




今天朋友圈里面有个瓜,有人晒了一张如下的图:
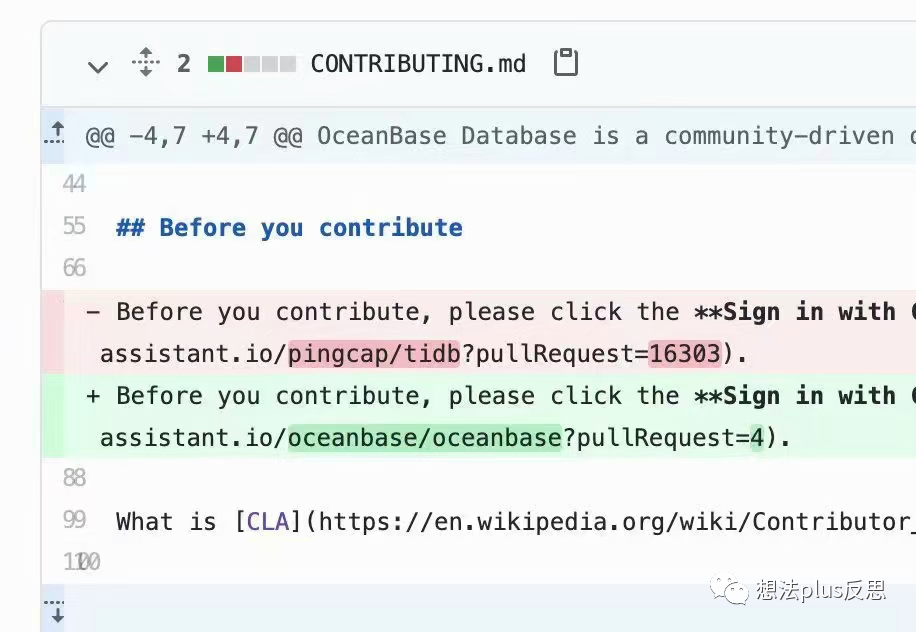
原来是阿里开源了数据库OceanBase,在OceanBase的 how to contribute(https://github.com/oceanbase/oceanbase/blob/master/CONTRIBUTING.md)的说明里面,有人发现原来是拷贝的pingcap的Tidb的“how to contribute”, 因为这是两个很近的NewSQL数据库,瓜田李下,大家不由得浮想联翩了。
OceanBase和Tidb都把目标客户放在金融客户上,在他们的项目首页上面,应用场景都重点放的金融客户,因为金融客户对数据的高可用性和一致性要求是比较高的,金融客户可以使用的话,其他类型的客户也没有问题。
翻一翻他们的代码,可以发现,OceanBase基本上是C++和C写的,C++占代码的87.6%,C占10.8%;而TiDB基本上都是用Go写的,所以从代码层面,如果想要直接拷贝应该是不可能的。
再来看看他们的架构。
从大的思想上来看,OceanBase和TiDB都是计算和存储分离的,底层的存储都是多副本的。副本之间的数据同步是通过复制事务日志来实现。这种复制如果以三副本架构为例,每个表的三副本角色有一个Leader副本和两个Follower副本。一般只有Leader节点提供写入和读取。Follower 负责同步 Leader 发来的日志(Log)。不同之处是,OceanBase的复制是通过Paxos协议来实现的,TiDB的复制是通过Raft协议来实现的。一般来说,Paxos协议的实现要比Raft难得多。
在存储的实现上,两者也很相同,TiDB的底层存储取了一个巧,直接使用的RocksDB来实现的,因为TiDB觉得实现一个高效,精巧的底层存储是很困难的。RocksDB的底层实现又是基于MemTable和LSM-Tree来实现的,这两种数据结构的思想是把对磁盘的随机写改为顺序写,每次都是向日志文件里面append内容,但是不修改内容,然后后台有线程定时合并和压缩日志文件,从而达到高效写的目的。阿里的OceanBase数据库的存储引擎采用了基于 LSM-Tree 的架构,把基线数据和增量数据分别保存在磁盘(SSTable)和内存(MemTable)中,具备读写分离的特点。对数据的修改都是增量数据,只写内存,然后flush到磁盘中去。
虽然存储的思想类似,但是在很多细节的处理上是不一样的,例如Oceanbase加了很多缓存的处理,让数据的访问更为高效等等。
在计算引擎的实现上,两者差别更多了,在大的方面,两者都和传统数据库类似,整个计算引擎分为解析器、优化器、执行器三部分。当 SQL 引擎接受到了 SQL 请求后,经过语法解析、语义分析、查询重写、查询优化等一系列过程后,再由执行器来负责执行。但是作为NewSQL,查询优化器会依据数据的分布信息生成分布式的执行计划。如果查询涉及的数据在多台服务器,需要走分布式计划。除了这些大的思想一样,在解析,优化,执行的具体实现方面,两者相差还是蛮多的。
总之,从实现的难度上来讲,OceanBase应该难得多,走的是一条Hardway,但是这样做的好处是整个stack都可以自己控制了,后面的持续优化和改进都可以自己掌控。TiDB整个技术stack相对而言容易一些,可控性就没有OceanBase那么强了。
所以,从我的观点来看,OceanBase是绝对不可能抄袭TiDB,但是两者都是优秀的国产软件,在实现思想上还是有很多相同之处的,两者都是借鉴google的Spanner的设计思想的。
百花争艳才是春,愿国产软件越来越好。



