




我们已经讨论了一些对象级锁(特别是关系级锁),以及行级锁及其与对象级锁的连接,还探讨了等待队列。这次我们要来个大杂烩。我们将从死锁开始(实际上,我计划上次讨论死锁,但是这篇文章本身篇幅太长了),然后简要回顾一下对象级锁,最后讨论谓词锁。
死锁
使用锁时,我们可能会遇到死锁。当事务一试图获取事务二已经使用的资源,而事务二试图获取事务一使用的资源时,就会发生这种情况。左下图说明了这一点:实线箭头表示获取的资源,而虚线箭头表示尝试获取已使用的资源。
为了可视化死锁,可以方便地构建等待图。为此,我们删除特定的资源,只保留事务,并指示哪个事务等待哪个事务。如果一个图包含一个循环(从一个顶点开始,我们可以沿着箭头走到它自己),这就是死锁。
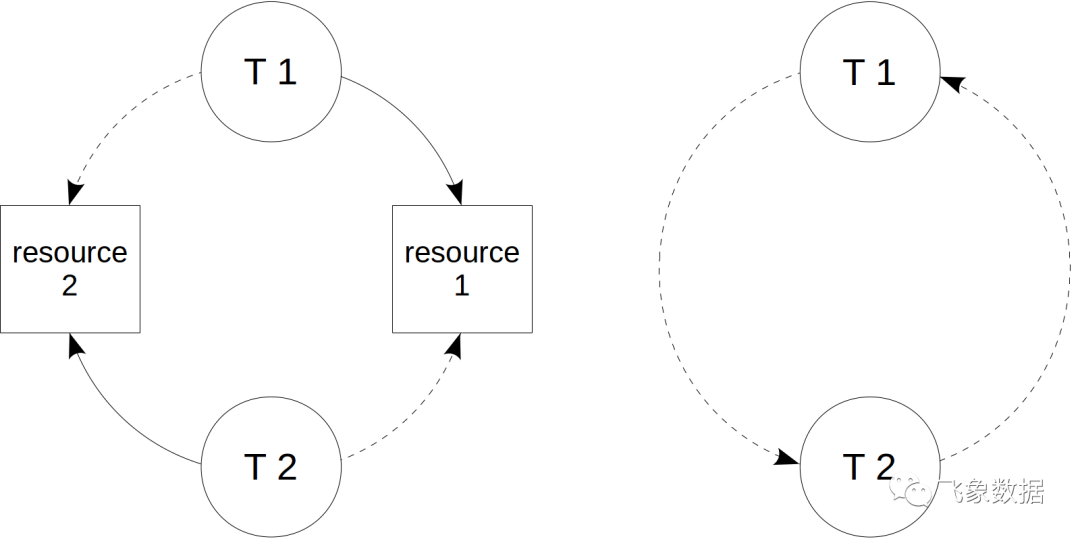
不仅对于两个事务,对于任何数量的事务,都可能发生死锁。
如果发生死锁,则所涉及的事务只能无限期地等待。因此,包括PostgreSQL在内的所有DBMS都会自动跟踪锁定。
然而,检查需要一定的过程,而且不希望每次请求一个新锁时都进行检查(毕竟死锁很少发生)。因此,当一个进程试图获取锁,但无法获取时,它将排队并«进入休眠状态»,但会将计时器设置为deadlock_timeout
参数中指定的值(默认为1秒)。如果资源提前释放,这当然是好的,数据库可以节省开支。但是,如果deadlock_timeout
到期,等待继续,等待进程将唤醒并启动检查。
如果检查(包括建立等待图表并搜索周期)没有检测到死锁,则它将继续休眠。
早些时候,我在评论中因为没有提到lock_timeout
参数而受到了相当大的指责,这个参数会影响任何运并避免无限长的等待:如果在指定的时间内无法获取锁,则运算会以lock_not_available
错误终止。不要将此参数与statement_timeout混淆,后者限制执行运算的总时间,无论后者是等待锁定还是执行常规工作。
但是如果检测到死锁,其中一个事务(在大多数情况下,是启动检查的事务)将被迫中止。这将释放它获得的锁,并允许其他事务继续进行。
死锁通常意味着应用程序设计不正确。有两种方法可以检测到这种情况:第一,消息将出现在服务器日志中,第二,其值pg_stat_database.deadlocks
将增加。
死锁示例
通常,死锁是由锁定表行的顺序不一致引起的。让我们考虑一个简单的例子。第一个事务将从第一个帐户中转移100卢布到第二个帐户中。为此,交易减少了第一个帐户:
=> BEGIN;=> UPDATE accounts SET amount = amount - 100.00 WHERE acc_no = 1;UPDATE 1复制
同时,第二个事务将从第二个帐户向第一个帐户转帐10卢布。从减少第二个帐户开始
| => BEGIN;| => UPDATE accounts SET amount = amount - 10.00 WHERE acc_no = 2;| UPDATE 1复制
现在,第一个事务尝试增加第二个帐户,但检测到行上的锁。
=> UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 2;复制
然后,第二个交易尝试增加第一个帐户,也被阻止。
| => UPDATE accounts SET amount = amount + 10.00 WHERE acc_no = 1;复制
因此出现了循环等待,它不会自行结束。在第二个步骤中,尚无法访问资源的第一个事务将启动检查死锁并被服务器强制中止。
ERROR: deadlock detectedDETAIL: Process 16477 waits for ShareLock on transaction 530695; blocked by process 16513.Process 16513 waits for ShareLock on transaction 530694; blocked by process 16477.HINT: See server log for query details.CONTEXT: while updating tuple (0,2) in relation "accounts"复制
现在,第二个事务可以继续。
| UPDATE 1| => ROLLBACK;=> ROLLBACK;复制
执行此类操作的正确方法是以相同顺序锁定资源。例如:在这种情况下,帐户可以按其编号的升序锁定。
两个UPDATE命令的死锁
有时,在似乎永远不会发生的情况下,我们可能会陷入僵局。例如:将SQL命令视为原子命令是方便且通常的,但是UPDATE命令在更新行时将其锁定。这不会立即发生。因此,如果命令更新行的顺序与另一命令执行行的顺序不一致,则会发生死锁。
尽管这种情况不太可能发生,但仍然可能发生。为了重现它,我们将在amount
列上以降序创建索引amount
:
=> CREATE INDEX ON accounts(amount DESC);复制
为了能够观察到发生的情况,让我们创建一个函数,该函数可以增加传递的值,但是非常非常缓慢,直到一整秒:
=> CREATE FUNCTION inc_slow(n numeric) RETURNS numeric AS $$SELECT pg_sleep(1);SELECT n + 100.00;$$ LANGUAGE SQL;复制
我们还将需要pgrowlocks
扩展。
=> CREATE EXTENSION pgrowlocks;复制
第一条UPDATE命令将更新整个表。执行计划很明显-它是顺序扫描:
| => EXPLAIN (costs off)| UPDATE accounts SET amount = inc_slow(amount);| QUERY PLAN| ----------------------------| Update on accounts| -> Seq Scan on accounts| (2 rows)复制
由于表页面上的元组以金额的升序排列(正是我们添加它们的方式),因此它们也将以相同的顺序进行更新。让更新开始。
| => UPDATE accounts SET amount = inc_slow(amount);复制
同时,在另一个会话中,我们将禁止顺序扫描 :
|| => SET enable_seqscan = off;复制
在这种情况下,对于下一个UPDATE运算符,执行计划决定使用索引扫描:
|| => EXPLAIN (costs off)|| UPDATE accounts SET amount = inc_slow(amount) WHERE amount > 100.00;|| QUERY PLAN|| --------------------------------------------------------|| Update on accounts|| -> Index Scan using accounts_amount_idx on accounts|| Index Cond: (amount > 100.00)|| (3 rows)复制
第二和第三行满足条件,并且由于索引是按金额的降序构建的,因此这些行将以相反的顺序进行更新。
让我们运行下一个update。
|| => UPDATE accounts SET amount = inc_slow(amount) WHERE amount > 100.00;复制
快速浏览表页面显示,第一个操作员已经设法更新了第一行(0,1),第二个操作员更新了最后一行(0,3):=> SELECT * FROM pgrowlocks('accounts') \gx
=> SELECT * FROM pgrowlocks('accounts') \gx-[ RECORD 1 ]-----------------locked_row | (0,1)locker | 530699 <- the firstmulti | fxids | {530699}modes | {"No Key Update"}pids | {16513}-[ RECORD 2 ]-----------------locked_row | (0,3)locker | 530700 <- the secondmulti | fxids | {530700}modes | {"No Key Update"}pids | {16549}复制
再过一秒钟。第一个操作员更新了第二行,而第二个操作员也想这样做,但不能。
=> SELECT * FROM pgrowlocks('accounts') \gx-[ RECORD 1 ]-----------------locked_row | (0,1)locker | 530699 <- the firstmulti | fxids | {530699}modes | {"No Key Update"}pids | {16513}-[ RECORD 2 ]-----------------locked_row | (0,2)locker | 530699 <- the first was quickermulti | fxids | {530699}modes | {"No Key Update"}pids | {16513}-[ RECORD 3 ]-----------------locked_row | (0,3)locker | 530700 <- the secondmulti | fxids | {530700}modes | {"No Key Update"}pids | {16549}复制
现在,第一个操作员想要更新最后一个表行,但是它已经被第二个操作员锁定。因此陷入僵局。
事务一中止:
|| ERROR: deadlock detected|| DETAIL: Process 16549 waits for ShareLock on transaction 530699; blocked by process 16513.|| Process 16513 waits for ShareLock on transaction 530700; blocked by process 16549.|| HINT: See server log for query details.|| CONTEXT: while updating tuple (0,2) in relation "accounts"复制
事务二继续:
| UPDATE 3复制
可以在锁管理器 README中找到有关检测和防止死锁的详细信息。
到此结束了有关死锁的讨论,然后我们继续进行其余的对象级锁。

锁定非关系
当我们需要锁定不是PostgreSQL意义上的关系的资源时,对象类型的锁将被用。我们几乎可以想到的任何东西都可以引用这些资源:表空间,订阅,模式,枚举数据类型等。大致上,这就是可以在系统目录中找到的所有内容 。
通过一个简单的例子说明。让我们开始一个事务并在其中创建一个表:
=> BEGIN;=> CREATE TABLE example(n integer);复制
现在,让我们看看该对象类型的锁出现在pg_locks
:
=> SELECTdatabase,(SELECT datname FROM pg_database WHERE oid = l.database) AS dbname,classid,(SELECT relname FROM pg_class WHERE oid = l.classid) AS classname,objid,mode,grantedFROM pg_locks lWHERE l.locktype = 'object' AND l.pid = pg_backend_pid();database | dbname | classid | classname | objid | mode | granted----------+--------+---------+--------------+-------+-----------------+---------0 | | 1260 | pg_authid | 16384 | AccessShareLock | t16386 | test | 2615 | pg_namespace | 2200 | AccessShareLock | t(2 rows)复制
为了弄清楚什么东西被上锁,我们需要看三个方面:database
,classid
和objid
。我们从第一行开始。
database
是相关的数据库的OID。在这种情况下,此列包含零。这意味着我们处理一个全局对象,该对象并非特定于任何数据库。
classid
包含来自pg_class
的OID,该类与实际确定资源类型的系统目录表的名称匹配。在本例中,它是pg_authid
,也就是说,角色(用户)是资源。
objid
包含由classid
指示的系统目录表中的OID。
=> SELECT rolname FROM pg_authid WHERE oid = 16384;rolname---------student(1 row)复制
我们的身份是student
,而这正是锁定的角色。
现在让我们说明第二行。已指定数据库,并且该数据库是test
我们连接的数据库。
classid
指示pg_namespace
表,其中包含模式。
=> SELECT nspname FROM pg_namespace WHERE oid = 2200;nspname---------public(1 row)复制
这表明该public
模式已锁定。
因此,我们已经看到,当创建对象时,创建该对象的所有者角色和架构将被锁定(在共享模式下)。这是合理的:否则,有人可能会在事务尚未完成时drop
角色或架构。
=> ROLLBACK;复制
锁定关系扩展
当关系(表,索引或实例化视图)中的行数增加时,PostgreSQL可以在可用页面中使用可用空间进行插入,但是很显然,一旦必须添加新页面。实际上,它们被添加到适当文件的末尾。这就是关系扩展。
为确保两个进程不会急于同时添加页面,扩展进程由该extend
类型的专用锁保护。在清理索引以使其他进程无法在扫描期间添加页面时,将使用相同的锁。
当然,无需等待事务完成即可释放此锁 。
以前,表一次只能扩展一页面。这在通过多个过程同时插入行时引起了问题。因此,从PostgreSQL 9.6开始,几个页面被一次添加到表中(与等待进程的数量成比例,但不大于512)。
页面锁
该page
类型的页面级锁仅在这种情况下使用(除了谓词锁,这将在后面讨论)。
GIN索引使我们能够加快复合值的搜索,例如:文本文档(或数组元素)中的单词。初步估计,这些索引可以表示为常规B树,该B树存储文档中的单独单词,而不是文档本身。因此,当添加新文档时,必须重新构建索引,以便在其中添加文档中的每个新单词
为了获得更好的性能,GIN索引有一个延迟插入特性,由fastupdate
存储参数打开。新单词首先被快速地添加到一个无序的待处理列表中,过一段时间后,所有累积的内容都会被移动到主索引结构中。这是因为相同的单词在不同的文档中出现的概率很高。
为了防止多个进程同时从挂起列表移动到主索引,在移动期间,索引元页以独占模式锁定。这并不妨碍索引的正常使用。
咨询锁
与其他锁(例如关系级锁)不同,咨询锁永远不会自动获取-而是由应用程序开发人员控制。例如,当当应用程序出于某种原因需要一个与常规锁的标准逻辑不一致的锁定逻辑时,它们非常有用。
假设我们有一个与任何数据库对象都不匹配的假设资源(我们可以使用诸如SELECT FOR
或LOCK TABLE
之类的命令锁定该资源)。我们需要为其设计一个数字标识符。如果资源具有唯一名称,则一个简单的选择是使用其哈希码:
=> SELECT hashtext('resource1');hashtext-----------991601810(1 row)复制
这就是我们获得锁的方式:
=> BEGIN;=> SELECT pg_advisory_lock(hashtext('resource1'));复制
与往常一样,有关锁的信息可在pg_locks
找到:
=> SELECT locktype, objid, mode, grantedFROM pg_locks WHERE locktype = 'advisory' AND pid = pg_backend_pid();locktype | objid | mode | granted----------+-----------+---------------+---------advisory | 991601810 | ExclusiveLock | t(1 row)复制
为了使锁真正有效,其他进程还必须在访问资源之前获得对该资源的锁定。显然,应用程序必须确保遵守此规则。
在上面的示例中,锁将一直保留到会话结束,而不是像往常一样保留事务。
=> COMMIT;=> SELECT locktype, objid, mode, grantedFROM pg_locks WHERE locktype = 'advisory' AND pid = pg_backend_pid();locktype | objid | mode | granted----------+-----------+---------------+---------advisory | 991601810 | ExclusiveLock | t(1 row)复制
我们需要明确释放它:
=> SELECT pg_advisory_unlock(hashtext('resource1'));复制
与咨询锁配合使用的丰富功能集:
pg_advisory_lock_shared
已获得共享锁。pg_advisory_xact_lock
(和pg_advisory_xact_lock_shared
)拥有一个直到事务结束为止的共享锁。pg_try_advisory_lock
(以及pg_try_advisory_xact_lock
和pg_try_advisory_xact_lock_shared
)不等待锁,但如果无法立即获取锁,则返回false
。
谓词锁
该谓词锁定期限发生不久前,当早期的DBMS为实施基于锁完全隔离的第一次尝试(可序列化的水平,虽然当时没有SQL标准)。他们当时面临的问题是,即使锁定所有已读取和更新的行也不能确保完全隔离:在表中可能会出现满足相同选择条件的新行,这会导致产生幻像(请参阅有关隔离的文章)。
谓词锁的思想是锁定谓词而不是行。如果在执行条件a > 10 的查询期间,我们锁定了a > 10 谓词,这将不允许我们向表中添加满足条件的新行,并使我们能够避免幻象。问题是这个问题在计算上很复杂;在实践中,它只能解决非常简单的谓词。
在PostgreSQL中,除了基于数据快照的可用隔离之外,可序列化级别的实现方式也有所不同。尽管仍使用谓词锁术语,但其含义已发生了巨大变化。实际上,这些“锁”什么也挡不住。它们用于跟踪事务之间的数据依赖性。
事实证明,快照隔离允许不一致的写(写偏斜)异常和只读事务异常,但任何其他异常都是不可能的。为了弄清楚我们处理的是上述两种异常中的一种,我们可以分析事务之间的依赖关系并发现其中的某些模式。
我们感兴趣的是两种依赖关系:
一个事务读取一行,然后由第二个事务更新(RW依赖性)。
一个事务更新一行,然后由第二个事务读取(WR依赖项)。
我们可以使用已经可用的常规锁来跟踪WR依赖关系,但是RW依赖关系必须特别跟踪。
重申一下,不管名字是什么,谓词锁不锁定任何东西。而是在事务提交时执行检查,如果发现可能指示异常的可疑依赖序列,则事务将中止。
让我们看一下谓词锁的处理方式。为此,我们将创建一个包含大量锁和一个索引的表。
=> CREATE TABLE pred(n integer);=> INSERT INTO pred(n) SELECT g.n FROM generate_series(1,10000) g(n);=> CREATE INDEX ON pred(n) WITH (fillfactor = 10);=> ANALYZE pred;复制
如果使用对整个表的顺序扫描执行查询,则将获得对整个表的谓词锁(即使不是所有行都满足过滤条件)。
| => SELECT pg_backend_pid();| pg_backend_pid| ----------------| 12763| (1 row)| => BEGIN ISOLATION LEVEL SERIALIZABLE;| => EXPLAIN (analyze, costs off)| SELECT * FROM pred WHERE n > 100;| QUERY PLAN| ----------------------------------------------------------------| Seq Scan on pred (actual time=0.047..12.709 rows=9900 loops=1)| Filter: (n > 100)| Rows Removed by Filter: 100| Planning Time: 0.190 ms| Execution Time: 15.244 ms| (5 rows)复制
所有谓词锁都在一种特殊模式下获取-SIReadLock(可序列化隔离读取):
=> SELECT locktype, relation::regclass, page, tupleFROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;locktype | relation | page | tuple----------+----------+------+-------relation | pred | |(1 row)| => ROLLBACK;复制
但是,如果使用索引扫描执行查询,情况会更好。如果处理B树,则在读取的行和遍历的叶子索引页上获得锁就足够了–这使我们不仅可以跟踪特定值,还可以跟踪所有读取的范围。
| => BEGIN ISOLATION LEVEL SERIALIZABLE;| => EXPLAIN (analyze, costs off)| SELECT * FROM pred WHERE n BETWEEN 1000 AND 1001;| QUERY PLAN| ------------------------------------------------------------------------------------| Index Only Scan using pred_n_idx on pred (actual time=0.122..0.131 rows=2 loops=1)| Index Cond: ((n >= 1000) AND (n <= 1001))| Heap Fetches: 2| Planning Time: 0.096 ms| Execution Time: 0.153 ms| (5 rows)=> SELECT locktype, relation::regclass, page, tupleFROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;locktype | relation | page | tuple----------+------------+------+-------tuple | pred | 3 | 236tuple | pred | 3 | 235page | pred_n_idx | 22 |(3 rows)复制
注意一些复杂性。
首先,为每个读取的元组创建一个单独的锁,并且此类元组的数量可能非常大。系统中谓词锁的总数受参数值乘积的限制:max_pred_locks_per_transaction × max_connections(默认值分别为64和100)。这些锁的内存是在服务器启动时分配的。尝试超过此限制将导致错误。
因此,升级用于谓词锁(并且仅用于它们!)。在PostgreSQL 10之前,限制是硬编码的,但是从此版本开始,我们可以通过参数控制升级。如果与一页相关的元组锁的数量超过max_pred_locks_per_page,这些锁将替换为一个页面级锁。考虑一个例子:
=> SHOW max_pred_locks_per_page;max_pred_locks_per_page-------------------------2(1 row)| => EXPLAIN (analyze, costs off)| SELECT * FROM pred WHERE n BETWEEN 1000 AND 1002;| QUERY PLAN| ------------------------------------------------------------------------------------| Index Only Scan using pred_n_idx on pred (actual time=0.019..0.039 rows=3 loops=1)| Index Cond: ((n >= 1000) AND (n <= 1002))| Heap Fetches: 3| Planning Time: 0.069 ms| Execution Time: 0.057 ms| (5 rows)复制
我们看到一个page
类型的锁,而不是三个类型的锁tuple
:
=> SELECT locktype, relation::regclass, page, tupleFROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;locktype | relation | page | tuple----------+------------+------+-------page | pred | 3 |page | pred_n_idx | 22 |(2 rows)复制
同样,如果与一种关系相关的页面上的锁数量超过max_pred_locks_per_relation,则这些锁将替换为一种关系级别的锁。
没有其他级别:谓词锁仅针对关系,页面和元组获取,并且始终处于SIReadLock模式。
当然,锁升级不可避免地导致错误地终止并出现序列化错误的事务数量增加,最终系统吞吐量将减少。在这里,您需要平衡RAM消耗和性能。
第二个复杂性是对索引的不同操作(例如,由于插入新行时索引页的拆分)会改变覆盖读取范围的叶页数。但是实现考虑到了这一点:
=> INSERT INTO pred SELECT 1001 FROM generate_series(1,1000);=> SELECT locktype, relation::regclass, page, tupleFROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;locktype | relation | page | tuple----------+------------+------+-------page | pred | 3 |page | pred_n_idx | 211 |page | pred_n_idx | 212 |page | pred_n_idx | 22 |(4 rows)| => ROLLBACK;复制
顺便说一句,谓词锁并不总是在事务完成后立即释放,因为需要它们来跟踪多个事务之间的依赖关系。但是无论如何,它们都是自动控制的。
PostgreSQL中并非所有类型的索引都支持谓词锁。在postgresql11之前,只有B树可以夸耀这一点,但是这个版本改善了这种情况:hash、GiST和GIN索引被添加到列表中。如果使用了索引访问,但索引不支持谓词锁,则会获取对整个索引的锁。当然,这也增加了错误中止事务的数量。
最后,请注意,谓词锁的使用限制了所有事务可在Serializable级别工作,以确保完全隔离。如果某个事务使用了不同的级别,它将不会获取(并检查)谓词锁。
传统上,向您提供谓词锁定 README的链接以开始使用源代码。
