




本文粗译自:Sequence Processing with Recurrent Networks的前两个小节,后面两个小节(多层RNN和双向RNN、LSTM和GRU,相对简单,可直接阅读论文,重要部分已标记)
Simple Recurrent Neural Networks(RNN)
前言
语言本身就具有时间的属性,不管是说话还是写文章,都是一个字一个字的吐。当我们在说一句话的时候,这些单词在我们脑子里的处理过程几乎是一次性或者一瞬间的。如果用machine learning的方法来处理文本,在多数情况下是很难捕捉到文本的时间信息,FFN也更擅长处理定长的数据,而对于变长的文本也是无可奈何。
于是,产生了滑窗的做法,用滑窗在不定长的文本上面滑动,用滑窗内固定长度的输入,通过全连接神经网络预测下一个词。原理如图: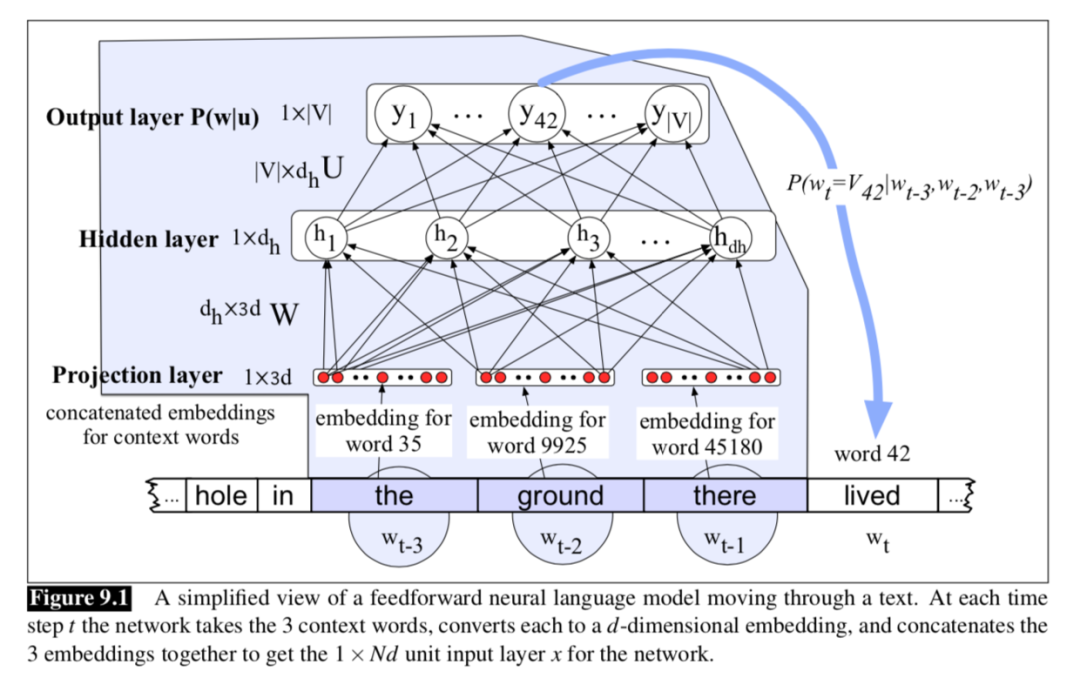
如图所示,我们用“the ground there”三个单词来预测“lived”。 具体步骤:
分别获得三个单词的embedding,d是词向量维度;
将三个向量concat在一起,输入维度是1*3d;
接入一个两层的全连接神经网络,第一层是h*3d,第二层是h*V,h是隐藏层维度,V是词表维 度即输出层维度;
从输出层中选择概率最大的作为预测单词。
缺点:
用滑窗内的单词预测输出,上下文信息无法学到
滑窗会将短语或者固定搭配割裂开来,造成语义分割
那么RNN的诞生比较好的解决了上述问题,RNN(循环神经网络)其实是一类神经网络模型,那么我们下面讲的RNN是最简单的网络结构。
RNN网络结构
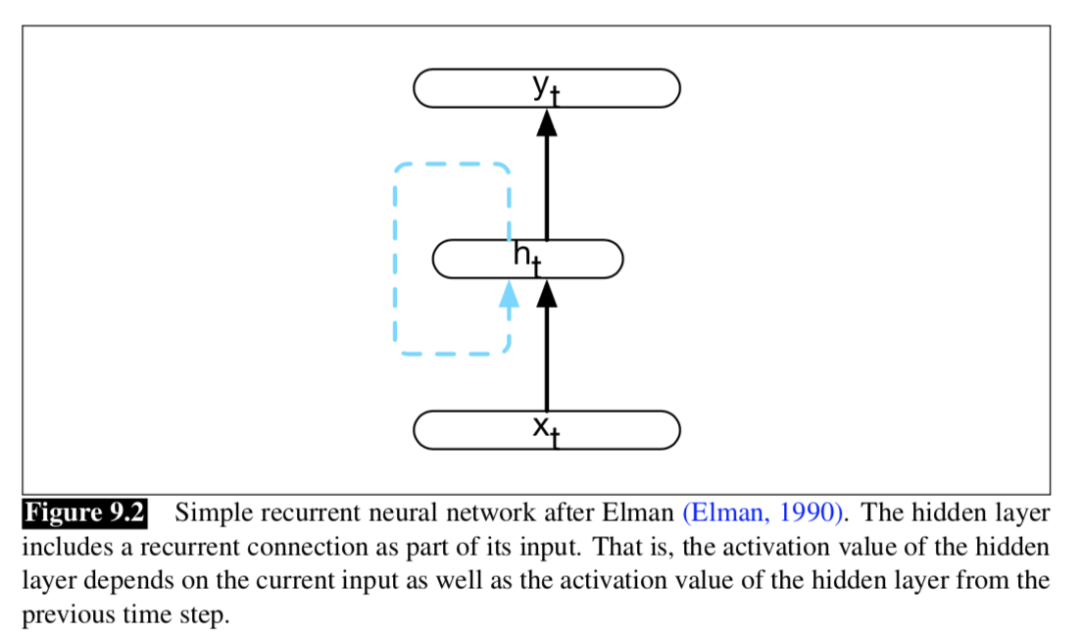
就像之前滑窗的网络结构一样,(抛开虚线不看)RNN是由两层的神经网络构成,输入层、隐藏层和输出层都惊人的相似,但不同的是滑窗结构的输入是多个单词,而这里是一个单词。RNN之所以能捕捉时间信息并且能处理变长结构,关键就在于蓝色的虚线,这也是和滑窗结构及其他网络结构的重大区别。首先这个蓝色虚线到底是什么,有什么用?蓝色虚线是建立上一个单词与当前单词的桥梁,将上一个单词的信息传递给下一个单词,具体是用一个U矩阵实现的。正因为U矩阵的存在,使得文本的序列信息能够联系起来,并且在时间上是一个单词一个单词往下传递,这使得RNN在神经网络结构中脱颖而出。
RNN如何推理
所谓推理,就是前向传播的过程。过程图解如下: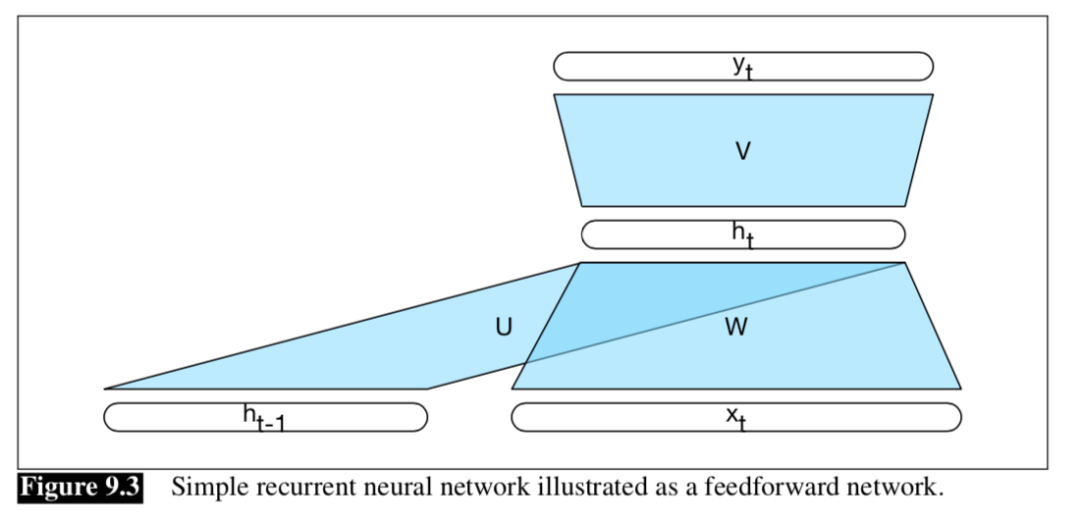
推理的步骤如下:
接受一个单词的词向量作为输入xt;
关键在于隐层的计算:接收当前单词xt的输入与W相乘,同时接收上一个单词的隐层与U相 乘,将二者加和并经过激活函数,得到ht;
用ht和V相乘,并经过激活函数,得到输出层。 这么看来,其实和全连接层推理的关键不同就是隐层的计算方式。
我们用公式表达就是(当然你可以加上偏置项,这不是重点):
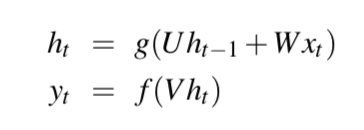
 上述是一个时间步的推理过程,那么在整个序列上就是遍历一个序列长度,上图中的xt就是下图中x的其中一个元素:
上述是一个时间步的推理过程,那么在整个序列上就是遍历一个序列长度,上图中的xt就是下图中x的其中一个元素:
RNN如何训练
所谓训练,就是反向传播的过程。过程图解如下: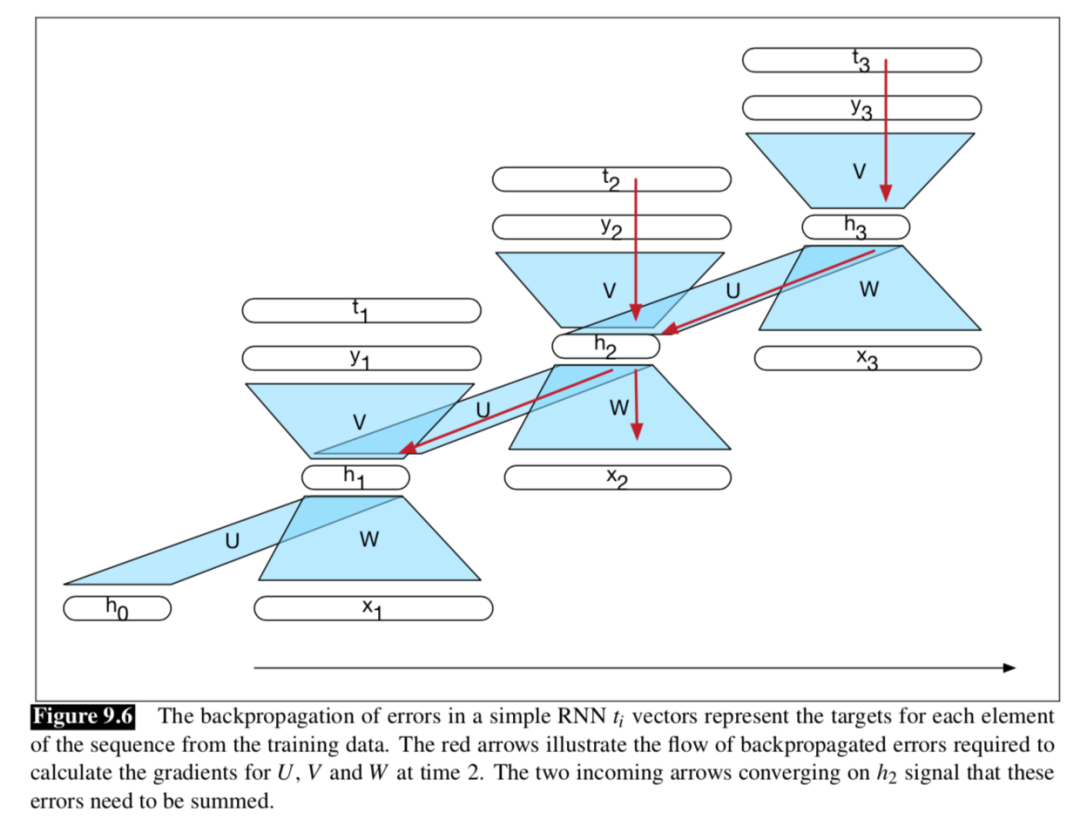 在讲解反向传播之前,我们先来做一些符号规定,便于公式理解:
在讲解反向传播之前,我们先来做一些符号规定,便于公式理解:
我们来看一个时间步的输出yt,yt的值受两个方向的影响:xt和上一个时间步的隐层ht-1,那么根据影响的方向以及链式法则,我们分别计算一个时间步的误差项分别对V\W\U的梯度。
对V求导: 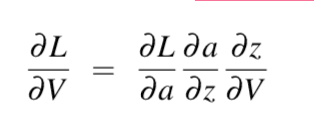
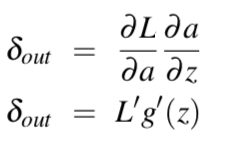
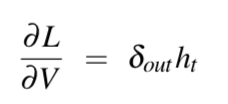 对W和U求导:
前向过程中,RNN中隐层的计算很特殊,那么梯度回传的时候自然也特殊。前向的时候隐层会接收当前时间步的输入和上一个隐层状态,那么后向的时候就反过来,误差是来自当前时间步的输出和下一个隐层传递过来的误差。
对W和U求导:
前向过程中,RNN中隐层的计算很特殊,那么梯度回传的时候自然也特殊。前向的时候隐层会接收当前时间步的输入和上一个隐层状态,那么后向的时候就反过来,误差是来自当前时间步的输出和下一个隐层传递过来的误差。  那么很容易得到:
那么很容易得到: 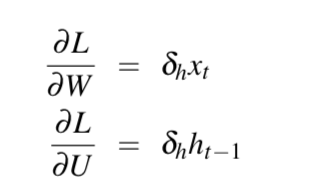 到这里,最简单的RNN便讲完了。接下来讲,RNN如何运用?
到这里,最简单的RNN便讲完了。接下来讲,RNN如何运用?
Applications of Recurrent Neural Networks
RNN在处理序列数据具有不可比拟的优势,可以做词性标注、文本分类、情感分析、主题分类等,大致分为三个方面:
生成式任务
序列标注任务
文本分类任务
接下来看,每个类型的任务中RNN应该怎么用?
生成式任务
步骤:
用句子标记的开头作为第一个输入,从softmax层的概率分布中采样,作为句子的第一个词。
用第一个词的embedding作为神经网络的输入,从softmax层的概率分布中采样,作为句子的第二个词。
重复步骤2,直到从softmax层采样到结尾标记。 当然也可以不采样,直接选出概率最大的词。如下图:
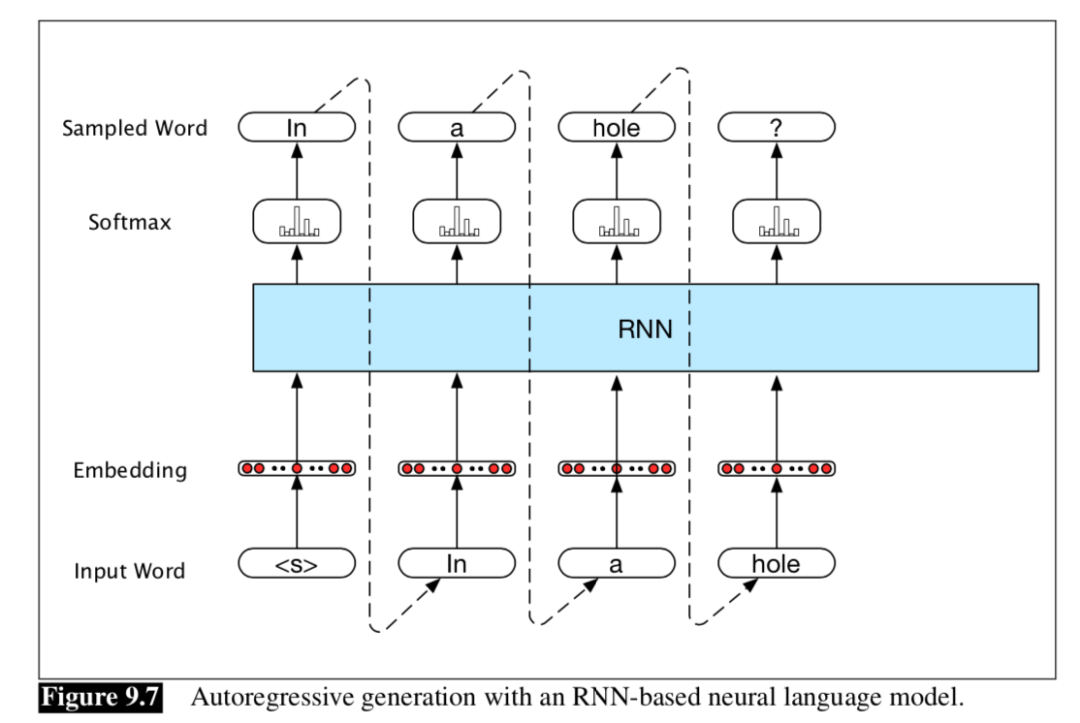
这种方式称为自回归生成,因为在每个时间步骤生成的单词都取决于网络在上一步生成的单词。可以应用于文本摘要、自动问答等任务,通俗来说,也就是我们要输入一段文本,然后用RNN对这段文本进行编码,让这段文本的信息存储在一个向量或者矩阵里,然后用这个向量作为另一个RNN的初始输入,不断的进行解码输出一段文本,我们称这个过程是encoder-decoder。
序列标注任务
序列标注任务是输入一段文本,然后对这段文本的每一个元素进行标记,典型任务就是标记一段文本的词性。如下图:
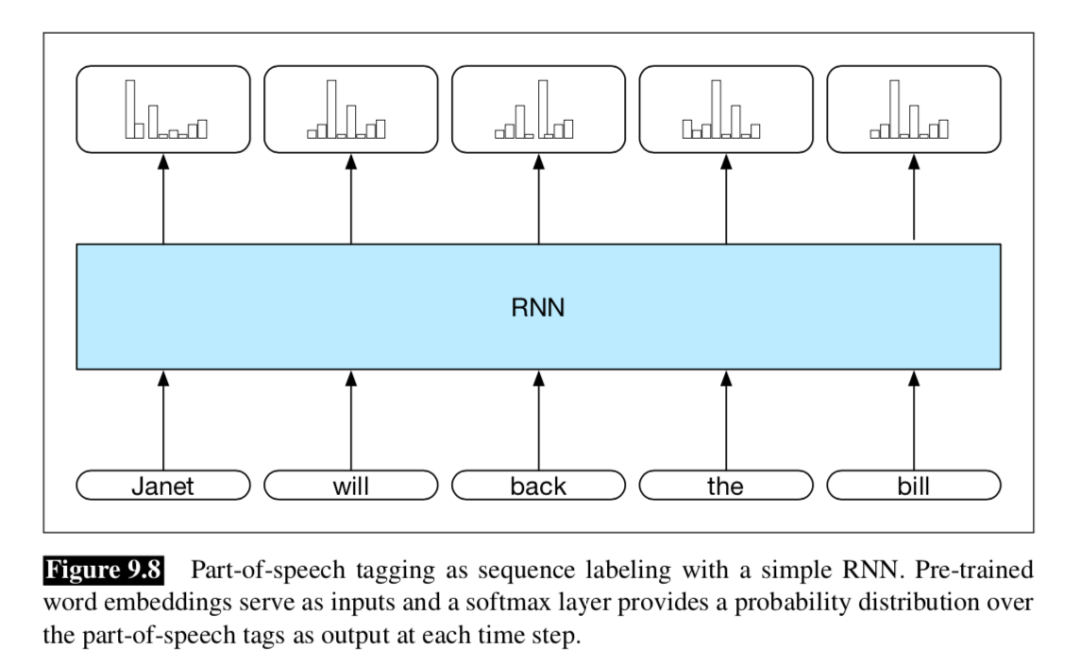
他和生成式任务有什么不一样呢?一是体现在softmax层的概率分布,生成式任务中每个step得到的是词典维度的概率分布,一般词表维度的量级是2、3万;而序列标注任务softmax层的概率维度和标签类别数量一致,维度一般在几维和几十维之间。二是序列标注任务不会用上一个时间步的输出作为输入。 序列标注的标签一般采用 IOB编码,预测每一个单词时类别是B or I or O,标注序列如下:
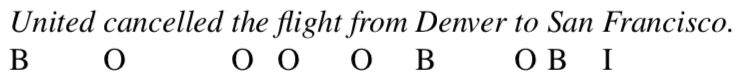 IOB是仅仅是标记,当然可以根据实际情况进行改动。在序列标注中经常会用到HMM、CRF、维比特算法等概率模型知识,因为单词之间,词性之间都是相互关联的,要求解最优解往往离不开这几个知识点。在RNN中他们一般用在softmax层之后,用动态规划的思想来求解最优输出序列。
IOB是仅仅是标记,当然可以根据实际情况进行改动。在序列标注中经常会用到HMM、CRF、维比特算法等概率模型知识,因为单词之间,词性之间都是相互关联的,要求解最优解往往离不开这几个知识点。在RNN中他们一般用在softmax层之后,用动态规划的思想来求解最优输出序列。
文本分类任务
文本分类是对一段文本进行分类,与生成式任务、序列标注任务不同的是,模型在中间的每个时间步都不会输出概率分布,只在最后一个单元输出状态。我们可以认为这个状态积累了整个文本序列的信息。然后在这个状态上,接上全连接层,预测文本的类别。如下图:
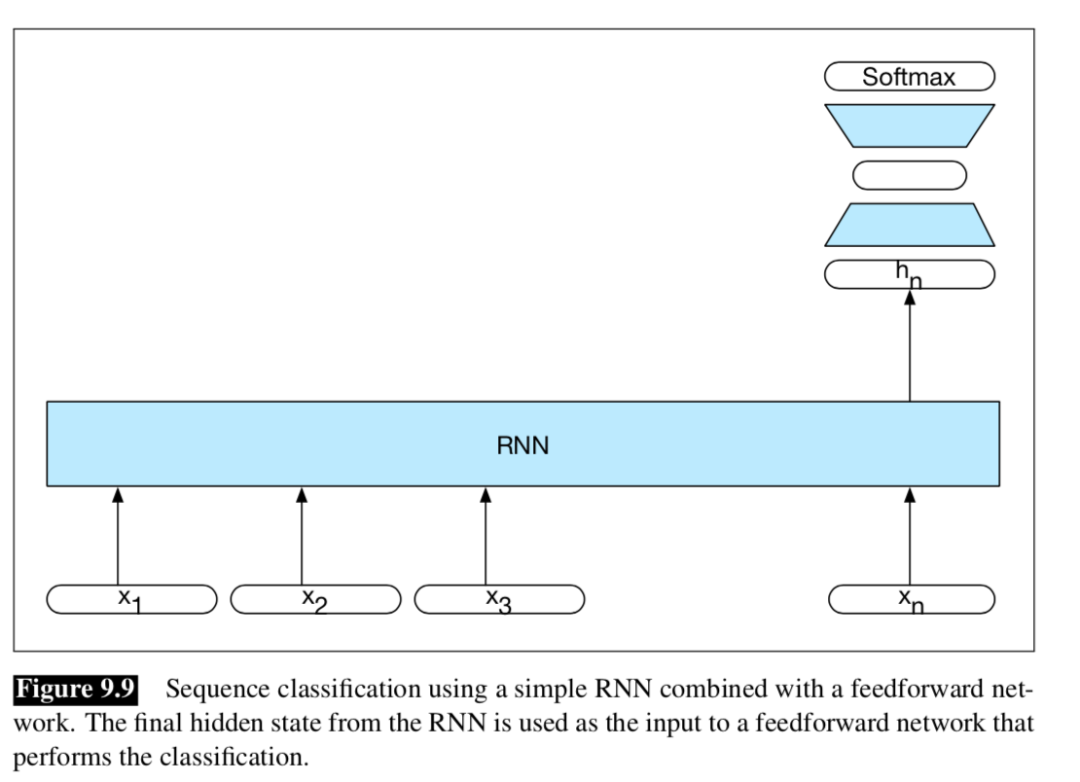
从图中可以看出,模型只在全连接层的最后一层会有损失计算,所以整个网络的梯度更新全靠这个损失值。而在生成式任务、序列标注任务中,每一步都会产生损失值,梯度更新来自多个方向的损失。
原文




