





在关系数据库的查询过程中,连接(Join)是将两个数据集合按照某个条件进行合并形成新的数据集合的操作。Join算法是关系型数据库查询算法中最重要的一部分,也是查询优化的关键。本文将简要阐述数据库中的各种Join算法,并介绍其在Mysql和Oracle中的具体实现。

连接类型及语义
连接的意义在于在水平方向上合并两个数据集合,并产生一个新的结果集,其原理是将一个数据源中的行于另一个数据源中和它匹配的行组合成一个新元组。
连接类型主要有两大类:内连接(Inner Join)和外连接(Outer Join)。其中外连接又包括左外连接(Left Outer Join)、右外连接(Right Outer Join)和全外连接(Full Outer Join)。

三种基本的Join算法
数据库中Join操作的实现主要有三种:嵌套循环连接(Nested Loop Join),归并连接(Merge Join)和散列连接或者哈希连接(Hash Join)。
嵌套循环连接(Nested Loop Join)
Nested Loop Join是最基础的连接方式,方法就是在A表抽一条记录,然后遍历B表查找匹配记录。其中遍历B表的过程一般数据库都有优化,比如运用索引或使用内存进行数据缓存。Mysql 8.0.18版本之前,只支持这一种算法,但是Mysql对此算法做了很多优化,后面讲到Mysql时会详细介绍。
Nested Loop Join一般用在连接的表中有索引,并且索引选择性较好的时候,也就是外表(驱动表)的记录集比较小(<10000)而且内表需要有索引,否则就相当于两表直接做笛卡尔积,非常消耗性能。
散列连接(Hash Join)
将A表按连接键计算出一个Hash表,然后从B表一条条抽取记录,计算Hash值,根据Hash值到A表的Hash中来匹配符合条件的记录。
下图简单描述了Hash Join的三个步骤:
创建Hash图
Hash匹配
结果导出
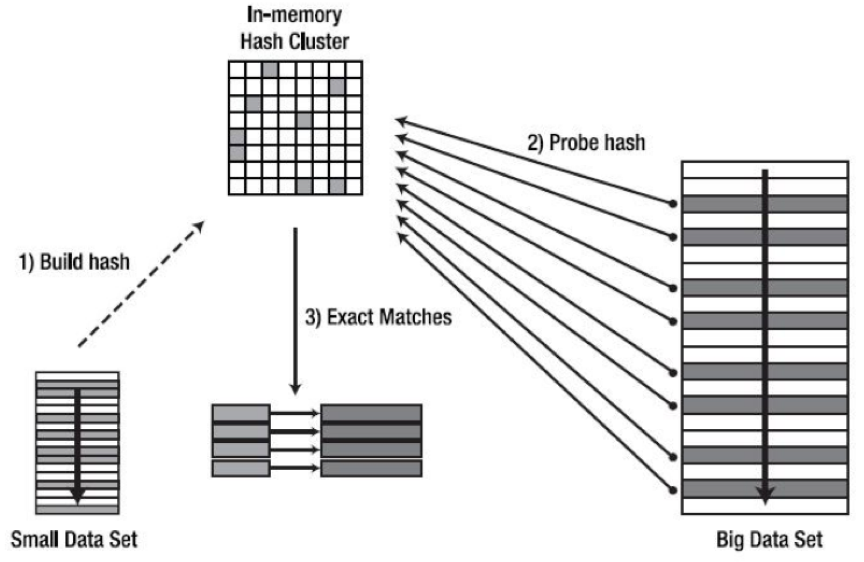
散列连接不需要索引,这是他最大的优势,并且与循环嵌套连接相比,散列连接更容易处理大结果集,但是它只能用作等值连接,同时Hash Join由于需要计算和存储hash值,会消耗更多的cpu资源和内存。Hash Join是一种典型的用空间和cpu资源来换取时间的查询方法。
排序归并连接(Sort-Merge Join)
归并连接算法又称排序归并连接,主要用于计算自然连接和等值连接。先把A表和B表分别进行排序。然后分别对两个表进行扫描一遍即可完成。
Sort-Merge Join需要额外对表进行排序,某些情况下用户查询恰好也需要按连接键进行排序,这时候使用Sort-Merge Join是较优的选择。对于两个表都很大且无索引的情况,Sort-Merge join要比Nested Loop Join要好。

Mysql Join算法实现
在Mysql 8.0.18版本之前,Mysql只支持Nest Loop Join算法,Mysql针对这个算法做了若干优化,实现了Block Nest-Loop Join,Index Nest-Loop Join和Batched Key Access Join等,下面简单对这三种循环连接算法做个介绍。
Index Nested-Loop Join(索引嵌套循环连接)
简单来说Index Nested-Loop Join 就是通过外层表匹配条件直接与内层表索引进行匹配,从而减少扫描的成本。当连接时可以用索引时,Mysql会默认使用此算法。
Block Nested-Loop Join(缓存块嵌套循环连接)
当数据无索引时,数据库肯定不会无脑地去计算笛卡尔积。使用缓存是数据查询常见的优化方式。Block Nested-Loop就是加了一层缓存用来缓存驱动表,然后分块提交驱动表的数据去匹配内表数据,从而减少IO次数。这个缓存的大小由参数“join_buffer_size”来控制,如果缓存足够大,大到可以缓存整个驱动表,那只需要扫描一次内表,就可以完成连接。当连接查询时无法使用索引的时候,Mysql通常会选择此算法。
Batched Key Access Join(批量键访问连接)
Mysql 5.6后开始支持此算法,Batched Key Access (BKA)主要用于解决索引查询中的“回表”问题。大家都知道,Mysql查询的时候如果使用的是非主键索引(辅助索引),那么还需要一个回表的过程,通过辅助索引找到主键索引,再找到具体的表记录,而这个回表的过程,如果在大表连接当中发生,会产生大量的随机IO。Mysql为了解决这个问题,引入MRR(Multi-Range Read Optimization)接口的概念,MRR接口利用缓存和排序,将随机 IO 转化为顺序 IO,批量进行回表操作,从而降低查询过程中 IO 开销。所以BKA算法是一种对Index Nested Loop Join算法的优化。需要注意的是,想要使用BKA算法,需要满足如下条件:
Mysql版本>=5.6;
开启MRR接口 ,且尽量关闭MRR基于代价的优化器mrr_cost;
设置batched_key_access = on;(5.7版本及以上默认开启)
具体参数设置示例如下:
Mysql>SET optimizer_switch=‘mrr=on,mrr_cost_based=off,batched_key_access=on‘;
Mysql Hash Join算法
在Mysql 被Oracle收购后,Hash Join的实现也被提示日程,在8.0.18版本中,终于也开始支持Hash Join,但是目前官方版本只支持内连接。目前在最新的版本解释中,官方明确表示在处理大数据集的场景下,Hash Join要比Nested Loop要快,后续将会替代现有的Block Nested Loop,但是Hash Join需要强大的优化器作配合,Mysql也会在后续的版本中引入类似于Oracle CBO(基于代价的优化器)的概念和工具,目前看Mysql 的Hash Join算法还有待完善,期待后续能够更多的汲取Oracle中的成功经验。

Oracle关于连接算法的选择
Oracle 10g之前,一直使用基于规则的优化器(RBO),10g之后开始使用基于代价的优化器(CBO),CBO基于成本和代价来规划执行路径,某些场景下,比如我建立了索引,但是全表数据量很小或者索引列数据重复率很高,Oracle也不会使用索引进行查询。
Oracle和Mysql不同,Oracle完全实现了嵌套循环连接、散列连接和排序归并连接三种算法。Hash Join算法配合CBO优化器使得Oracle的查询效率一直领先业界,对于一些低效sql,CBO也能将其优化。下面简要描述下Oracle关于Join算法的选择规则。
Oracle在CBO模式下,会优先选择Hash Join,且Oracle会根据表的数据量自动选择驱动表;当表数据较小(<10000)且内表有较好索引选择性时,Oracle会考虑使用Nested Loop Join;Sort Merge Join,在目前的Oracle优化器下很少被选择,通常情况下,仅在非等值连接且无索引的大表连接场景下,Oracle才会选择Sort Merge Join,当然这种情况下无论选择哪种算法都会很慢,我们肯定要在开发中尽量避免这种情况。
以上就是分享的关于数据库连接的相关内容,对于关系型数据库,连接算法是数据查询的基础,也是一个数据库查询效率高低的关键。从上述的介绍可以发现,目前Oracle在这一块算法上已经很完善,Mysql也通过不断优化追赶上了Oracle的脚步。Mysql目前的算法,在大多数场景下也绝对够用。各位开发,在设计表和编写查询sql时,保证索引的正确创建,表数据的合理拆分,避免大结果集相互关联,其他的就可以放心交给数据库,数据库的优化引擎都能很正确的选择最合适的算法。当前主流数据库基本都基于代价来选择算法,所以切不可生搬硬套迷信规则,还是要多多结合实践,总结经验教训。
作者 | 王月康
视觉 | 王朋玉
统筹 | 郑 洁



