




Elasticsearch 是一个基于 Lucene 库分布式、可扩展的搜索引擎,提供近实时的搜索和分析功能。
分片
为了支持对海量数据的存储和查询,Elasticsearch 引入分片的概念,一个索引被分成多个分片,一个索引被分成多个分片,每个分片都由一个 Primary shard 和任意多个 Replica shard 组成,它们都是功能齐全的 Lucene 实例。
主分片
前文提到过,Elasticsearch 集群中每个节点都是 Coordinating node(协调节点),当客户端发起请求,接收到请求的节点会根据路由算法,将请求路由到目标节点上,数据写入到路由的主分片上。
# 路由算法shard = hash(routing) % number_of_primary_shards复制
routing 是一个可变值,默认是文档 ID ,也可以设置成一个自定义的值。routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards(主分片的数量)后得到余数。这个在 0 到 number_of_primary_shards 之间的余数,就是所寻求的文档所在分片的位置。这也是为什么要在创建索引的时候就确定好主分片的数量并且永远不会改变这个数量,因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
副本分片
副本分片只是主分片的一个副本,它可以防止硬件故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的 shard 取回文档。每个主分片都有任意多个副本分片,当主分片异常时,副本可以提供数据的查询等操作。主分片和对应的副本分片不会在同一个节点上的,所以副本分片数的最大值是 N -1(其中 N 为节点数)。
当索引创建完成的时候,主分片的数量就固定了,但是复制分片的数量可以随时调整,根据需求扩大或者缩小规模。
对文档的新建、索引和删除请求都是写操作,必须在主分片上面完成之后才能被复制到相关的副本分片,Elasticsearch 为了提高写入的能力这个过程是并发写的,同时为了解决并发写的过程中数据冲突的问题,Elasticsearch 通过乐观锁的方式,每个文档都有一个 _version (版本)号,当文档被修改时版本号递增。一旦所有的副本分片都报告写成功才会向协调节点报告成功,协调节点向客户端报告成功。
segment
Elasticsearch 中写入磁盘的倒排索引是不可变的,这意味着不会去修改已经写入倒排索引的某一行文档记录本身(只会标记删除),也就不存在多个程序同时尝试修改,也就不需要锁。由于倒排索引的不可变性,一旦被读入文件系统缓存,只要文件系统缓存留有足够的空间,那么大部分读请求会直接访问内存。而且不可变的倒排索引还便于压缩数据,减少磁盘 IO 和占用系统缓存内存的大小。
倒排索引的不可变性带来的有点是显而易见的,但是如果一个分片的数据都写入到一个倒排索引中,就只有在新的索引准备好了,再替换旧的索引,最近的修改才可以被检索,这无疑是低效的。因此,不应该是重写整个倒排索引,而是增加额外的索引反映最近的变化,于是产生了 segment(段),分片下的索引文件被拆分为多个子文件,每个子文件叫作 segment , 每一个 segment 都是一个倒排索引,并且具有不变性,一旦索引的数据被写入硬盘,就不可再修改。
倒排索引的不可变也存在缺点。旧数据的更新被不会马上删除、释放空间,而是在 .del 文件中被标记为删除,只有在 segment 合并时才会真正地删除,这会导致浪费大量空间。对于查询请求还要排除被标记删除的数据,这会增加查询的负担。通过 segment 来存储最近的变化,当 segment 数量太多会对服务器资源(如文件句柄)消耗很大。
写入过程
当写入请求路由到对应节点的主分片上,主分片会执行下面写入过程:
先判断操作类型,将 Update 操作转换为 Index 和 Delete 操作。
解析操作和文档字段属性,对于新增字段会根据 dynamic mapping 或 dynamic template 生成对应的 mapping,如果 mapping 中有 dynamic mapping 相关设置则按设置处理,如忽略或抛出异常。
从 SequcenceNumberService 获取一个 sequenceID 和 version。SequcenID 用于初始化 LocalCheckPoint,version 是根据当前 version+1 用于防止并发写导致数据不一致。
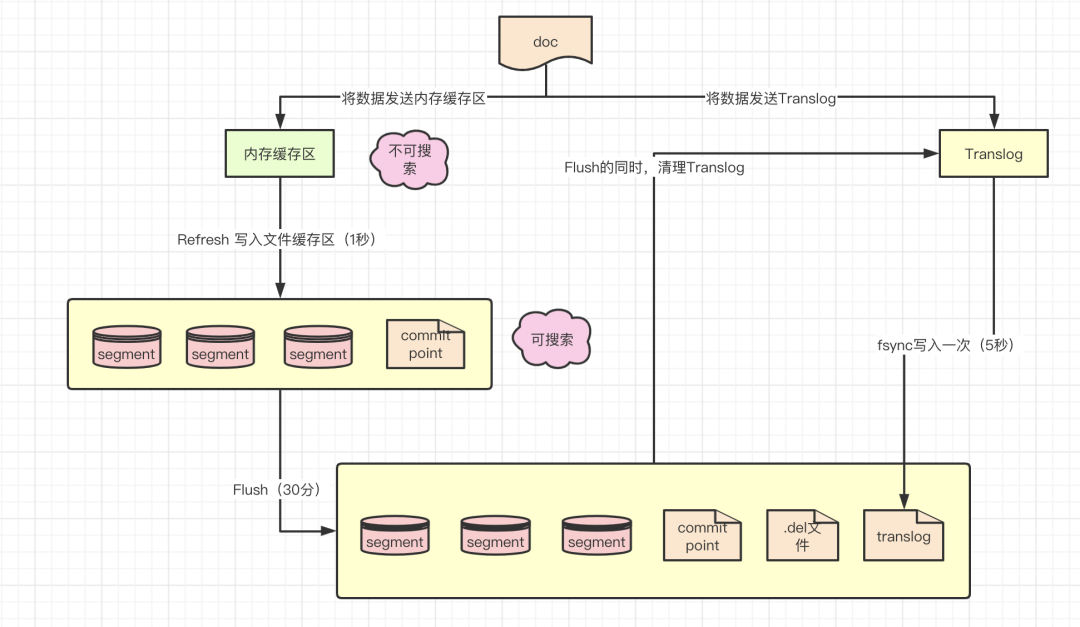
将数据写入 memory buffer 和内存中的 translog 日志文件(这个阶段使用的内存是指 JVM 内存空间,在 memory buffer 中的数据无法用于全文检索,内存中的 translog 数据可以通过 GetById 的方式获取)。
默认每个 1s 或 memory buffer 快满了,数据会从 memory buffer 中 refresh 到 filesystem buffer 中,生成 segment 文件,一旦生成 segment 文件数据就可以用于全文检索。在 Elasticsearch 2.x 版本之前,默认每隔 5s 将内存中 tranlog 中数据 flush 到磁盘,从 Elasticsearch 2.x 版本开始,默认每次请求都会执行 flush 操作。当 translog 达到一定长度的时候或者到一定时间(30分钟),就会触发 commit 操作,commit 操作会将内存中 segment 和 tranlog 中的数据结合写入磁盘中的 segment 文件,并清除缓存和 tranlog 文件,生成新提交点。
重新构造 bulkrequest 并发送给副本分片,等待副本分片返回,这里需要等待所有的副本分片返回。(如果某个副本分片执行失败,则主分片会给主节点发请求 remove 该副本分片。)
当所有的副本分片返回请求时,主分片更新 LocalCheckPoint 并响应客户端。
Elasticsearch 的删除是在 .del 文件中将文档记录标记为删除,如果是更新则是在删除的基础上重新写入一条数据。它们并不会立即删除释放空间,这会浪费大量存储空间。Elasticsearch 通过后台合并 segment 解决这个问题,小 segment 被合并成大 segment。已经被标记删除的文档不会从旧的 segment 复制到新 segment 中。合并的过程也不会中断索引和搜索,但是会消耗很多 IO 和 CPU。
查询过程
查询是更为复杂的执行模型,因为我们不知道查询会命中哪些文档,不知道这些文档可能在哪些分片上。一个搜索请求必须查询所有分片来确定它们是否含有匹配的文档。但是找到所有的匹配文档仅仅完成事情的一半,在查询接口返回一个结果之前,多分片中的结果必须聚合成单个结果集。因此,Elasticsearch 的查询由两个基本阶段组成:Query 和 Fetch。
Query
Query 阶段:Search 请求会广播到索引中每一个分片拷贝(主分片或者副本分片),每个分片在本地执行 Search 请求并构建一个匹配文档的优先队列。一个优先队列仅仅是一个存有 top-N 匹配文档的有序列表,优先队列的大小取决于分页参数 from 和 size 。
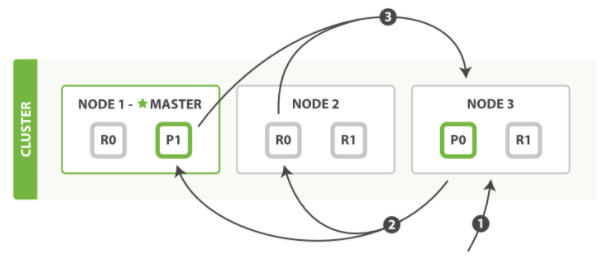
Query 阶段包含以下三个步骤:
客户端发送一个 Search 请求到 Node 3 , Node 3 会创建一个大小为 from + size 的空优先队列。
Node 3 将 Search 请求转发到索引的每个主分片或副本分片中。每个分片在本地执行 Search 请求并添加结果到大小为 from + size 的本地有序优先队列中。
每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点,也就是 Node 3 ,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
Fetch
Query 阶段返回哪些文档满足搜索请求,Fetch 阶段负责取回这些文档。
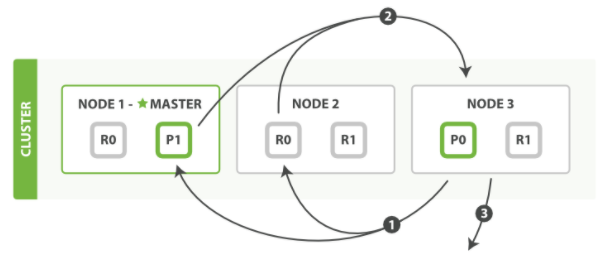
Fetch 阶段由以下步骤构成:
协调节点根据 Query 阶段产生的结果列表辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。
每个分片加载并丰富文档,如果有需要的话返回文档给协调节点。
一旦所有的文档都被取回了,协调节点返回结果给客户端。
注:分片数量越多,需要汇总的数据越多,协调节点压力越大。尤其是深度分页,效率会明显降低。
查询方式
Elasticsearch 的查询过程涉及两种查询方式:
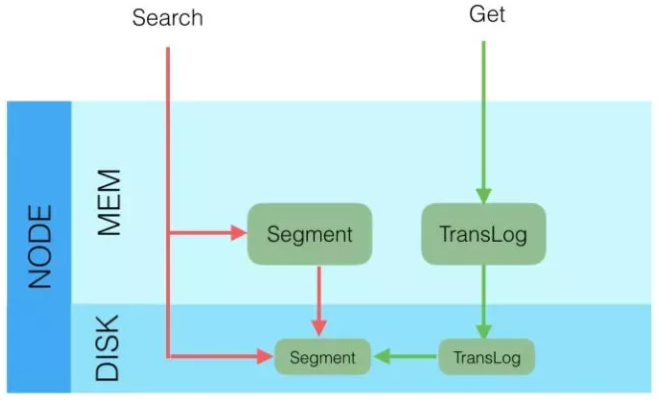
Search:根据 Query 去匹配文档记录。
Get:根据文档 ID 查询文档记录。
Search
根据 Query 查询的 Search 请求,匹配的是装配好的 segment 文件,所以是近实时的。它分为四类查询模式:
QUERY_AND_FETCH 查询模式,协调节点向所有分片发送查询请求,各分片将文档的相似度得分和文档的详细信息一起返回。然后,协调节点进行重新排序,再取出需要返回给客户端的数据,将其返回给客户端。由于只需要在分片中查询一次,所以性能是最好的。
QUERY_THEN_FETCH 是默认的查询模式。第 1 步,先向所有的分片发请求,各分片只返回文档的相似度得分和文档 ID,然后协调节点按照各分片返回的分数进行重新排序和排名,再取出需要返回给客户端的 size 个文档 ID。第 2 步,在相关的分片中取出文档的详细信息并返回给用户。
DFS_QUERY_THEN_FETCH 与 QUERY_THEN_FETCH 类似,但它包含一个额外的阶段:在初始查询中执行全局的词频计算,以使得更精确地打分,从而让查询结果更相关。QUERY_THEN_FETCH 使用的是分片内部的词频信息,而 DFS_QUERY_THEN_FETCH 使用访问公共的词频信息,所以相比 QUERY_THEN_FETCH 性能更低。
DFS_QUERY_AND_FETCH 与 QUERY_AND_FETCH 类似,区别也在于使用的是全局的词频。
GET
区别于根据 Query 查询的 Search 请求,根据文档 ID 查询的 GET 请求获取到的是实时的内容。在 Elasticsearch 5.x 版本之前,GET 的实时查询依赖于从 translog 中读取实现,在 Elasticsearch 5.x 版本之后的版本改为 refresh,因此系统对实时读取的支持会对写入速度有负面影响。
文章同步 github。
地址:github.com/lazecoding/Note/blob/main/note/articles/es/执行过程.md
