




我们先回顾一下之前了解过的Prometheus的架构图:
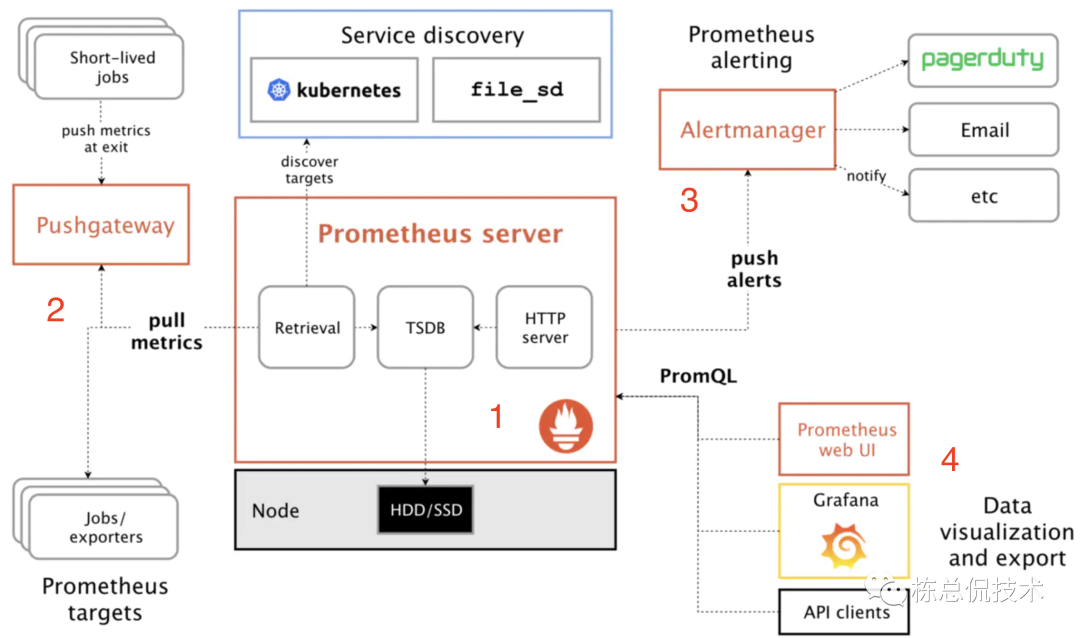
在架构图中Prometheus的各个组件都是单节点模式。
例如 Pushgateway,当推送至Pushgateway的Job非常多时,其单节点压力会非常的大。而 Prometheus server、AlertManager同样的也面临着这样的问题,当采集的是多个集群的指标,原生的Prometheus架构是无法做到水平伸缩,均匀负载的。
单节点也意味着任何一个节点的宕机都存着数据丢失的可能。
所以单Prometheus集群无法起到监控 “中心” 的作用。接下来将给大家介绍解决Prometheus集群高可用方案 -- thanos。
thanos 来源希腊语,意思为灭霸。
thanos的架构分为两种方式,我们首先来了解下thanos的sidecar模式架构:
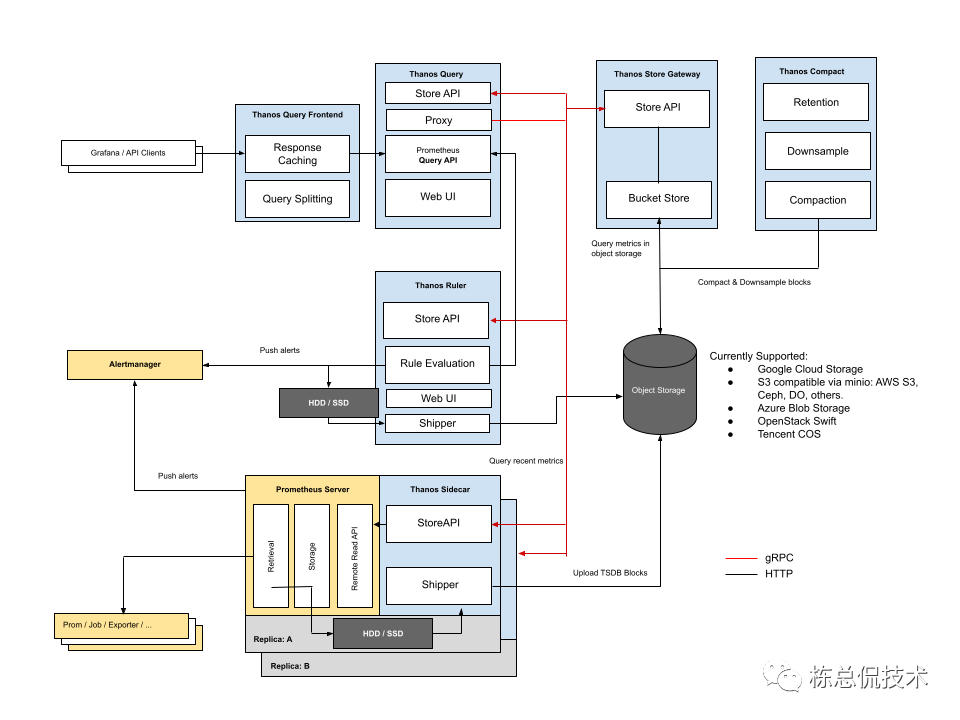
我们通过了解每个组件的作用来理解整个thanos的sidecar模式:
Prometheus Server:收集由下游采集的指标数据,这里的下游可以是Exporter、也可以是Prometheus。与原生的Prometheus架构不同的是,Prometheus server存在多个副本,虽然会收集到重复的数据,但是一旦某一个 Prometheus server 宕机,则可保证数据不会丢失。
Thanos Sidecar:每个 Prometheus server 都会伴随着一个 sidecar 组件,其连接 Prometheus server,将 Prometheus server的数据提供给 Thanos Query 查询或者将数据写入对象存储来做到数据的长期存储。
Thanos Query:负责从多个sidecar、对象存储中获取数据,并做去重等操作返回给Grafana显示。
Thanos Store Gateway:Thanos Query提供的查询语句为PromQL语法格式,对象存储是无法识别的,需要在查询前进行转换为查询对象存储的格式,例如去哪个bucket 取哪个对象等。
Thanos Ruler:Ruler包括两方面的功能:
解析全局指标规则:由于 Prometheus Server 存在多个实利了,单个实利无法获取全局的指标信息,其规则解析器也只能解析当前自己能获取到的指标产生的告警。而Ruler直接通过Query的API获取到多个Prometheus server的指标数据来进行规则解析。
产生新的指标:例如采集的原生指标有计算机磁盘的总空间、使用空间,那么可以计算出磁盘的空间使用率 使用空间 总空间这个新的指标存储到对象存储中。当界面需要显示 磁盘的空间使用率时则只用取这个新产生的指标值就行。
Thanos ComPact:对存入对象存储的数据进行压缩。当我们通过Grafana查看实时数据时,可能需要精确到秒,所以我们会每隔5秒或者10秒采集一次指标数据来看到完整的趋势图。而当我们看历史数据的时候可能只需要看从哪一天到哪一天的数据,在图表中,单位时间可能只需要精确到半小时或者小时,那么我们也没有必要将每一次采集的数据都存到对象存储中,compact正是用来压缩对象存储数据的一个组件。
大家不妨将各个组件的作用结合着图示多次来回的阅读,这样便于理解整个数据流的过程。
如果我们需要监控多个集群,我们将 prometheus Server和Sidecar看作是客户端,而其他的组件都是服务端。客户端还包括有进行采集指标的各个Exporter。
客户端需要部署在各个集群内部。如果项目集群与服务端处于一个内网或者项目集群也提供了可访问的外网IP,那么sidecar模式是服务端可以访问到客户端并拉取数据的。
但是在现实生产环境中,大部分场景是各个集群处于自己的内网环境,不提供对外可访问的IP,也就只能客户端单项访问服务端了。此时,Thanos Query无法访问到 Thanos Sidecar获取指标数据。
对Prometheus了解的同学可能会立刻想到使用 Prometheus提供的remote write功能,主动上报指标。在云端使用一个Prometheus作为Receiver来接收数据。
Thanos提供的Receiver模式正是借鉴remote write数据流模式提供的解决方案,我们通过架构图来了解Thanos的另外一种架构模式 Receiver。
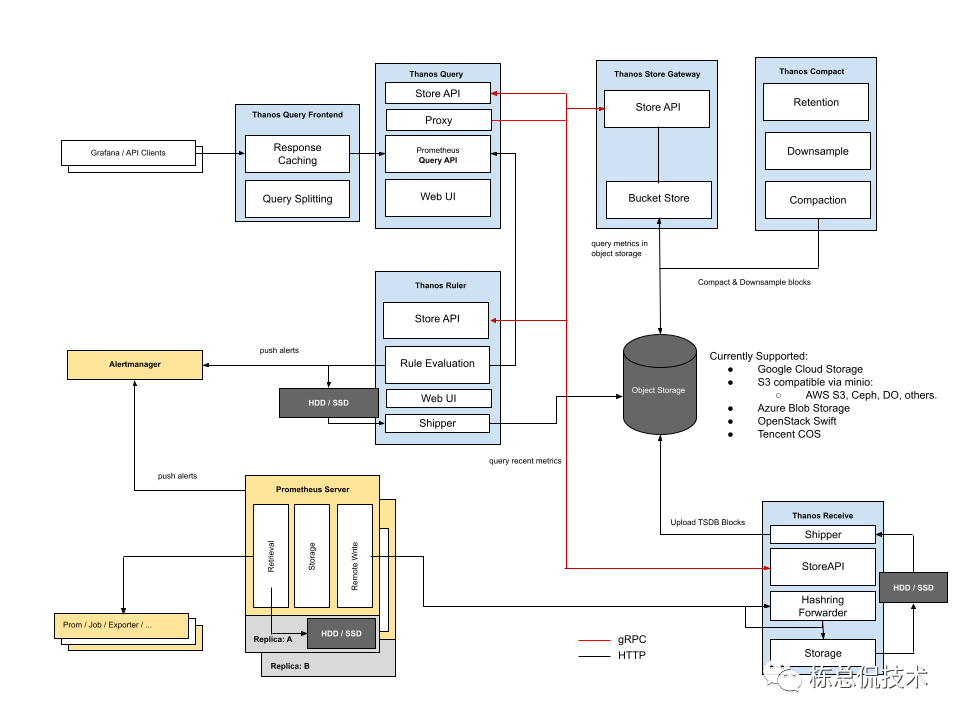
与 Sidecar模式不同的是,不需要Sidecar组件,增加了一个Receiver组件。
Prometheus Server:配置remote write远程地址,为Thanos Receiver的接收指标数据接口。
Thanos Receiver:接收数据供Thanos Query查询,同时将长期数据存储至对象存储。
Thanos Receiver与Pushgateway都可以收集指标数据,不同的是,Thanos Receiver 实现了hash一致性,可支持集群扩展,这样可以做到多节点的负载均衡,避免单个节点压力过大,或者宕机导致数据丢失。
大家可以尝试动手搭建整个集群起来,加深对整个过程的了解。
往期回顾:
