




import pandas as pd复制
customer = pd.read_csv("Churn_Modelling.csv")marketing = pd.read_csv("DirectMarketing.csv")复制
customer[['Geography','Gender','EstimatedSalary']].groupby(['Geography','Gender']).mean()复制
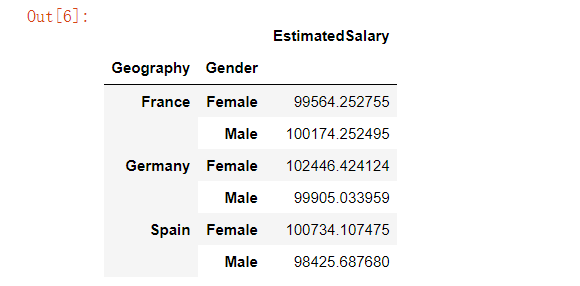
从上面的结果可以得知,在“法国”这一类当中的“女性(Female)”这一类的预估工资的平均值达到了99564欧元,“男性”达到了100174欧元
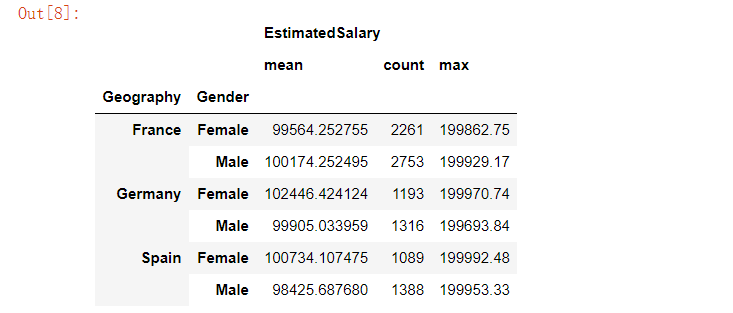
customer[['Geography','Gender','EstimatedSalary']].groupby(['Geography','Gender']).agg(['mean','count','max'])复制
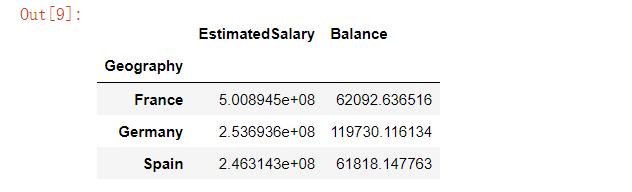
customer[['Geography','EstimatedSalary','Balance']].groupby('Geography').agg({'EstimatedSalary':'sum', 'Balance':'mean'})复制
pd.crosstab(index=marketing.Age, columns=marketing.Gender, values=marketing.Salary, aggfunc='mean').round(1)复制

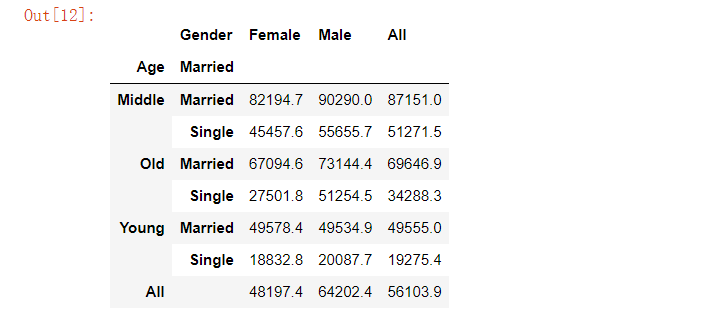
pd.crosstab(index=[marketing.Age, marketing.Married], columns=marketing.Gender,values=marketing.Salary, aggfunc='mean', margins=True).round(1)复制
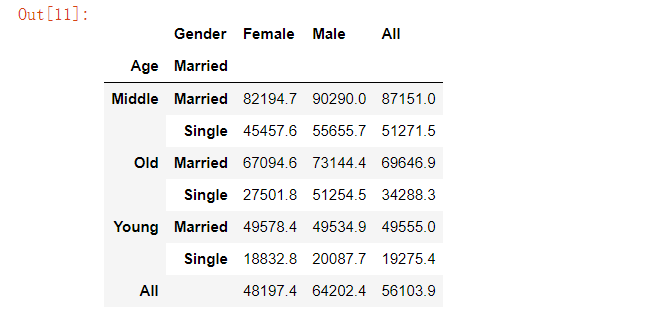
pd.pivot_table(data=marketing, index=['Age', 'Married'], columns='Gender', values='Salary', aggfunc='mean', margins=True).round(1)复制
pip install sidetable复制
import sidetablemarketing.stb.freq(['Age'])复制

marketing.stb.freq(['Age'], value='AmountSpent')复制

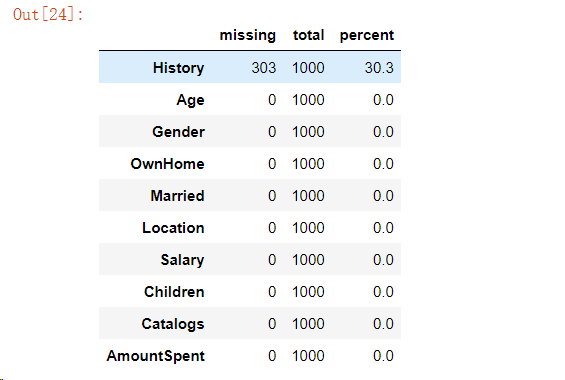
“Sidetable”函数当中的“Missing”方法顾名思义就是返回缺失值的数量以及百分比,例如下面的代码,“History”这一列的缺失值占到了30.3%
marketing.stb.missing()复制
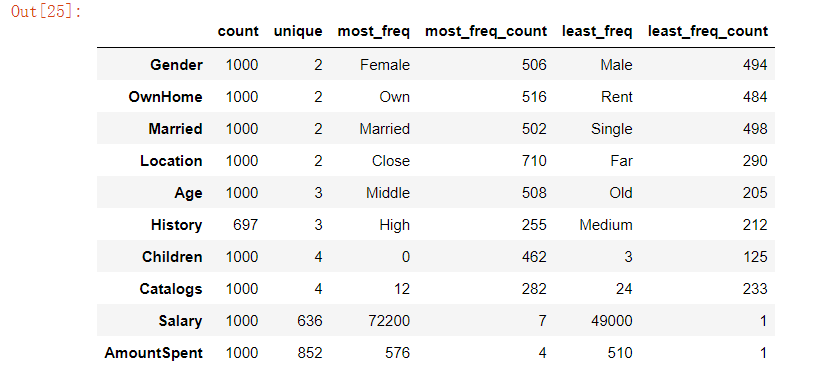
marketing.stb.counts()复制




文章转载自关于数据分析与可视化,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
数据库国产化替代深化:DBA的机遇与挑战
代晓磊
1300次阅读
2025-04-27 16:53:22
2025年4月国产数据库中标情况一览:4个千万元级项目,GaussDB与OceanBase大放异彩!
通讯员
776次阅读
2025-04-30 15:24:06
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
532次阅读
2025-04-17 17:02:24
一页概览:Oracle GoldenGate
甲骨文云技术
496次阅读
2025-04-30 12:17:56
GoldenDB数据库v7.2焕新发布,助力全行业数据库平滑替代
GoldenDB分布式数据库
479次阅读
2025-04-30 12:17:50
优炫数据库成功入围新疆维吾尔自治区行政事业单位数据库2025年框架协议采购!
优炫软件
365次阅读
2025-04-18 10:01:22
给准备学习国产数据库的朋友几点建议
白鳝的洞穴
344次阅读
2025-05-07 10:06:14
XCOPS广州站:从开源自研之争到AI驱动的下一代数据库架构探索
韩锋频道
315次阅读
2025-04-29 10:35:54
MySQL 30 周年庆!MySQL 8.4 认证免费考!这次是认真的。。。
数据库运维之道
290次阅读
2025-04-28 11:01:25
国产数据库图谱又上新|82篇精选内容全览达梦数据库
墨天轮编辑部
284次阅读
2025-04-23 12:04:21
