




Benchmarking HTAP databases for performance isolation and real-time analytics.pdf
免费下载
BenchCouncil Transactions on Benchmarks, Standards and Evaluations 3 (2023) 100122
Contents lists available at ScienceDirect
BenchCouncil Transactions on Benchmarks,
Standards and Evaluations
journal homepage: www.keaipublishing.com/en/journals/benchcouncil-transactions-on-
benchmarks-standards-and-evaluations/
Full length article
Benchmarking HTAP databases for performance isolation and real-time
analytics
Guoxin Kang
∗
, Simin Chen, Hongxiao Li
Institute of Computing Technology Chinese Academy of Sciences, China
University of Chinese Academy of Sciences, China
A R T I C L E I N F O
Keywords:
HTAP databases
Benchmark
Performance isolation
Real-time analytics
A B S T R A C T
Hybrid Transactional/Analytical Processing (HTAP) databases are designed to execute real-time analytics and
provide performance isolation for online transactions and analytical queries. Real-time analytics emphasize
analyzing the fresh data generated by online transactions. And performance isolation depicts the performance
interference between concurrently executing online transactions and analytical queries. However, HTAP
databases are extreme lack micro-benchmarks to accurately measure data freshness. Despite the abundance
of HTAP databases and benchmarks, there needs to be more thorough research on the performance isolation
and real-time analytics capabilities of HTAP databases. This paper focuses on the critical designs of mainstream
HTAP databases and the state-of-the-art and state-of-the-practice HTAP benchmarks. First, we systematically
introduce the advanced technologies adopted by HTAP databases for real-time analytics and performance
isolation capabilities. Then, we summarize the pros and cons of the state-of-the-art and state-of-the-practice
HTAP benchmarks. Next, we design and implement a micro-benchmark for HTAP databases, which can
precisely control the rate of fresh data generation and the granularity of fresh data access. Finally, we devise
experiments to evaluate the performance isolation and real-time analytics capabilities of the state-of-the-art
HTAP database. In our continued pursuit of transparency and community collaboration, we will soon make
available our comprehensive specifications, meticulously crafted source code, and significant results for public
access at https://www.benchcouncil.org/mOLxPBench.
1. Introduction
Hybrid Transactional/Analytical Processing (HTAP) databases are
expected to meet the needs of real-time analytics applications [1–
4] because they eliminate the extract-transform-load (ETL) processing
between the OLTP database and data warehouse. HTAP databases
aim to perform real-time analytics on the fresh data generated by
online transactions and mitigate the performance interference between
online transactions and analytical queries. To achieve the objectives
mentioned above, the mainstream HTAP databases use dual data stores
to guarantee performance isolation and optimize the data update prop-
agation between the dual data stores to speed up real-time analytics.
To achieve performance isolation between online transactions and
analytical queries, HTAP databases process online transactions in the
row-based data store and analytical queries in the column-based data
store. HTAP databases optimize the row-based and the column-based
data stores, respectively, to speed the execution of online transactions
and analytical queries. The row-based data store utilizes indexing and
concurrency control mechanisms to facilitate update-intensive online
transactions [2,5–8]. In addition, the column-based data store achieves
∗
Corresponding author.
E-mail addresses: kangguoxin@ict.ac.cn (G. Kang), chensimin22z@ict.ac.cn (S. Chen), lihongxiao19@mails.ucas.ac.cn (H. Li).
a high compression rate and enhanced access for read-intensive analyti-
cal queries [9,10]. HTAP databases generally deploy the row-based and
column-based data store on the different data nodes [11–13] to avoid
high resource contention between online transactions and analytical
queries. This would result in considerable latency when propagating
data updates from the row-based to the column-based data store.
Consequently, optimizing the data update propagation mechanism is
another issue for HTAP databases to address.
Fast data update propagation from the row-based to the column-
based data stores is essential for real-time analytics. The latency of
data update propagation determines the freshness of the analytical
data. The process of data update propagation is divided into three
steps. The first step is moving the data update from the row-based
to the column-based data stores. The second step is translating the
row-format data into column-format data. The last step is merging
the delta updates into the column-based data store. HTAP databases
optimize one or all of the above steps to improve the freshness of
analytical data. For example, TiDB [11] preserves only the committed
change log and removes redundant information before translating it
https://doi.org/10.1016/j.tbench.2023.100122
Received 19 April 2023; Received in revised form 4 July 2023; Accepted 5 July 2023
Available online 8 July 2023
2772-4859/© 2023 The Authors. Publishing services by Elsevier B.V. on behalf of KeAi Communications Co. Ltd. This is an open access article under the CC
BY-NC-ND license (http://creativecommons.org/licenses/by-nc-nd/4.0/).

G. Kang, S. Chen and H. Li BenchCouncil Transactions on Benchmarks, Standards and Evaluations 3 (2023) 100122
Table 1
The key designs of HTAP databases: can HTAP benchmarks evaluate them?
Benchmark name Performance isolation Real-time analytics Component performance
OLTP workloads OLAP workloads Fresh data generation rate Fresh data access granularity Index mechanism Query range control
CH-benCHmark
√ √
HTAPBench
√ √
CBTR
√ √
OLxPBench
√ √
HATtrick
√ √
ADAPT
√ √ √
HAP
√ √ √
Micro-benchmark
√ √ √ √ √ √
into column-format data to decrease data movement. In contrast to
TiDB, which deploys the row-based and column-based data stores on
separate data nodes, some HTAP databases [9,14–17] deploy the row-
based and column-based data stores on the same server to prevent data
update propagation across the different data nodes. It slows down the
latency of delta updates moving but poses a significant challenge to
performance isolation.
Equally as important as it is to track advanced technologies for
HTAP databases is to evaluate these HTAP databases. HTAP bench-
marks must measure how well the HTAP databases can do performance
isolation and real-time analytics. We will introduce the existing HTAP
benchmarks from schema design, workload composition, and metrics
as shown in Table 1.
Firstly, there are stitched schema and semantically consistent sch-
ema. The stitched schema is combined with the TPC-C schema [18] and
TPC-H [19] schema. It extracts the New-Order, Stock, Customer, Order-
line, Orders, Item, Warehouse, District, and History relationships from
TPC-C schema [18] to integrate them with the Supplier, Country, and
Region relationships of TPC-H schema [19]. CH-benCHmark [20] pro-
poses the stitched schema, which is followed by HTAPBench [21] and
Swarm64 [22]. Analytical queries cannot access the valuable data gen-
erated by online transactions and stored in the History table when using
the stitched schema. And the stitched schema will affect the semantics
of HTAP benchmarks. Therefore, OLxPBench [23] advocates that HTAP
benchmarks should employ the semantically consistent schema instead
of the stitched schema. The semantically consistent schema emphasizes
that online transactions and analytical queries access the same schema.
Analytical queries can access all business data generated by online
transactions. The semantically consistent schema can thus reveal the
performance inference between OLTP and OLAP workloads. CBTR [24,
25], OLxPBench [23], HATtrick [26], ADAPT [27], and HAP [28]
benchmark all employ semantically consistent schema described in
Sections 5 and 6.
Secondly, HTAP benchmarks include OLTP workloads, OLAP work-
loads, and hybrid workloads. OLTP workloads combine read and write
operations, whereas OLAP workloads are read-intensive. Hybrid work-
load refers to the analytical query performed between online transac-
tions. Existing HTAP benchmarks include OLTP and OLAP workloads
to investigate performance inference between them. OLxPBench is the
only benchmark that evaluates the true HTAP capability of HTAP
databases using hybrid workloads. Complex online transactions and
analytical queries have a lot of operations, so it is hard to judge how
well each operation works on its own. ADAPT [27] and HAP [28]
are Micro-benchmarks for a specific operation. However, the ADAPT
and HAP benchmarks only include a handful of typical HTAP work-
loads. ADAPT and HAP, for instance, include an insufficient number of
scan queries to evaluate index performance. Micro-benchmarks should
provide point scans, small-range and large-range queries for HTAP
database evaluation. There are a few Micro-benchmarks available for
HTAP databases.
Thirdly, the metrics of HTAP databases are separated into two
categories: throughput metrics and latency metrics. The HTAP database
evaluates the throughput of OLTP workloads using the transactions per
second (tps) and transactions per minute (tpmC) metrics. The HTAP
database evaluates the throughput of OLAP workloads using the queries
completed per second (qps) and queries completed per hour (QphH)
metrics. CH-benCHmark [20] proposes the metrics
𝑡𝑝𝑚𝐶
𝑄𝑝ℎ𝐻
@𝑡𝑝𝑚𝐶 and
𝑡𝑝𝑚𝐶
𝑄𝑝ℎ𝐻
@𝑄𝑝ℎ𝐻 for evaluating the performance isolation between OLTP
and OLAP workloads. The former metric considers online transactions
the primary workload, while the latter considers analytical queries
the primary workload. In contrast, Anja Bog et al. [26]. establish
the HATtrick benchmark, which equalizes transactional and analytical
workloads. HATtrick [26] defines the throughput frontier and freshness
metrics for measuring performance isolation and data freshness, as
specified in Section 5.5. HTAP benchmarks utilize average latency and
tail latency metrics in addition to throughput metrics. Average latency
is the average time it takes for a transaction/query to be processed,
whereas tail latency refers to the high percentile latency. Tail latency
is an important metric to consider in HTAP databases where a small
number of lengthy transactions/queries can substantially impact overall
performance or user experience.
This paper makes the following contributions. (1) We systematically
introduce the advanced technologies adopted by HTAP databases for
these key designs; (2) We summarize the pros and cons of the state-
of-the-art and state-of-the-practice HTAP benchmarks for key designs
of HTAP databases; (3) We quantitatively compared the differences
between micro-benchmarks and macro-benchmarks in evaluating the
real-time analytical capabilities of HTAP databases. Micro-benchmark
can control the generation and access granularity of fresh data, en-
abling precise measurement of real-time analytical capabilities of HTAP
databases. (4) We measure the performance of individual components
of the HTAP database, such as the indexing mechanism. By isolating
specific operations, developers can test the performance of these com-
ponents under different workloads and configurations, which is the
foundation of component optimization.
2. Motivation — Micro-benchmarks can control the rate at which
fresh data is generated and the granularity of access, which dis-
tinguishes them from macro-benchmarks
HTAP databases are extreme lack the micro-benchmark because
there is no open-source micro-benchmark. We design and implement
a micro-benchmark to investigate the distinction between the micro-
benchmark and the macro-benchmark. We select the state-of-the-art
HTAP benchmark OLxPBench as the micro-benchmark comparison ob-
ject. Micro-benchmark is better suited for real-time analytics evaluation
because it precisely controls the rate at which fresh data is generated
and the granularity of fresh data access. Micro-benchmark queries
typically consist of a single statement. For instance, the analytical query
calculates the number of rows within a specified range. This indicates
that the computational intensity of analytical queries can be managed
by adjusting their computational range. And the transactional query
updates the value of the specified column in a random row.
Micro-benchmark can adjust the rate at which fresh data is gener-
ated to assess the performance of data update propagation between the
transactional and analytical instances. The performance interference
between transactional and analytical queries can be disregarded when
2
G. Kang, S. Chen and H. Li BenchCouncil Transactions on Benchmarks, Standards and Evaluations 3 (2023) 100122
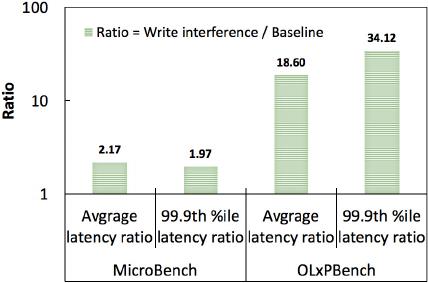
Fig. 1. This figure reveals that the micro-benchmark can accurately measure the
real-time analytical capabilities of the HTAP database by controlling read and write
interference.
the number of concurrent requests is low. Consequently, almost all of
the growing proportion of analytical latency is due to the propagation
of data updates. The online transactions and analytical queries in OLxP-
Bench are too complex to control the write and read ranges precisely.
The New-Order transaction, for instance, involves numerous inserting
and updating operations. The analytical query (Q6) includes operations
involving aggregation and sub-selection. This causes the New-Order
transaction to generate fresh data that is only partially required by
the analytical query (Q6). However, the analytical query must wait for
all data updates to propagate before accessing the fresh data. Unlike
OLxPBench, micro-benchmark makes it simple to control the rate at
which fresh data is generated and the granularity of access to analytical
queries on fresh data.
Fig. 1 compares the impact of simple write operations and the
New-Order transaction on the measurement of data freshness. The
New-Order transaction includes an excessive number of updating and
inserting operations, thereby introducing data synchronization that is
unnecessary for measuring data freshness. The greater the ratio, the
more data needs to be synchronized. It demonstrates that the tail la-
tency of analytical queries (Baseline) increases approximately one-fold
when the micro-benchmark is used to simulate write interference. The
New-Order transaction contains numerous inserting and updating op-
erations, so the tail latency of the baseline (Q6) increases by more than
36 times when OLxPBench is used. The greater the number of inserting
and updating operations, the greater the number of data updates that
must be synchronized between transactional and analytical instances.
However, not all data updates resulting from online transactions are
required for analytical queries. The data freshness measurement will be
affected by data updates that are not required by the analytical query.
Measuring data freshness requires precise control over the rate of fresh
data generation and access granularity.
3. Key designs of mainstream HTAP databases
The mainstream HTAP databases are designed for two objects:
real-time analytics and performance isolation. Performance isolation
emphasizes that online transactions and analytical queries execute
concurrently without affecting each other’s performance. Real-time an-
alytics means analyzing the fresh data generated by online transactions
as soon as possible. Online transactions and analytical queries can
achieve superior isolation performance through the use of indepen-
dent storage engines. However, the necessity of data synchronization
between row-based and column-based storage engines undeniably in-
troduces data synchronization latency. Consequently, real-time access
to fresh data during analytical queries becomes a formidable challenge.
Therefore, it is challenging for HTAP databases to provide real-time
analytics and performance isolation capabilities. Some HTAP databases
deploy the transactional and analytical instances on the same server
to avoid long turnaround times for delta updates. And other HTAP
databases handle online transactions and analytical queries on sepa-
rate servers to prevent performance interference. This section studies
how HTAP databases accomplish real-time analytics and performance
isolation.
3.1. Performance isolation
Single-node HTAP databases implement row-based data storage
for online transactions and column-based data storage for analyti-
cal queries. Because of the intense resource contention, single-node
HTAP databases cannot provide performance isolation [29]. Previous
works [30,31] have proposed various approaches to partitioned hard-
ware resources to ensure performance isolation. Raza et al. [30] divide
the CPU and memory resources into two groups: the first group binds
with the specified transactional instance and analytical instance. In
contrast, the second group comprises reserved resources assigned based
on actual requirements. By dividing the last-level cache (LLC) between
the analytical queries and the online transactions, Sirin et al. [31]
reduce the performance impact of the analytical queries on the online
transactions. Polynesia [15] identifies the root cause of performance
interference as the sharing of hardware resources and consequently
provides an isolated computing resource for online transactions and
analytical queries.
Distributed HTAP databases [11–13] deploy row-based and column-
based data stores on separate servers, thereby wholly resolving the issue
of resource contention. TiDB [11] implements the 𝑇 𝑖𝐾𝑉 and 𝑇 𝑖𝐹 𝑙𝑎𝑠ℎ
instances for row-based and column-based data stores, respectively.
It employs the raft algorithm to replicate asynchronously 𝑇 𝑖𝐾𝑉 logs
to 𝑇 𝑖𝐹 𝑙𝑎𝑠ℎ instances. Due to the collaborative capabilities of Google’s
internal systems, F1 Lightning [12] contributes a loosely coupled HTAP
solution that enables the 𝐹 1 𝑄𝑢𝑒𝑟𝑦 𝑒𝑛𝑔𝑖𝑛𝑒 to function with existing
OLTP systems and data sources [32–37]. As a result, F1 Lightning [12]
need to utilize the 𝐿𝑖𝑔ℎ𝑡𝑛𝑖𝑛𝑔 component to capture the data updates
from various data sources and translate them into the unified format
data.
SingleStore [13] and OceanBase [38] are well-known distributed
HTAP databases. They all utilize unified storage to facilitate online
transactions and analytical queries. OceanBase [38] demonstrates com-
mendable proficiency in resource isolation. PolarDB-IMCI [39] also
provides effective resource isolation for transactional and analytical
queries.
3.2. Real-time analytics
Initially, HTAP databases deploy the transactional and analytical
instances on a single server to obtain the fresh data generated by
online transactions. SAP HANA [9,40] maintains multiple delta update
stores for the same table, allowing online transactions updating and
existing data updates merging process to be performed in different
delta stores. It is permitted for analytical queries to simultaneously
access the freshest data in multiple deltas and column-based data stores.
SAP HANA [9,40], DB2 BLU [17] and Oracle [14] have implemented
an in-memory column-based data store for fast analytics. DB2 [17]
supports HTAP workloads with BLU acceleration. Oracle [14] and DB2
BLU [17] make use of numerous analytical optimization technologies,
including compression and single-instruction multiple-data (SIMD). It
cannot update column data in real-time because data updates are only
merged to the column-based data store when the ratio of data updates
exceeds a certain threshold.
With the growing amount of real-time data, the single-node HTAP
database cannot meet the high scalability and availability require-
ments. Oracle, for instance, releases a new distributed version that
provides scale-out compute and storage resources and implements a
3
of 10
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
最新上传
下载排行榜
1
2
9-数据库人的进阶之路:从PG分区、SQL优化到拥抱AI未来(罗敏).pptx
3
1-PG版本兼容性案例(彭冲).pptx
4
2-TDSQL PG在复杂查询场景中的挑战与实践-opensource.pdf
5
6-PostgreSQL 哈希索引原理浅析(文一).pdf
6
3-AI时代的变革者-面向机器的接口语言(MOQL)_吕海波.pptx
7
8-基于PG向量和RAG技术的开源知识库问答系统MaxKB.pptx
8
4-IvorySQL V4:双解析器架构下的兼容性创新实践.pptx
9
7-拉起PG好伙伴DifySupaOdoo.pdf
10
《云原生安全攻防启示录》李帅臻.pdf

相关文档
评论