




场景:hadoop集群双网卡,客户端在集群外,客户端只能访问外网IP。默认客户端连接hadoop是通过IP地址的,即使在客户端配置的/etc/hosts里为外网IP和域名的映射关系,也会连内网IP,导致无法访问datanode的1004端口,无法实现文件的上传和下载。为了在hadoop集群内能使用内网网卡,hadoop集群外能使用外网网卡,充分利用网络带宽,需要以下配置。
设置参数
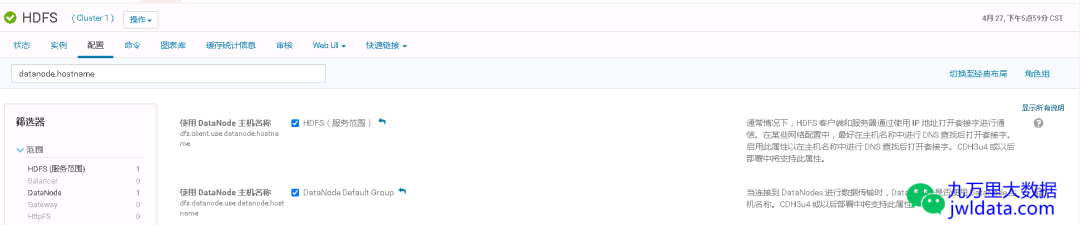
可设置以下两个参数为true,使客户端使用datanode的hostname来访问。当然要确保在客户端配置的/etc/hosts里为外网IP和域名的映射关系。
dfs.client.use.datanode.hostname
dfs.datanode.use.datanode.hostname
并将NameNode和DataNode的端口绑定到通配符地址(即0.0.0.0)上。
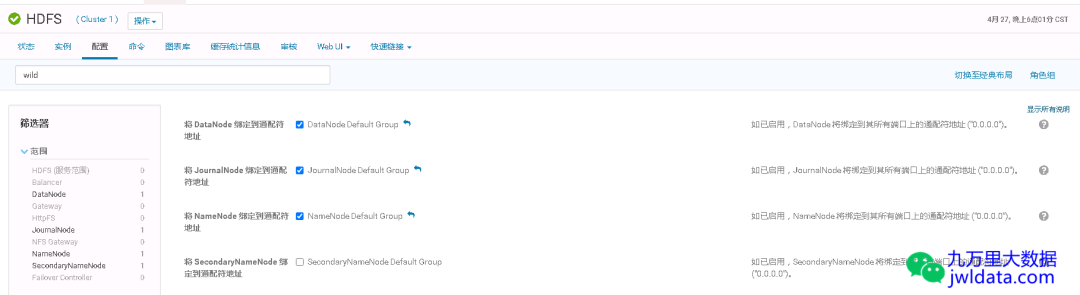
并将ResourceManager的端口绑定到通配符地址(即0.0.0.0)上。

并将HiveServer2的端口绑定到通配符地址(即0.0.0.0)上(如果没有使用haproxy的情况下)。

环境检查清单
hadoop集群:
•/etc/hosts中配的是集群机器的内网IP和hostname的映射关系•dfs.client.use.datanode.hostname和dfs.datanode.use.datanode.hostname设置成true•NameNode, DataNode, ResourceManager, HiveServer2等将端口绑定到通配符地址(即0.0.0.0)上
集群外客户端:
•/etc/hosts中配的是集群机器的外网IP和hostname的映射关系•客户端使用的是最新从CDH控制台下载下来的配置文件,安装可参见Spark客户端安装配置,Hadoop客户端安装配置
测试验证
在hadoop集群外的Spark客户端提交一个任务。
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster /opt/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar 10复制
注意:spark提交方式必须是cluster模式。使用client模式会报错,因为客户端机器的hostname没有在hadoop集群的机器/etc/hosts里面配置,导致DataNode无法识别客户端机器的hostname,进而导致报错。
在hadoop集群外的Hadoop客户端进行文件上传和下载操作。
hdfs dfs -put 1.txt /tmphdfs dfs -get /tmp/1.txt复制
欢迎关注我的微信公众号“九万里大数据”,原创技术文章第一时间推送。欢迎访问原创技术博客网站 jwldata.com[1],排版更清晰,阅读更爽快。

引用链接
[1]
jwldata.com: https://www.jwldata.com
