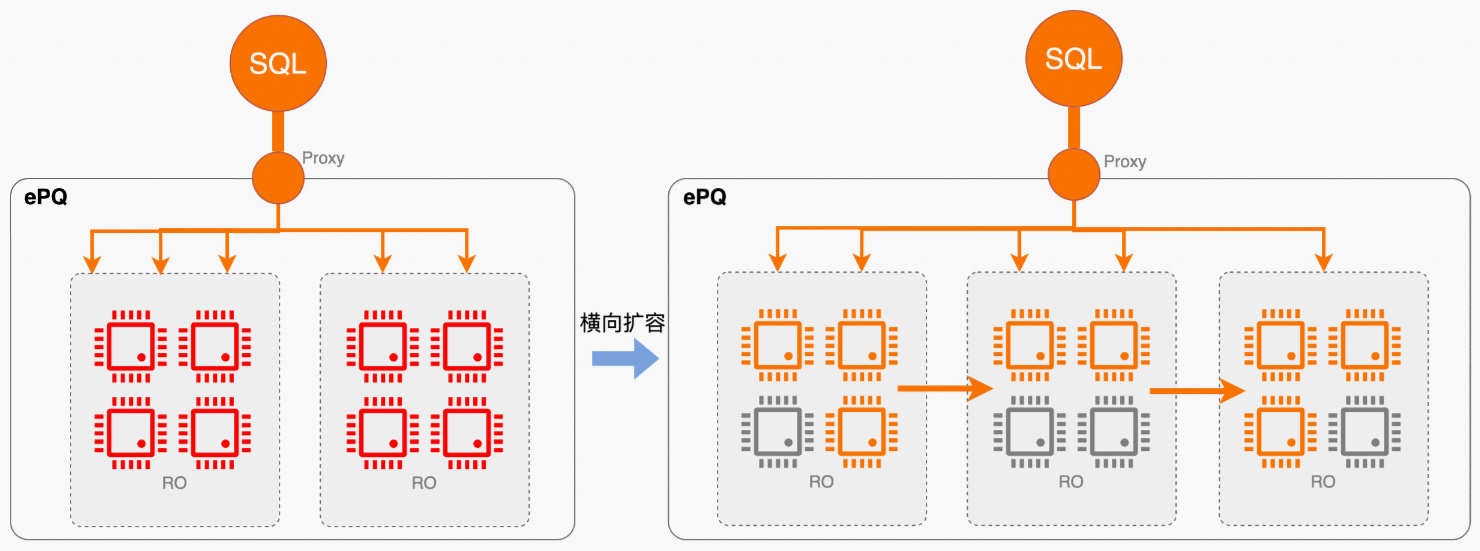
- 在离线业务混合场景
前面提到了多个子集群的物理资源隔离能力,最彻底的隔离方式是将在线交易业务和离线分析业务划定为不同节点集合,但如果用户在意成本,这种模式会显得有些浪费。因为很多情况下,在、离线业务会有不同的高、低峰特性,更经济的方式是通过错峰使用,让不同业务共享部分集群资源,但使用不同的集群地址承接业务。通过开启弹性并行,让离线业务重叠使用在线业务低峰期的空闲资源,进一步降本增效。
使用说明
说明 只读节点和主节点都支持并行查询功能。主节点上并行查询默认关闭。
- 开启并行查询
在控制台基本信息的集群地址区域,单击编辑配置,打开编辑地址配置页面,设置并行度参数及并行引擎,开启并行查询。具体操作请参见配置数据库代理的并行查询说明。
并行查询推荐设置以及相关说明如下:
- 多机并行引擎可以根据查询代价以及集群实时负载情况自适应弹性调度,建议开启多机并行以获得更优的加速效果。
- 并行度参数从低到高逐渐增加,建议不要超过CPU核数的四分之一 。例如,刚开始使用并行查询时,设置并行度参数为2,试运行一天后,如果CPU压力不大,可以持续上调;如遇到CPU压力较大,停止上调。
- 并行度为单个查询在单计算节点内最大允许同时运行的worker线程数,如果选择多机并行,单个查询最大允许同时运行的线程数=并行度×节点个数。
- 打开并行查询功能时, 需要设置innodb_adaptive_hash_index参数为OFF,innodb_adaptive_hash_index参数开启会影响并行查询的性能。
说明
- 如果控制台页面未开启并行查询,但系统参数max_parallel_degree被设置为大于0时,相当于默认开启了单机并行。
- 如果控制台和系统参数max_parallel_degree均有设置,则以控制台参数配置为准,故建议使用控制台开启并行查询。
- 关闭并行查询
在控制台基本信息的集群地址区域,单击编辑配置,打开编辑地址配置页面,可关闭并行查询,具体操作请参见配置数据库代理。
说明 控制台关闭并行查询后,需要确认系统参数max_parallel_degree同时为0,确保并行查询被完全关闭。
- 通过Hint来控制并行查询
使用Hint语法可以对单个语句进行控制,例如系统默认关闭并行查询情况下,但需要对某个高频的慢SQL查询进行加速,此时就可以使用Hint对特定SQL进行加速。详情内容请参见通过Hint控制。
- 设置阈值控制优化器是否选择并行执行
PolarDB提供了两个阈值来控制优化器是否选择并行执行,SQL语句只要满足其中任意一个条件,优化器就会考虑并行执行。
- records_threshold_for_parallelism
若优化器估算出语句中存在扫描记录数超过该阈值的表,优化器会考虑选择并行执行计划。默认值为10000。若您的业务量较小或复杂查询业务并发较低,您可以选择将该阈值设置为2000或以上。
说明 上文提到的扫描记录数是根据对应表的统计信息进行估算得出的值,可能存在一定的误差。
- cost_threshold_for_parallelism
若优化器估算查询的串行执行代价超过该阈值,优化器会考虑选择并行执行计划。默认值为50000。
- records_threshold_for_parallelism
- 设置阈值控制多机并行引擎的自适应弹性调度
PolarDB提供了两个阈值来控制是否选择多机并行,SQL语句只要满足如下任意一个条件,并行查询会考虑弹性扩展为多机并行。
- records_threshold_for_mpp
若查询语句中存在扫描记录超过该阈值的表,优化器会考虑将单机并行弹性扩展为多机并行,将并行任务调度到多个节点上同时完成计算。默认值为records_threshold_for_parallelism的N倍,N值为当前集群地址内的节点个数。
- cost_threshold_for_mpp
若查询语句的串行执行代价超过该阈值,优化器会考虑弹性扩展为多机并行。默认值为cost_threshold_for_parallelism的N倍,N值为当前集群地址内的节点个数。
- records_threshold_for_mpp
相关参数和变量
| 参数名 | 级别 | 描述 |
|---|---|---|
| max_parallel_degree | Global、Session | 单个查询的最大并行度,即并行执行的最大Worker数量。
说明 PolarDB优化器可能会对主查询和子查询分别并行执行,如果同时并行执行,它们的最大Worker数不能超过max_parallel_degree的值,整个查询使用的Worker数为主查询和子查询使用的Worker数之和。 |
| parallel_degree_policy | Global | 设置单个查询的并行度配置策略,取值范围如下:
说明 更多关于并行度配置策略的详细介绍,请参见并行度控制策略。 |
| parallel_workers_policy | session | 弹性并行策略:
|
| records_threshold_for_parallelism | Session | 若优化器估算出语句中存在扫描记录数超过该阈值的表,优化器会考虑选择并行执行计划。
说明 若您的业务量较小或复杂查询业务并发较低,您可以选择将该阈值设置为2000或以上。 |
| cost_threshold_for_parallelism | Session | 若优化器估算查询的串行执行代价超过该阈值,优化器会考虑选择并行执行计划。
|
| records_threshold_for_mpp | session | 查询语句中表扫描行数超过该阈值后,优化器会考虑选择多机并行执行方式。
|
| cost_threshold_for_mpp | session | 查询语句的串行执行代价超过该阈值后,优化器会考虑选择多机并行执行方式。
|
| 变量名 | 级别 | 描述 |
|---|---|---|
| Parallel_workers_created | Session、Global | 从Session启动开始,生成Parallel Worker的个数。 |
| Gather_records | Session、Global | Gather记录总数。 |
| PQ_refused_over_total_workers | Session、Global | 由于总Worker数限制没有启用并行的查询数。 |
| PQ_refused_over_max_queuing_time | Session、Global | 由于并行查询排队超时没有启动并行的查询数。 |
| Total_running_parallel_workers | Global | 当前正在运行的Parallel Worker的数目。 |
性能指标
本次测试将使用TPC-H生成100 GB数据来测试PolarDB MySQL版8.0版本集群的性能指标。测试用的PolarDB集群规格为32核256 GB(独享规格)×4节点,单节点并行度max_parallel_degree分别设置为32和0,对比PolarDB串行执行、单节点32并行度执行、4节点128并行度执行的性能数据,具体测试步骤请参见并行查询性能。
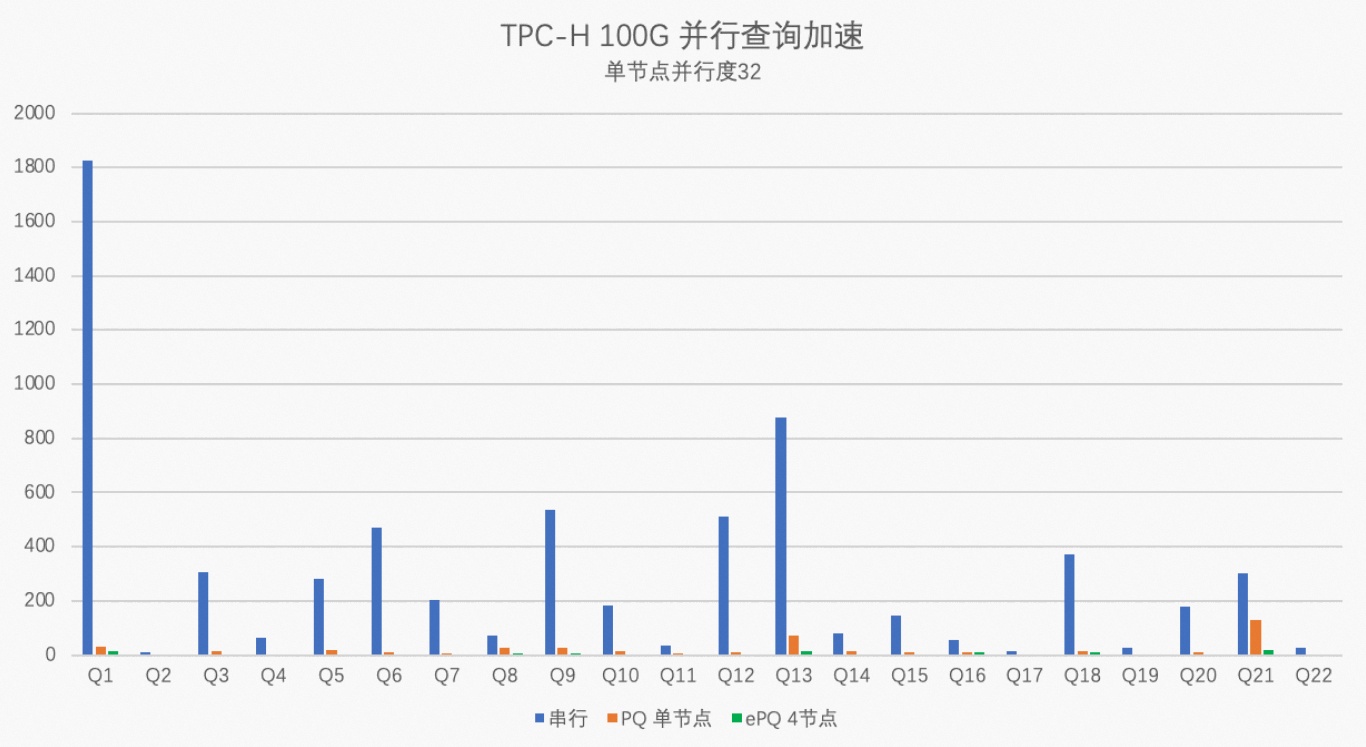
通过以上测试结果图得出,TPC-H中100%的SQL可以被加速,平均加速比在17倍,最高加速比56倍。
开启多机并行后,平均加速比在59倍,最高加速比159倍。
说明 本文的TPC-H的实现基于TPC-H的基准测试,并不能与已发布的TPC-H基准测试结果相比较,本文中的测试并不符合TPC-H基准测试的所有要求。
并行执行EXPLAIN
更多关于EXPLAIN执行计划输出中与并行查询相关的内容,请参见并行查询EXPLAIN。
相关概念
- 并行扫描
在并行扫描中,每个Worker并行独立扫描数据表中的数据。Worker扫描产生的中间结果集将会返回给Leader线程,Leader线程通过Gather操作收集产生的中间结果,并将所有结果汇总返回到客户端。
- 多表并行连接
并行查询会将多表连接操作完整的下推到Worker上去执行。PolarDB优化器只会选择一个自认为最优的表进行并行扫描,而除了该表外,其他表都是一般扫描。每个Worker会将连接结果集返回给Leader线程,Leader线程通过Gather操作进行汇总,最后将结果返回给客户端。
- 并行排序
PolarDB优化器会根据查询情况,将ORDER BY下推到每个Worker里执行,每个Worker将排序后的结果返回给Leader,Leader通过Gather Merge Sort操作进行归并排序,最后将排序结果返回到客户端。
- 并行分组
PolarDB优化器会根据查询情况,将GROUP BY下推到Worker上去并行执行。每个Worker负责部分数据的GROUP BY。Worker会将GROUP BY的中间结果返回给Leader,Leader通过Gather操作汇总所有数据。这里PolarDB优化器会根据查询计划情况来自动识别是否需要再次在Leader上进行GROUP BY。例如,如果GROUP BY使用了Loose Index Scan,Leader上将不会进行再次GROUP BY;否则Leader会再次进行GROUP BY操作,然后把最终结果返回到客户端。
- 并行聚集
并行查询执行聚集函数下推到Worker上并行执行。并行聚集将基于优化器代价,选择串行执行、一阶段聚集或者两阶段聚集。
- 一阶段聚集:将聚集操作分发到Worker中,每个worker包含对应分组中的全部数据。因此无需第二阶段的汇总聚集计算,各个Worker直接计算得到所拥有分组的最终聚集结果,避免Leader再次聚集。
- 两阶段聚集:在第一次,参与并行查询部分的每个Worker执行聚集步骤;第二次,Gather或Gather Merge节点将每个Worker产生的结果汇总到Leader。最后,Leader会将所有Worker的结果再次进行聚集得到最终结果。
- 两阶段shuffle聚集:在第一次,参与并行查询部分的每个Worker执行聚集步骤;第二次,Repartition节点将每个Worker产生的结果,按照分组列分发到多个worker,worker并行完成最终聚集计算。最后,聚集结果汇总到Leader。
- 并行窗口函数
PolarDB优化器会根据代价计算,将Window Function分发到Worker上并行执行,每个Worker负责部分数据的计算,分发方式根据Window Function中Partition by子句的key来决定。因此如果Window Function中没有使用Partition by子句,只能串行完成计算。但如果后续计算仍可以并行,会根据代价,重新将后续计算任务分发到多个Worker上执行,保证最大程度的并行化。
- 子查询支持
在并行查询下子查询有四种执行策略:
- 在Leader线程中串行执行
当子查询不可并行执行时,例如2个表JOIN,在JOIN条件上引用了用户的函数,此时子查询会在Leader线程上进行串行查询。
- 在Leader上并行执行(Leader会启动另一组Worker)
生成并行计划后,在Leader上执行的计划包含有支持并行执行的子查询,但这些子查询不能提前并行执行(即不能采用Shared access)。例如,当前如果子查询中包括window function,子查询就不能采用Shared access策略。
- Shared access
生成并行计划后,Worker的执行计划引用了可并行执行的子查询,PolarDB优化器会选择先提前并行执行这些子查询,让Worker可以直接访问这些子查询的结果。
- Pushed down
生成并行计划后,Worker执行计划引用了相关子查询,这些子查询会被整体推送到Worker上执行。
- 在Leader线程中串行执行

