



1

向量数据库.pdf
25墨值下载

开个新坑,本系列文章将为您介绍,什么是向量数据库,为什么需要一个专用的向量数据库,向量数据
库的底层架构原理有哪些?都涉及哪些算法?感兴趣的小伙伴多多留言点赞,如果对这方面的内容已经
有了一定了解,也可以体验一下星环科技推出的向量数据库社区版:Hippo社区版下载及安装资源
背景--向量数据的产生
伴随互联网、移动互联网、物联网、5G等信息通信技术及产业的发展,全球数据量呈现爆发式增长的趋
势。从智能设备收集的物联网 (IoT) 数据,到Web 应用程序或移动应用程序生成的用户行为数据,再到
上传到社交媒体的视频,数据的生成速度呈指数级增长。根据International Data Corporation(IDC)
数据显示,到2028 年,全球数据圈(global datasphere)(一种用于衡量全球永久性存储中创建、采
集和存储的新数据总量的指标)预计将增长到 400 ZB(泽字节)(1 ZB = 1021 字节)。 届时,30%以
上的数据将是实时生成的,而所有生成的数据中,80%将是非结构化数据。
什么非是结构化数据?
非结构化数据指的是无法以预定义格式存储或适合现有数据模型的数据,比如图像、视频、音频、用户
行为等等。除了这些之外也有一些没那么常见的非结构化数据,比如蛋白质分子结构。这些数据不像结
构化数据,无法定义为行和列的关系,尽管可以通过以标签的形式来标记这些数据,但是如果涉及图像
或者是涉及上下文的语义搜索,则无法简单的通过打标签的形式来进行管理。
非结构化数据示例
非结构化数据可以由机器或人类生成。机器生成的非结构化数据的示例包括:
传感器数据:从传感器收集的数据,例如温度传感器、湿度传感器、GPS 传感器和运动传感器;
机器日志数据:机器、设备或应用程序产生的数据,包括系统日志、应用程序日志和事件日志;
物联网 (IoT) 数据:从智能恒温器、智能家居助理和可穿戴设备等智能设备收集的数据;
计算机视觉数据:这是由计算机视觉技术生成的非结构化数据,例如图像识别、对象检测和视频分
析生成的非结构化数据;
自然语言处理 (NLP) 数据:由 NLP 技术生成的数据,例如语音识别、语言翻译和情感分析;
Web和应用程序数据:Web服务器、Web应用程序和移动应用程序生成的数据,包括用户行为数
据、错误日志和应用程序性能数据;
人类生成的非结构化数据的示例包括:
电子邮件:电子邮件通常是非结构化的,可以包含自由格式的文本、图像和附件;
短信:短信可以是非正式的、非结构化的,比如包含缩写或表情符号等等;
社交媒体:社交媒体内容的结构和内容可能有所不同,包括文本、图像、视频和主题标签;
录音:人类生成的录音可以包括电话、语音邮件、音频文件和音频笔记,这些都是非结构化数据;
手写笔记:手写笔记可以是非结构化的,包含绘图、图表和其他视觉元素;
会议记录:会议记录可以包含非结构化文本、图表和操作项;
文字记录:演讲、采访和会议的文字记录可以包含不同程度准确度的非结构化文本;
用户生成的内容:网站和论坛上的用户生成的内容可以是非结构化数据,包括自由格式的文本、图
像和视频文件;
与结构化/半结构化数据不同,非结构化数据的大小、格式各不相同,涉及截然不同的特征及索引。
以图像为例,如果对一样物品连续拍了三张照片,尽管这三张照片都是同一样物品在同一环境中拍摄
的,但是他们的像素值、分辨率、文件大小、拍摄时间等等可能大不相同。
再比如说以狗狗为例,对于我们人类来说区分狗狗会比较容易,因为我们可以多角度的去观察去了解它
们不同的特征。但是如果想要通过数据去表述,则需要增加更多维度的信息辅助分析,比如他们的体
型、毛发的长短、鼻子的长短、服从性,攻击性等等。
非结构化数据真正有意义的地方不在于数据本身的物理表示,而在于他背后隐藏的语义特征。
因此,这对需要应用此类数据的公司及相关行业提出了新的挑战:我们应该如何以类似于结构化/半结构
化数据的方式来转换、存储和搜索此类非结构化数据?如果非结构化数据没有固定的大小和格式,我们
应该如何搜索和分析它?
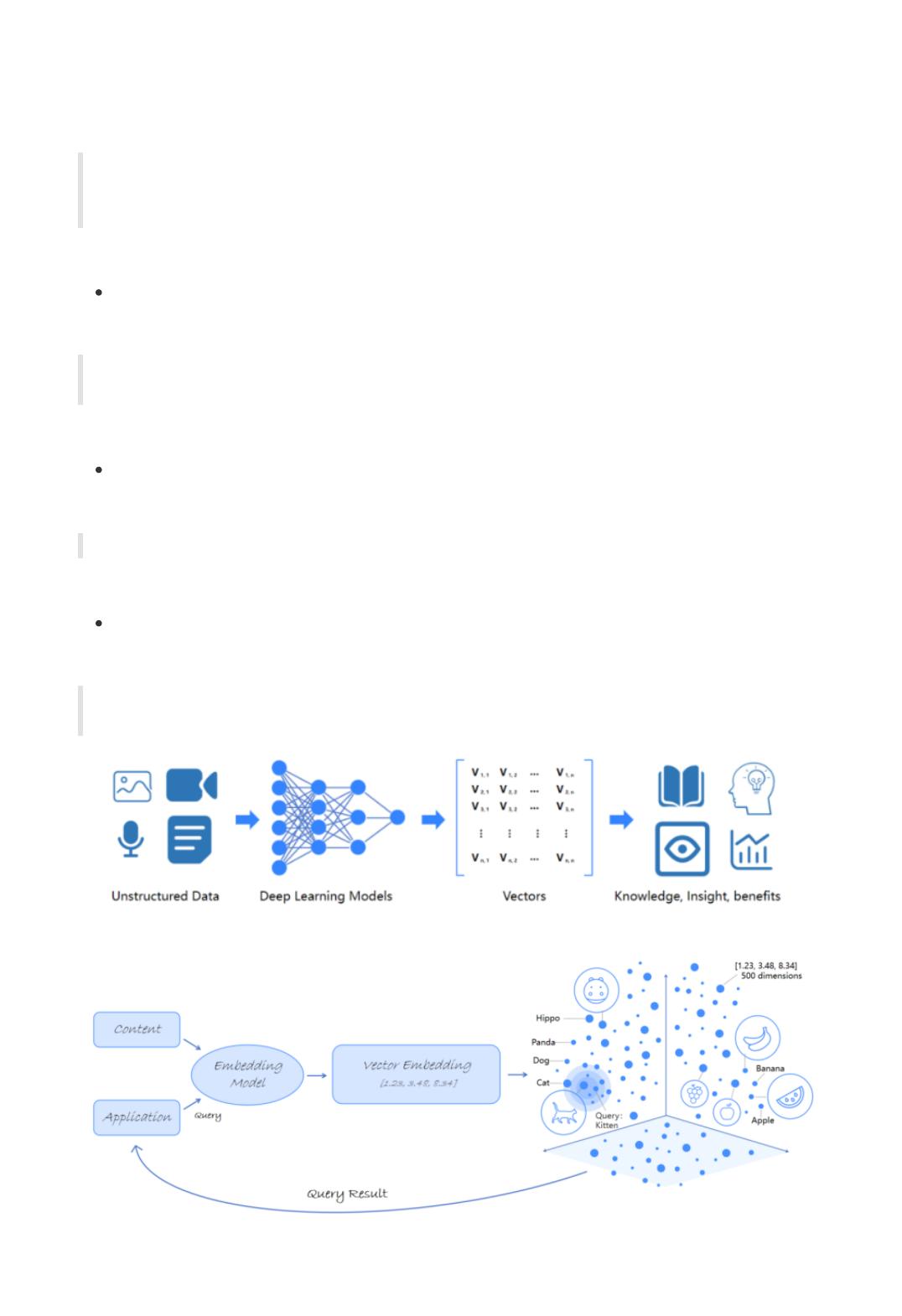
答案是:利用机器学习(或者更具体地说,深度学习)模型的嵌入功能来将真实世界数字化的抽象出
来。

在过去十年中,大数据和深度神经网络的结合从根本上改变了我们处理数据驱动应用程序的方式,比如
大型语言模型、生成式 AI 和语义搜索的应用程序等等,这些应用程序可以以极快的速度筛选庞大的数据
集,产生创新的见解,为业务赋能。大部分AI技术,比如像神经网络模型能够将非结构化数据背后的语
义特征进行识别、提取,转换为浮点值列表,映射或者嵌入到一个高维的向量空间里。其中,依赖的则
是嵌入以及嵌入向量的功能。
嵌入向量(Embedding vectors),也被成为向量嵌入或特征向量,是一种数据表示,具有大量属
性或特征,例如照片的组成部分、视频中的选定帧、地理空间数据等等。在人工智能和机器学习的
背景下,这些特征代表了数据的不同维度,这些维度对于理解模式、关系和底层结构至关重要,可
以便于AI理解并执行复杂任务,比如以图搜图等等。经过适当训练的神经网络模型可以输出表示各
类语义信息的嵌入,如图像。
嵌入(Embedding)则是将各类非结构化数据进行抽象转化为多维向量,并描述出这些实体之间的
种种关系的过程。
传统的数据库没有办法直接去处理非结构化数据背后的语义特征信息,所以嵌入技术将这种无法直接处
理的原始数据的特征信息,做了一个结构化的一个过程。
向量数据库介绍
在大语言模型出现之前(2020 年以前),向量检索这项技术就已经发展成熟。随着深度学习的技术,这
些数据可以被提取出来,广泛应用于图片、音频、视频的搜索和推荐、人脸识别、语音识别等传统人工
智能应用领域。
但是,基于标量的数据库不具有处理这类型数据的能力,难以有针对性的执行实时分析,进行业务价值
的挖掘。因此,既能够存储、处理此类嵌入向量数据,又能够充分利用这些数据,提供所需性能及其他
特性的专用数据库至关重要。
向量数据库是一种用来存储,检索,分析及管理海量向量式数据集的数据库,可以高效存储和索引由AI
模型产生的向量嵌入数据。
向量数据库与传统关系型数据库协同发展、相互补充。针对传统关系型数据库难以处理的大规模数据、
低时延高并发检索、模糊匹配等领域,向量数据库可以通过数据的向量化来满足特定需求,尤其适用于
相似性搜索、机器学习以及人工智能领域。以下是向量数据库的一些优势:
高维搜索:向量数据库可以高效、快速地对高维向量数据进行相似性搜索,常用于机器学习和人工
智能应用,例如图像识别、自然语言处理和推荐系统;
可扩展性:向量数据库可以水平扩展,高效存储和检索大量向量数据。可扩展性对于需要实时搜索
和检索大量数据的应用程序来说非常重要;
灵活性:向量数据库可以处理各种向量数据类型,包括稀疏向量和稠密向量。 它们还可以处理多种
数据类型,包括数字、文本和二进制等等;
高性能:向量数据库可以高效地执行相似性搜索,检索效率通常来说比传统的数据库更高;
可定制的索引:向量数据库允许针对特定场景和数据类型定制索引方案;
向量数据库的能力
向量数据库是一种特殊类型的数据库,它可以存储和处理海量的向量数据,进行:
向量检索
根据给定的向量,找出数据库中与之最相似的向量,例如在图像向量数据库中,用户输入一张图片
进行搜索时,先将这张图片转换为一个向量,通过向量之间的近似检索,找到与输入图片最相似的
图片;
向量聚类
根据给定的相似度度量,将数据库中的向量分类,例如根据图片的内容或风格,将图片分成不同的
主题;
向量降维
根据给定的目标维度,将数据库中的高维向量转换成低维向量,以便于可视化或压缩存储;
向量计算
根据给定的算法或模型,对数据库中的向量进行计算或分析,例如根据神经网络模型,对图片进行
分类或标注;
为了更好地理解向量数据库在此类应用中的作用,可以参考下图:
大概流程是通过使用embedding model为我们要索引的内容创建向量嵌入,然后接下来向量嵌入被导入
到向量数据库中。当应用发起查询时,我们使用相同的嵌入模型为查询操作创建嵌入,并使用这些嵌入
在数据库中查询类似的向量嵌入与原始内容相关联,然后返回结果。
of 18
25墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
江苏沙钢集团
最新上传
下载排行榜
1
2
centos7下oracle11.2.0.4 rac安装详细图文(虚拟机模拟多路径).docx
3
白鳝-DBAIOPS:国产化替换浪潮进行时,信创数据库该如何选型?.pdf
4
PostgreSQL 缓存命中率低?可以这么做.doc
5
达梦数据2024年年度报告.pdf
6
李飞-AI 引领的企业级智能分析架构演进与行业实践.pdf
7
刘晓国-基于 Elasticsearch 创建企业 AI 搜索应用实践.pdf
8
晋鑫宇_AI Agent 赋能社交媒体-构建未来社交生态的核心驱动力.pdf
9
刘杰-江苏广电:从Oracle+Hadoop到TiDB,数据中台、实时数仓运维0负担.pdf
10
Sunny duan-大模型安全挑战与实践:构建 AI 时代的安全防线.pdf

相关文档
评论