




字符集分类
在Oracle中定义的字符集不能超过2个:
- 数据库字符集(nls_character)用于CHAR, VARCHAR2, LONG和CLOB数据类型中的数据;
- 数据库国家字符集(nls_nchar_character)用于存储在NCHAR, NVARCHAR2和NCLOB数据类型中的数据;
使用如下sql检查当前数据库的字符集
SQL> select * from nls_database_parameters where PARAMETER in ('NLS_CHARACTERSET','NLS_NCHAR_CHARACTERSET'); PARAMETER VALUE ------------------------------ -------------------- NLS_CHARACTERSET AL32UTF8 NLS_NCHAR_CHARACTERSET AL16UTF16复制
使用如下sql检查当前数据库使用的字符集
SQL> select distinct(nls_charset_name(charsetid)) CHARACTERSET, decode(type#, 1, decode(charsetform, 1, 'VARCHAR2', 2, 'NVARCHAR2','UNKNOWN'), 9, decode(charsetform, 1, 'VARCHAR', 2, 'NCHAR VARYING', 'UNKNOWN'), 96, decode(charsetform, 1, 'CHAR', 2, 'NCHAR', 'UNKNOWN'), 8, decode(charsetform, 1, 'LONG', 'UNKNOWN'), 112, decode(charsetform, 1, 'CLOB', 2, 'NCLOB', 'UNKNOWN')) TYPES_USED_IN from sys.col$ where charsetform in (1,2) and type# in (1, 8, 9, 96, 112) order by CHARACTERSET, TYPES_USED_IN; CHARACTERSET TYPES_USED_IN ---------------------------------------- ------------- AL16UTF16 NCHAR AL16UTF16 NCLOB AL16UTF16 NVARCHAR2 AL32UTF8 CHAR AL32UTF8 CLOB AL32UTF8 LONG AL32UTF8 VARCHAR2 7 rows selected.复制
数据库字符集
Oracle建议使用AL32UTF8字符集。是Unicode字符集。
统一码(Unicode),也叫万国码、单一码,由统一码联盟开发,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。
统一码是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
AL32UTF8:
- AL32UTF8是Oracle数据库中的一种字符编码字符集。
- 它是一种可变长度编码,使用1至4个字节来表示不同的Unicode字符。
- 大多数亚洲文字的字符用3个字节表示。补充字符用4个字节表示。
- AL32UTF8能够表示几乎所有的Unicode字符,包括各种语言的字符、符号和特殊字符。
- AL32UTF8在存储数据时相对节省空间,特别适用于包含大量非英文字符的数据。
- 它是Oracle数据库中多语言支持的常用字符集之一。
NLS_LANG
NLS_LANG是用来让Oracle知道你的客户端操作系统正在使用什么字符集,以便Oracle可以做(如果需要)从客户端字符集到数据库字符集的转换。
国家字符集
NLS_NCHAR_CHARACTERSET是在创建数据库时定义的。
从9i开始,NLS_NCHAR_CHARACTERSET只能有2个值:UTF8或AL16UTF16,它们都是Unicode字符集。
如果没有指定,NLS_NCHAR_CHARACTERSET默认为AL16UTF16,这是推荐值。
N-types在编程语言和应用层通常只有很少的支持。使用N-types需要客户端应用/程序的明确支持。
AL16UTF16:
- AL16UTF16也是Oracle数据库中的一种字符编码字符集。
- UTF-16是Unicode的16位编码形式。在UTF-16中,一个字符可以由一个16位整数值(两个字节)或两个16位整数值(四个字节)表示。来自基本多语言平面的所有字符都用两个字节表示,这些字符是日常文本中使用最多的字符。补充字符用四个字节表示。编码单个补充字符的两个代码单元(整数值)称为代理对。
- AL16UTF16能够表示全球范围内的字符,包括各种语言的字符和符号。
- AL16UTF16适用于需要在数据库中保留完整的Unicode字符表示的场景。
从存储空间而言:
如果你有很多非西方的数据(西里尔文、中文、日文、印地语……),那么对这些列使用N-types是有利的,因为这些字符将在UTF8中使用3个字节,在AL16UTF16中使用2个字节。
西方数据(英语、法语、西班牙语、荷兰语、德语、葡萄牙语等)UTF8 / AL32UTF8在大多数情况下使用的磁盘空间比AL16UTF16少。
国家字符集的使用
使用N-types,在编码时确实使用(N’…’)语法,以便通过在字母前面加上 ‘N’ 前缀来表示是使用国家字符集的:
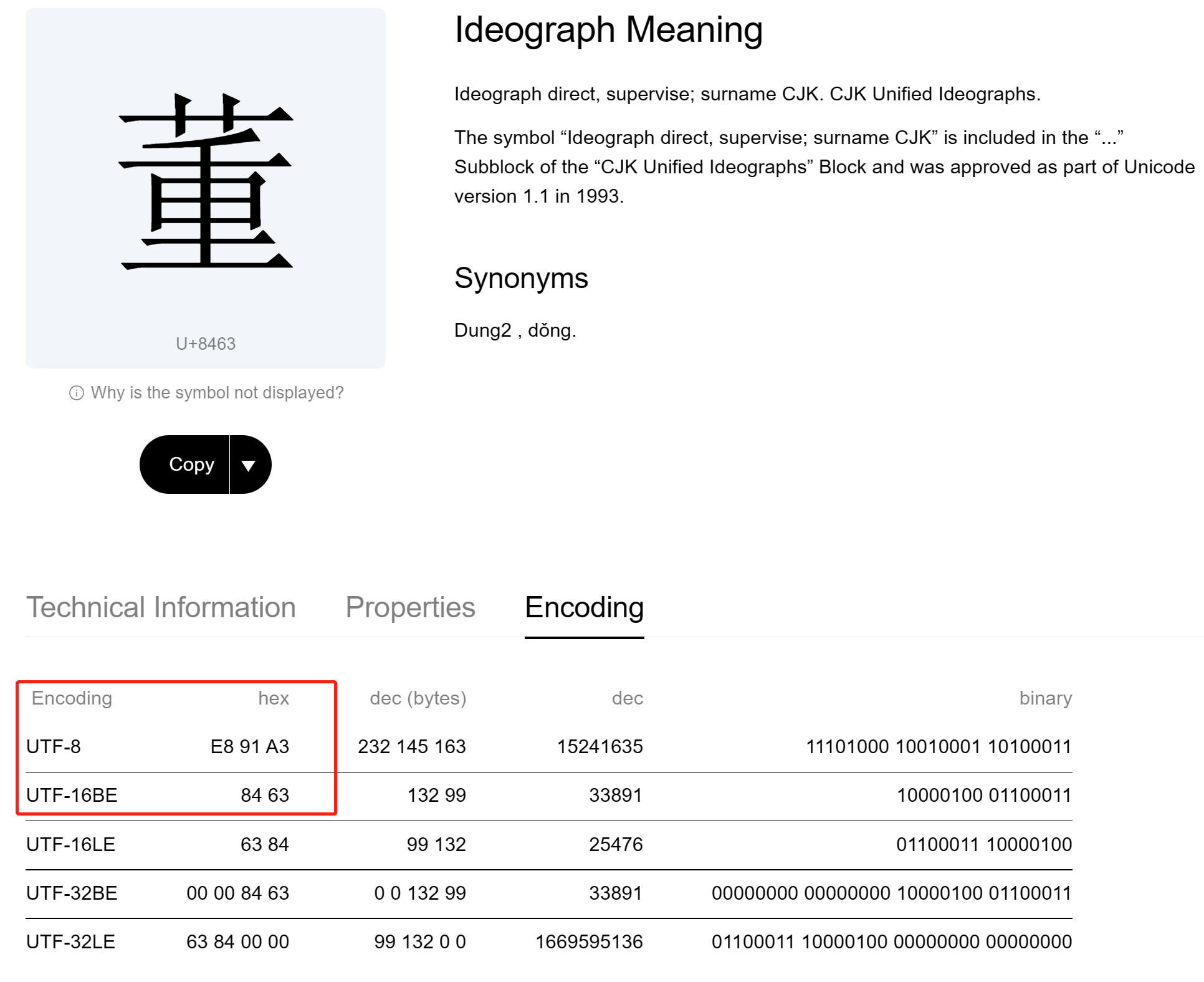
create table test(a varchar2(100),b nvarchar2(100)); insert into test values('董',N'董'); commit; --验证 SQL> select a,b,dump(a,1016),dump(b,1016) from test; A B DUMP(A,1016) DUMP(B,1016) ---------- ---------- -------------------------------------------------- -------------------------------------------------- 董 董 Typ=1 Len=3 CharacterSet=AL32UTF8: e8,91,a3 Typ=1 Len=2 CharacterSet=AL16UTF16: 84,63 SQL>复制
可以看到AL32UTF8中汉字‘董’占用3个字节,AL16UTF16中汉字‘董’占用2个字节。
因此,最好使用AL16UTF16作为NLS_NCHAR_CHARACTERSET,这将使存储的汉字比UTF8字符集更多。
可以通过如下网站查看unicode字符集对应编码:
https://symbl.cc/en/
Oracle中UTF8和AL32UTF8的一些区别
UTF8和AL32UTF8都是 UTF-8 编码的字符集;
UTF8(Oracle8 和 8i 中引入)的设计没有补充字符的概念,因此 UTF8 的每个字符最多为 3 个字节;
AL32UTF8(Oracle9i 引入) 提供了对新定义的补充字符的支持。所有补充字符都以 4 个字节的方式存储;
Emoji表情插入数据库测试
SQL> insert into test values('😂',N'😂'); 1 row created. SQL> commit ; Commit complete. --结果展示 SQL> select a,b,dump(a,1016),dump(b,1016) from test; A B DUMP(A,1016) DUMP(B,1016) ---------- ---------- -------------------------------------------------- -------------------------------------------------- 😂 😂 Typ=1 Len=4 CharacterSet=AL32UTF8: f0,9f,98,82 Typ=1 Len=4 CharacterSet=AL16UTF16: d8,3d,de,2 SQL>复制
生僻字插入数据库测试
SQL> insert into test values('囮',N'囮'); insert into test values('𠁃',N'𠁃'); commit; SQL> select a,b,dump(a,1016),dump(b,1016) from test; A B DUMP(A,1016) DUMP(B,1016) ---------- ---------- -------------------------------------------------- -------------------------------------------------- 囮 囮 Typ=1 Len=3 CharacterSet=AL32UTF8: e5,9b,ae Typ=1 Len=2 CharacterSet=AL16UTF16: 56,ee 𠁃 𠁃 Typ=1 Len=4 CharacterSet=AL32UTF8: f0,a0,81,83 Typ=1 Len=4 CharacterSet=AL16UTF16: d8,40,dc,43 SQL>复制
ASCII国家字符集形式插入数据库测试
说明AL16UTF16字符集最少占用2个字节
SQL> insert into test values('A',N'A'); commit; SQL> select a,b,dump(a,1016),dump(b,1016) from test; A B DUMP(A,1016) DUMP(B,1016) ---------- ---------- -------------------------------------------------- -------------------------------------------------- A A Typ=1 Len=1 CharacterSet=AL32UTF8: 41 Typ=1 Len=2 CharacterSet=AL16UTF16: 0,41 SQL>复制
参考文档
https://docs.oracle.com/en/database/oracle/oracle-database/21/nlspg/supporting-multilingual-databases-with-unicode.html#GUID-98BD4E64-99AE-4AD8-8CAD-EE438D988318
The National Character Set ( NLS_NCHAR_CHARACTERSET ) in Oracle 9i, 10g , 11g and 12c (Doc ID 276914.1)
Unicode Character Sets In The Oracle Database (Doc ID 260893.1)
订阅号:DongDB手记
墨天轮:https://www.modb.pro/u/231198





