






郭富杰
数据技术处
GaussDB数据库调优介绍
分布式查询处理是MPPDB中最核心的技术,关键在于尽量降低查询中节点之间的数据流动,以提升查询效率。GaussDB 200为达成高性能数据分析目标,实现了一套高性能的分布式执行引擎,执行引擎以SQL引擎生成的执行计划为输入,将元组按执行计划的要求进行加工并将结果返回给客户端。
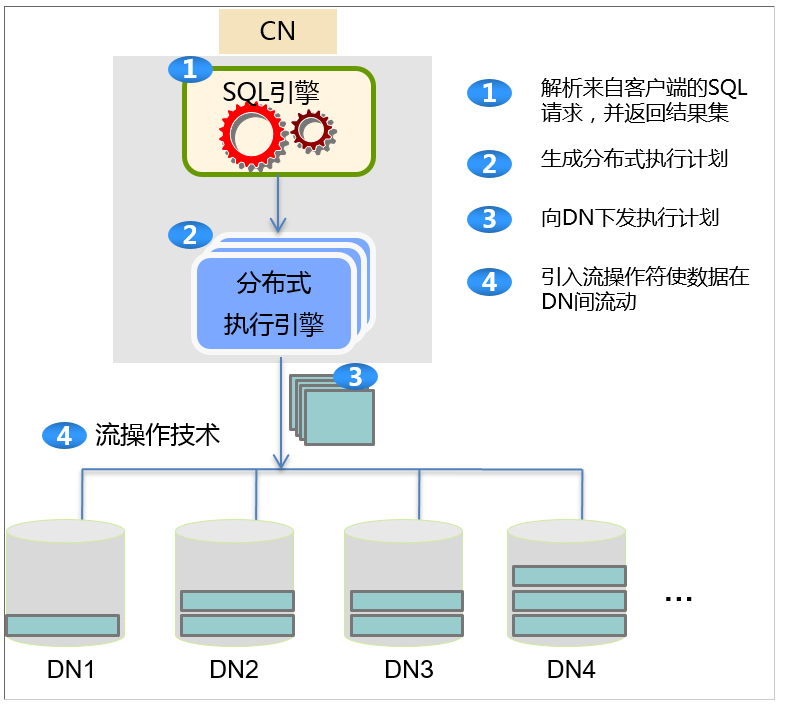
图一 分布式查询流程图
运行在CN上的分布式执行引擎实现了分布式执行调度的功能。节点内引入新的执行算子来支撑数据在计算节点之间的流动,这些新的执行算子称其为数据流操作符,根据数据流的输入、输出关系,可以细分为聚合流(Gather)、广播流(Broadcast)和重分布流(Redistribution)。聚合流将数据从多个查询片段聚合到一个。广播流将数据从一个查询片段的数据向多个传输。重分布流则将多个查询片段的数据,按照一定规则重组后向多个传输。
跨计算节点的数据传输依赖于查询分析阶段根据数据分布以及代价模型构建的数据流动拓扑结构,并根据此结构来建立节点之间的网络连接,驱动数据流动于此拓扑结构之上。
Gauss200优化器是典型的基于代价的优化 (Cost-Based Optimization,简称CBO)。在这种优化器模型下,数据库根据表的元组数、字段宽度、NULL记录比率、distinct值、MCV值、HB值等表的特征值,以及一定的代价计算模型,计算出每一个执行步骤的不同执行方式的输出元组数和执行代价(cost),进而选出整体执行代价最小/首元组返回代价最小的执行方式进行执行。这些特征值就是统计信息。可以看出统计信息是查询优化的核心输入,准确的统计信息将帮助规划器选择最合适的查询规划,一般来说我们通过analyze语法收集整个表或者表的若干个字段的统计信息,周期性地运行ANALYZE,或者在对表的大部分内容做了更改之后立即运行它。
Gauss200 OLAP的总体性能调优思路为性能瓶颈点分析、关键参数调整以及SQL调优。在调优过程中,通过系统资源、吞吐量、负载等因素来帮助定位和分析性能问题,使系统性能达到可接受的范围。因此,调优人员应对系统软件架构、软硬件配置、数据库配置参数、并发控制、查询处理和数据库应用有广泛而深刻的理解。关键参数调整在数据库配置时基本已经按照最优配置,日常开发主要涉及SQL端调优。
SQL调优只有一条准则“资源利用最大化”,这里的资源主要是指CPU、内存、磁盘IO、网络IO这四种资源,所有的调优手段都是围绕资源使用开展的。所谓资源利用最大化有两层含义:首先,SQL语句应当尽量高效,节省资源开销。这条准则的含义是以最小的代价实现最大的效益。比如做典型点查询的时候,我们可以用seqscan+filter(即读取每一条元组和点查询条件进行匹配)实现,也可以通过indexscan实现,显然indexscan可以以更小的代价实现相同的效果。第二,SQL语句应当充分利用资源。这一层的含义是SQL语句应当尽量充分利用资源,实现性能的极致。比如在sort的时候,我们可以调到work_mem尽量保证数据不下盘,让数据在内存中排序,从而提升排序效率,保证性能的最大收益。
SQL调优分为静态调优和执行态调优两个阶段。静态调优阶段我们根据硬件资源和客户的业务特征确定集群部署方案、表定义。一般来说这一部分结果比较简单,而且一旦确定,后续改动的代价会比较大。执行态调优阶段需要我们根据SQL语句执行的实际情况采取措施干预SQL的具体执行计划方式来提升性能。一般包括SQL改写、guc参数干预执行计划等手段。一个端到端的性能调优过程可以用以下流程图二表示:
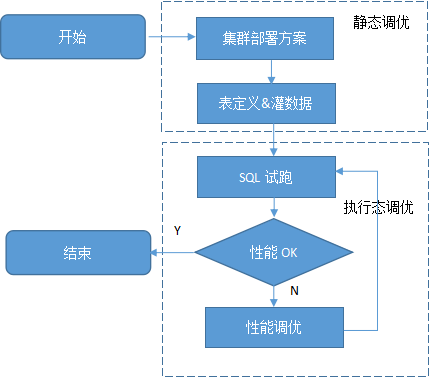
图二 端到端性能调优过程图
执行态调优阶段需要我们根据SQL语句执行的实际情况采取措施干预SQL的具体执行计划方式来提升性能。一般包括SQL改写、guc参数干预执行计划等手段。一个端到端的性能调优过程可以用如下流程图三表示。
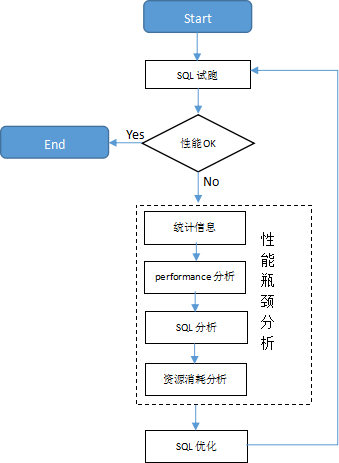
图三 SQL性能调优过程图
统计信息是优化器的核心输入,没有收集统计信息或者统计信息陈旧往往会造成执行计划严重劣化,从而导致性能问题。日常开发中10%左右性能问题都是没有收集统计信息导致的。
遇到性能问题的时候,建议先判断query涉及的表是否都做了analyze,如果有部分表没有做analyze,需要先对这些表做analyze规避统计信息确实导致执行计划劣化的因素,然后重跑SQL再进行分析。
GaussDB 200分布式框架下,执行计划不能下推是最致命的性能问题。在这种场景下只有极少部分的操作会下推到各个DataNode上执行,而绝大部分的操作都在Coordinator上执行,导致计算资源不能充分利用。不能下推是因为Query中含有不支持下推的函数或者语法,一般都可以通过业务的等价改写规避执行计划不能下推的问题。目前Gauss200支持99%以上的客户业务场景的执行计划可以完全下推;而剩余的1%不能下推的场景基本也可以通过SQL改写的方式实现下推。
日常性能瓶颈分析中,可从统计信息分析、查看是否存在计算偏斜着手,统计信息是优化器的输入,没有收集统计信息或者统计信息陈旧往往会造成执行计划严重劣化,从而导致性能问题。10%左右性能问题都是没有收集统计信息导致的。
计算偏斜是指各个DataNode实例承担的查询任务不均衡,部分负载较重的节点执行时间较长,从而导致query的整体执行时间变长的性能问题。计算偏斜问题可以通过分析explain performance中各个算子在DataNode中的A-time和A-rows来分析,如果同一个执行算子在各个DataNode上执行的时间差距较大,我们就可以认为存在计算倾斜。这种偏斜一般分成两种场景。第一,底层Scan造成的数据倾斜,这种场景的特点是DataNode从存储层Scan上来的数据就是不均衡的,从而导致上层的运算出现偏斜。比如两个表的Scan的filter都在分布列上,导致所有的运算都在同一个DataNode上进行。这种计算倾斜的场景可以通过调整分布列的方式解决。第二,中间结果造成的数据倾斜,这种场景的特点是从存储层Scan上来的数据是均衡的,但是在运算过程中的某个算子在DN上输出的结果集出现偏斜,从而导致此算子上层的运算出现计算偏斜。
一个查询语句要经过N算子步骤才会输出最终的结果,在这些步骤中往往只有一个或者几个算子耗时过长才导致整体查询性能下降,这些算子才是整个查询的瓶颈算子。通用的优化手段是查看执行过程的瓶颈算子,然后进行针对性优化。
日常开开发及测试时,要选择合适的分布键,尽量避免数据的重分布。编写程序时,遵循编程规范,尽量避免使用distinct、union等消耗性能的语句,union all中针对相同的表扫描,可以创建临时表的方式提取公共部分。定期对delete表进行vacuum空间回收等,达到资源利用最大化。
(本文来源:公众号“I生活T精彩”)

你“在看”我吗
