




Text-Visual Prompting for Efficient 2D Temporal Video Grounding.pdf
25墨值下载
Text-Visual Prompting for Efficient 2D Temporal Video Grounding
Yimeng Zhang
1,2
, Xin Chen
2
, Jinghan Jia
1
, Sijia Liu
1
, Ke Ding
2
1
Michigan State University,
2
Applied AI, Intel
{zhan1853, jiajingh, liusiji5}@msu.edu,
{xin.chen, ke.ding}@intel.com
Abstract
In this paper, we study the problem of temporal video
grounding (TVG), which aims to predict the starting/ending
time points of moments described by a text sentence within
a long untrimmed video. Benefiting from fine-grained 3D
visual features, the TVG techniques have achieved remark-
able progress in recent years. However, the high complexity
of 3D convolutional neural networks (CNNs) makes extract-
ing dense 3D visual features time-consuming, which calls
for intensive memory and computing resources. Towards
efficient TVG, we propose a novel text-visual prompting
(TVP) framework, which incorporates optimized perturba-
tion patterns (that we call ‘prompts’) into both visual in-
puts and textual features of a TVG model. In sharp con-
trast to 3D CNNs, we show that TVP allows us to effec-
tively co-train vision encoder and language encoder in a
2D TVG model and improves the performance of cross-
modal feature fusion using only low-complexity sparse 2D
visual features. Further, we propose a Temporal-Distance
IoU (TDIoU) loss for efficient learning of TVG. Experi-
ments on two benchmark datasets, Charades-STA and Ac-
tivityNet Captions datasets, empirically show that the pro-
posed TVP significantly boosts the performance of 2D TVG
(e.g., 9.79% improvement on Charades-STA and 30.77%
improvement on ActivityNet Captions) and achieves 5× in-
ference acceleration over TVG using 3D visual features.
Codes are available at Open.Intel.
1. Introduction
In recent years, we have witnessed great progress on
temporal video grounding (TVG) [30, 74]. One key to
this success comes from the fine-grained dense 3D vi-
sual features extracted by 3D convolutional neural networks
(CNNs) (e.g., C3D [56] and I3D [3]) since TVG tasks de-
mand spatial-temporal context to locate the temporal inter-
val of the moments described by the text query. However,
due to the high cost of the dense 3D feature extraction, most
existing TVG models only take these 3D visual features ex-
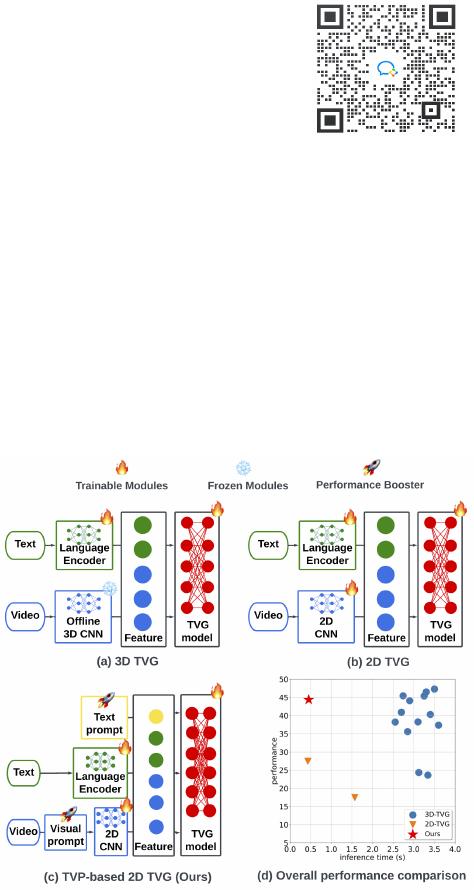
Figure 1. The architecture and performance comparison among TVG
methods: a) 3D TVG methods [14, 16, 18, 34, 43,60–62,64, 67, 69, 71, 73],
b) 2D TVG methods [1, 7], and c) TVP-based 2D TVG (Ours), d) over-
all performance comparison. Ours is the most efficient (least inference
time) and achieves competitive performance compared to 3D TVG meth-
ods. In contrast to existing TVG methods, which utilize dense video fea-
tures extracted by non-trainable offline 3D CNNs and textual features, our
proposed framework utilizes a trainable 2D CNN as the vision encoder to
extract features from sparsely-sampled video frames with a universal set of
frame-aware visual prompts and adds text prompts in textual feature space
for end-to-end regression-based modeling.
tracted by offline 3D CNNs as inputs instead of co-training
during TVG model training.
Although models using 3D visual features (that we
call ‘3D methods or models’) outperform these using the
2D features (that we call ‘2D methods or models’), a
unique advantage of 2D methods is that extracting 2D
visual features can significantly reduce the cost in TVG
tasks [14, 15, 30, 34, 61, 62, 69, 74, 75]. An efficient and
lightweight solution with reasonable performance is also
demanded in computer vision, NLP, and video-language
tasks [19, 23, 38, 41, 68, 76–80]. As discussed above, the
methods employing 3D video features are challenging to be
arXiv:2303.04995v2 [cs.CV] 22 Mar 2023
employed in practical applications. It thus has significant
practical and economic value to develop compact 2D solu-
tions for TVG tasks. In this paper, we ask:
How to advance 2D TVG methods so as to achieve
comparable results to 3D TVG methods?
To address this problem, we propose a novel text-visual
prompting (TVP) framework for training TVG models us-
ing 2D visual features. As shown in Fig. 1, for existing
2D TVG and 3D TVG methods, they all utilize offline pre-
trained vision encoders and language encoders to perform
feature extraction. In contrast, our proposed TVP frame-
work is end-to-end trainable. Furthermore, benefiting from
text-visual prompting and cross-modal pretraining on large-
scale image-text datasets, our proposed framework could
achieve comparable performance to 3D TVG methods with
significant inference time acceleration.
Conventionally, TVG methods consist of three stages:
¬ extracting feature from visual and text inputs; multi-
modal feature fusion; ® cross-modal modelling. In contrast
to conventional methods, TVP incorporates optimized input
perturbation patterns (that we call ‘prompts’) into both vi-
sual inputs and textual features of a TVG model. We apply
trainable parameters in the textual features as text prompts
and develop a universal set of frame-aware patterns as visual
prompts. Specially, we sample a fixed number of frames
from a video and optimize text prompts for the input query
sentence and a set of visual prompts for frames with differ-
ent temporal locations during training. During testing, the
same set of optimized visual prompts and textual prompts
are applied to all test-time videos. We refer readers to Fig. 2
for illustrations of visual prompts and text prompts intro-
duced. To the best of our knowledge, our work makes the
first attempt to utilize prompt learning to successfully im-
prove the performance of regression-based TVG tasks using
2D visual features.
Compared to 3D CNNs, 2D CNNs loses spatiotempo-
ral information of the video during feature extraction. In-
spired by the success of transformers on the vision-language
tasks [9, 22, 35, 44, 47, 54, 55] and the recent application of
prompt learning to transformers in both vision and language
domains [2,25,27, 32,37,40], we choose transformer as our
base TVG model and propose to utilize prompts to compen-
sate for the lack of spatiotemporal information in 2D visual
features. Furthermore, we develop a Temporal-Distance
IoU (TDIoU) loss for training our proposed framework.
There are two aspects that distinguish our proposed frame-
work from existing works. First
, our proposed framework is
designed to boost the performance of the regression-based
TVG methods utilizing 2D CNNs as the vision encoder,
not for transfer learning [2, 21, 26] Second
, our proposed
framework utilizes 2D CNN to extract visual features from
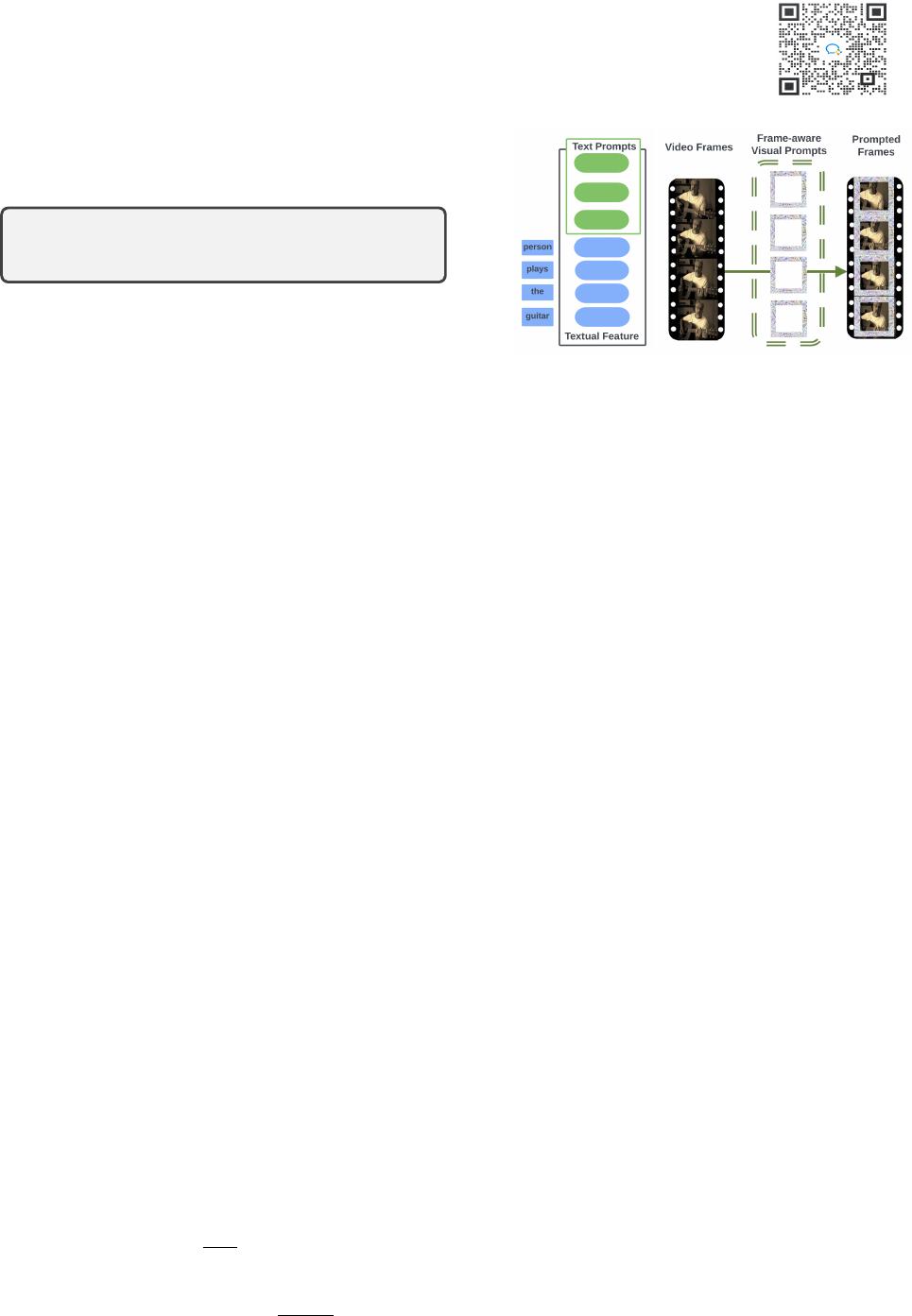
(a) Text Prompts (b) Frame-aware Visual Prompts
Figure 2. Text-visual prompting illustration. (a) Text prompts are directly
applied in the feature space. (b) A set of visual prompts are applied to
video frames in order.
sparsely-sampled video frames, which requires less mem-
ory and is easier to be applied in practical applications com-
pared to 3D methods [34,60–62,69,75], especially for long
videos. Furthermore, thanks to the compact 2D CNN as
the vision encoder, our proposed framework could imple-
ment the language encoder and visual encoder co-training
for better multimodal feature fusion. In summary, the con-
tributions of this work are unfolded below:
• We propose an effective and efficient framework to
train 2D TVG models, in which we leverage TVP
(text-visual prompting) to improve the utility of sparse
2D visual features without resorting to costly 3D fea-
tures. To the best of our knowledge, it is the first work
to expand the application of prompt learning for re-
solving TVG problems. Our method outperforms all
of 2D methods and achieves competitive performance
to 3D TVG methods.
• Technology-wise, we integrate visual prompt with text
prompt to co-improve the effectiveness of 2D visual
features. On top of that, we propose TDIoU (temporal-
distance IoU)-based prompt-model co-training method
to obtain high-accuracy 2D TVG models.
• Experiment-wise, we show the empirical success of
our proposal to boost the performance of 2D TVG on
Charades-STA and ActivityNet Captions datasets, e.g.,
9.79% improvement in Charades-STA, and 30.77% in
ActivityNet-Captions together with 5× inference time
acceleration over 3D TVG methods.
2. Related Work
Video Temporal Grounding (TVG). The objective of the
TVG is to predict the starting/ending time points of target
moments within an untrimmed video, which is described by
a text sentence. Early TVG solutions [7,14,20,39,62,64,70]
mainly employ two-stage “propose-and-rank” pipeline: ¬
of 11
25墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
dba
最新上传
下载排行榜
1
2
9-数据库人的进阶之路:从PG分区、SQL优化到拥抱AI未来(罗敏).pptx
3
1-PG版本兼容性案例(彭冲).pptx
4
2-TDSQL PG在复杂查询场景中的挑战与实践-opensource.pdf
5
6-PostgreSQL 哈希索引原理浅析(文一).pdf
6
8-基于PG向量和RAG技术的开源知识库问答系统MaxKB.pptx
7
3-AI时代的变革者-面向机器的接口语言(MOQL)_吕海波.pptx
8
4-IvorySQL V4:双解析器架构下的兼容性创新实践.pptx
9
7-拉起PG好伙伴DifySupaOdoo.pdf
10
《云原生安全攻防启示录》李帅臻.pdf

评论