




【李国良论文】Vector Database Management Techniques and Systems.pdf
免费下载
Vector Database Management Techniques and Systems
James Jie Pan
jamesjpan@tsinghua.edu.cn
Tsinghua University
Beijing, China
Jianguo Wang
csjgwang@purdue.edu
Purdue University
West Lafayette, Indiana, USA
Guoliang Li
liguoliang@tsinghua.edu.cn
Tsinghua University
Beijing, China
ABSTRACT
Feature vectors are now mission-critical for many applications, in-
cluding retrieval-based large language models (LLMs). Traditional
database management systems are not equipped to deal with the
unique characteristics of feature vectors, such as the vague notion
of semantic similarity, large size of vectors, expensive similarity
comparisons, lack of indexable structure, and diculty of answering
“hybrid” queries that combine structured attributes with feature vec-
tors. A number of vector database management systems (VDBMSs)
have been developed to address these challenges, combining novel
techniques for query processing, storage and indexing, and query
optimization and execution and culminating in a spectrum of perfor-
mance and accuracy characteristics and capabilities. In this tutorial,
we review the existing vector database management techniques and
systems. For query processing, we review similarity score design
and selection, vector query types, and vector query interfaces. For
storage and indexing, we review various indexes and discuss com-
pression as well as disk-resident indexes. For query optimization
and execution, we review hybrid query processing, hardware ac-
celeration, and distibuted search. We then review existing systems,
search engines and libraries, and benchmarks. Finally, we present
research challenges and open problems.
CCS CONCEPTS
• Information systems → Data management systems.
KEYWORDS
Vector Database, Vector Similarity Search, Dense Retrieval, 𝑘-NN
ACM Reference Format:
James Jie Pan, Jianguo Wang, and Guoliang Li. 2024. Vector Database
Management Techniques and Systems. In Companion of the 2024 Inter-
national Conference on Management of Data (SIGMOD-Companion ’24),
June 9–15, 2024, Santiago, AA, Chile. ACM, New York, NY, USA, 8 pages.
https://doi.org/10.1145/3626246.3654691
1 INTRODUCTION
High-dimensional feature vectors are now used in a variety of
dense retrieval search applications, including retrieval-based large
language models (LLMs) [
28
,
31
,
51
], e-commerce [
54
], recommen-
dation [
82
], document retrieval [
76
], and so on [
45
,
51
,
79
,
84
]. These
applications may involve billions of vectors and require millisecond
This work is licensed under a Creative Commons Attribution
International 4.0 License.
SIGMOD-Companion ’24, June 9–15, 2024, Santiago, AA, Chile
© 2024 Copyright held by the owner/author(s).
ACM ISBN 979-8-4007-0422-2/24/06.
https://doi.org/10.1145/3626246.3654691
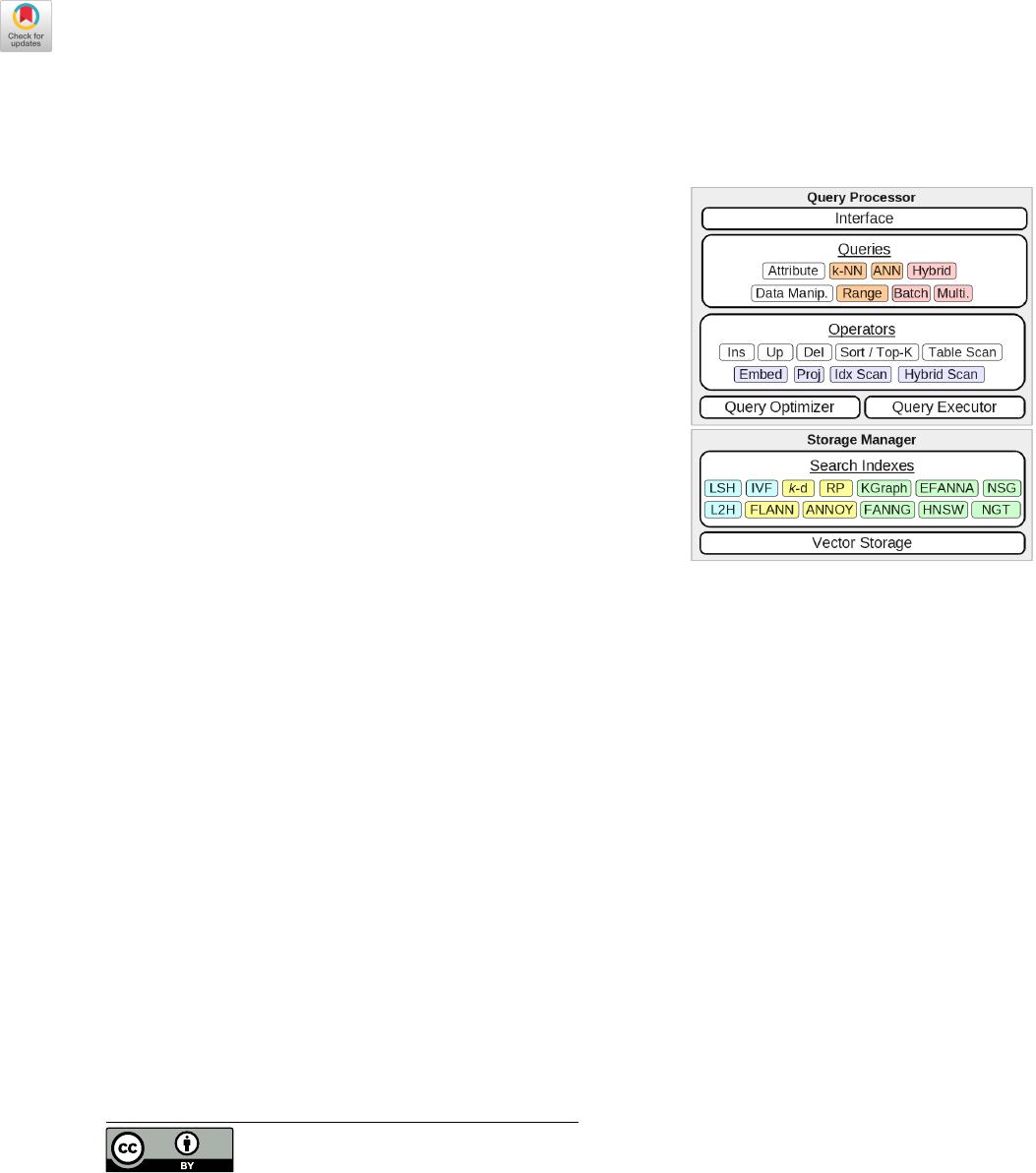
Figure 1: Overview of a VDBMS (Vector Database Manage-
ment System).
query latencies, all while needing to scale to increasing workloads
without sacricing performance or response quality.
But existing traditional database management systems, includ-
ing NoSQL and relational databases, are not designed for these
datasets and workloads. First, vector queries rely on the concept of
similarity which can be vague for dierent applications, requiring
a dierent query specication. Second, similarity computation is
more expensive than other types of comparisons seen in relational
predicates, requiring ecient techniques. Third, processing a vector
query often requires retrieving full vectors from the collection. But
each vector may be large, possibly spanning multiple disk pages,
and the cost of retrieval is more expensive compared to simple
attributes while also straining memory. Fourth, vector collections
lack obvious properties that can be used for indexing, such as being
sortable or ordinal, preventing the use of traditional techniques. Fi-
nally, “hybrid” queries require accessing both attributes and vectors
together, but it remains unclear how to do this eciently.
These challenges have led to the rise of vector database man-
agement systems (VDBMSs) specially adapted for these applica-
tions, and there are now over 20 commercial VDBMSs developed
within the past ve years. A typical VDBMS is composed of a query
processor and a storage manager (Figure 1). For the query proces-
sor, VDBMSs introduce new approaches to query interfaces, query
types such as
𝑘
-nearest-neighbor search, hybrid, and multi-vector
queries, and data operators such as similarity projection and hybrid
index scan. New techniques have also been proposed for query
597
SIGMOD-Companion ’24, June 9–15, 2024, Santiago, AA, Chile James Jie Pan, Jianguo Wang, and Guoliang Li
optimization and execution, including plan enumeration and se-
lection for hybrid query plans and hardware accelerated search.
For the storage manager, several techniques for large-scale vector
indexing and vector storage are now available, including hashing
and quantization-based approaches like
PQ
[
1
] and IVFADC [
49
]
that tend to be easy to update; tree-based indexes like FLANN [
62
]
and ANNOY [
2
] that tend to support logarithmic search complex-
ity; and graph-based indexes like HNSW [
58
] and others that are
ecient in practice but with less theoretical understanding. To-
gether, these techniques culminate into a variety of native systems,
extended systems, and search engines and libraries over a spectrum
of performance and accuracy characteristics and capabilities.
In this tutorial, we review techniques and systems for vector
data management along with benchmarks, followed by remaining
challenges and open problems.
Tutorial Overview. This tutorial contains three parts and the
intended length is 1.5 hours. The rst part discusses specic tech-
niques and will last 50 minutes.
(1) Query Processing (10 min.). Query processing begins with a search
specication that denes the search parameters. These include
considerations for similarity score design, score selection and the
curse of dimensionality [
22
,
30
,
61
], the query type such as basic,
multi-vector, and hybrid queries [79, 84], and the query interface.
(2) Storage and Indexing (30 min.). Vector indexes tend to rely on
novel partitioning techniques such as randomization, learned par-
titioning, and navigable partitioning. The performance, accuracy,
and storage characteristics of an index depend on the techniques
used and the index structure. We classify indexes into table, tree, or
graph-based, and then describe the techniques for each index type.
To deal with large size, we also discuss vector compression using
quantization [49, 59] and disk-resident indexes [32, 74].
(3) Optimization and Execution (10 min.). For processing hybrid
queries, several plan enumeration and plan selection techniques
have been proposed, including rule-based [
3
,
4
] and cost-based
selection [
79
,
84
], and which also introduce new hybrid operators
including block-rst scan [
43
,
79
,
84
,
87
] and visit-rst scan [
43
,
87
]. Several techniques also speed up vector search via hardware
acceleration using SIMD [
26
,
27
], GPUs [
50
], and distributed search.
To address slow index updates, some VDBMSs also rely on out-of-
place updates.
The second part discusses vector database management systems
and will last 30 minutes.
(1) Native Systems (10 min). Native systems such as Pinecone [
5
],
Miluvs [
6
,
79
], and Manu [
45
] aim at high performance vector
search applications by oering a narrower range of capabilities.
(2) Extended Systems (10 min). For applications that require more so-
phisticated capabilities, several extended systems such as AnalyticDB-
V [
84
], PASE [
90
],
pgvector
[
7
], and Vespa [
4
] have been developed
based on NoSQL or relational systems.
(3) Search Engines and Libraries (5 min). Several search engines such
as Apache Lucene [
8
] and Elasticsearch [
9
] now also incorporate
vector search capability via integrated vector indexes. Several li-
braries are also available such as Meta Faiss [
1
] that provide vector
search functionality.
(4) Benchmarks (5 min). We describe two notable benchmarks that
evaluate a wide variety of search algorithms and systems over a
range of workloads [29, 91].
The nal part discusses challenges and open problems (10 min.).
We describe several fundamental challenges, including how to per-
form similarity score selection, design more ecient hybrid oper-
ators and indexes, and estimate the cost of hybrid plans. We also
describe future applications, including index-supported incremental
search, multi-vector search, and enhancing security and privacy.
Target Audience. This tutorial is intended for database researchers
interested in understanding and advancing the state-of-art tech-
niques for large-scale vector database management and modern
applications beyond similarity search. This tutorial may also ben-
et industry practitioners interested in learning about the latest
commercial systems. There are no prerequisites beyond a basic
understanding of database concepts.
Related Tutorials. A recent tutorial [
28
] discusses how vector
search can be used for retrieval-based LLMs. There are also separate
tutorials on similarity search techniques [37, 67, 68].
Our tutorial aims to complement these tutorials by focusing
on vector database management systems as a whole, and most of
this tutorial has not been covered elsewhere. Specically, most of
the overlap is conned to Section 2.2, and the extent is not large.
In [
37
], a broad taxonomy of search techniques is given, along
with representative examples. Similarly in [
67
,
68
], an overview of
various exact and approximate search techniques is given. Some
of the material in Section 2.2, mainly locality-sensitive hashing,
learning-to-hash, ANNOY, and HNSW, overlaps with these past
tutorials. But Section 2.2 also discusses key indexing trends in
VDBMSs that have not been discussed in past tutorials, including
disk-based indexes, quantization-based compression approaches for
handling large vector collections, and the diversity of graph-based
indexes. Aside from this section, all other sections in this tutorial
have not been covered elsewhere as they pertain to the VDBMS
as a whole, including query processing, hybrid operators, plan
enumeration, and plan selection, and a survey of existing VDBMSs.
2 TUTORIAL
2.1 Query Processing
Similarity Scores. Dense retrieval works based on similarity. A
similarity score can be used to quantify the degree of similarity be-
tween two feature vectors. While many scores have been proposed,
dierent scores may lead to dierent query results, and so how to
perform score selection is an important problem for VDBMSs, in
addition to score design.
(1) Score Design. A similarity score is designed to accurately capture
similarity relationships between feature vectors. Existing similarity
scores can be classied as basic scores, aggregate scores, and learned
scores. Basic scores are derived directly from the vector space and
include Hamming distance, inner product, cosine angle, Minkowski
distance, and Mahalanobis distance. For certain workloads involv-
ing multiple query or feature vectors per entity, aggregate scores
such as mean, weighted sum, and others [
79
] combine multiple
scores into a single scalar score that can be more easily compared.
598
Vector Database Management Techniques and Systems SIGMOD-Companion ’24, June 9–15, 2024, Santiago, AA, Chile
It may also be possible to improve query results by learning a suit-
able score directly over the vector space. This is the goal of metric
learning, and several techniques have been proposed [21, 60, 91].
(2) Score Selection. Score selection aims to select the most appro-
priate score for a particular application. While many scores are
known, automatic score selection remains challenging. We mention
one attempt to dynamically adjust the score based on the query
[
82
]. Score selection is also related to query semantics, as certain
query entities such as text strings may still be ambiguous and need
to be resolved before a suitable score can be selected [
75
]. Finally,
the curse of dimensionality limits the usefulness of certain distance-
based scores, requiring other scores to compensate [22, 30, 61].
Query Types and Basic Operators. Data manipulation queries
aim to alter the vector collection. As each vector is derived from an
embedding model, it is possible to integrate the model within the
VDBMS. A VDBMS also must handle vector search queries. Basic
search queries include
𝑘
-nearest neighbor (
𝑘
-NN) and approximate
nearest neighbor (ANN) queries, and query variants include predi-
cated, batched, and multi-vector queries. To answer these queries,
a VDBMS compares the similarity between the query vector and a
number of candidate vectors using similarity projection. The quality
of a result set is measured using precision and recall.
(1) Data Manipulation. The embedding model can live inside or out-
side the VDBMS. Under direct manipulation, users directly modify
the feature vectors, and the user is responsible for the embedding
model [7, 90]. Under indirect manipulation, the collection appears
as a collection of entities, not vectors, and users manipulate the
entities [
5
,
10
]. The VDBMS is responsible for the embedding model.
(2) Basic Search Queries. In a
(𝑐, 𝑘)
-search query, the goal is to retrieve
𝑘
vectors that are most similar to the query vector, and where no
retrieved vector has a similarity score that is a factor of
𝑐
worse
than the best non-zero score. In a range query, a similarity threshold
is given, and the goal is to retrieve all vectors with similarity scores
within the threshold. Some particular cases of
(𝑐, 𝑘)
-search queries
have been studied, notably
𝑐 =
0
, 𝑘 >
1 corresponding to the
𝑘
-NN
query and
𝑐 >
0
, 𝑘 >
1 corresponding to the ANN query. These
queries have been individually studied for many decades, leading
to a variety of techniques and theoretical results [24, 48, 70].
(3) Query Variants. Most VDBMSs support predicated or “hybrid”
queries, and some also support batched and multi-vector queries
for applications such as e-commerce, facial recognition, and text
retrieval [
11
,
79
,
84
]. In a hybrid query, vectors in the collection
are associated to structured attributes regarding the represented
entity, and each vector in the search result set must also satisfy
boolean predicates over the corresponding attributes [
84
]. For
batched queries, a number of search queries are given at once,
and the VDBMS must answer all the queries in the batch. Several
techniques have been proposed to exploit commonalities between
the queries in order to speed up processing the batch [
50
,
79
]. Fi-
nally in a multi-vector query, multiple feature vectors are used to
represent either the query, each entity, or both, and these can be
supported via aggregate scores [
79
]. Multi-vector queries support
several additional sub-variants.
(4) Basic Operators. Similarity projection can be used to answer
vector search queries by projecting each vector in the collection
onto its similarity score.
Query Interfaces. Some VDBMSs aim to support only a small num-
ber of query types and simple APIs are sucient. Other VDBMSs
aim to support a wide range of query types and may rely on SQL
extensions.
2.2 Indexing
An index can be used to speed up search queries, but vectors cannot
be indexed like structured attributes as they lack a natural sort or-
der and categories that are used in typical attribute indexes such as
B-tree. As a result, vector indexes rely on techniques including ran-
domization, learned partitioning, and navigable partitioning in order
to partition the collection so that it can be more easily explored.
To address the large size of vectors, disk-resident indexes have also
been proposed, in addition to techniques based on a compression
technique called quantization. A single index may combine several
of these techniques, but the performance of an index also depends
on its structure that can be table-based, tree-based, or graph-based.
In this section, we describe several vector indexes that are used in
existing VDBMSs, starting from table-based indexes.
Table-Based Indexes. A table-based index partitions the vector
collection into buckets, and each bucket can be retrieved by looking
up a key like the rows in a hash table. In general, table-based indexes
are easy to maintain but search performance may be worse than
other indexes at same recall if buckets are very large. Large buckets
can improve recall but are harder to scan while small buckets may
suer from low recall but are easier to scan. Existing techniques,
including lo cality sensitive hashing (LSH) and learning to hash (L2H),
tend to rely on randomization and learned partitioning to improve
performance at high recall. Furthermore, quantization is a compres-
sion technique that relies mostly on learning compression codes in
order to reduce storage costs.
(1) Locality Sensitive Hashing (LSH). Locality sensitive hashing relies
on random hash functions to bucket vectors. The basic idea is to
hash each vector into each of
𝐿
tables, with each hash function
a concatenation of
𝐾
number of hash functions that belong to a
“hash family”. To answer a query, the query vector is hashed to
each of the tables, and collisions are kept as candidates. The hash
family, along with the tunable parameters
𝐿
and
𝐾
, can be designed
to give error guarantees for ANN. Many hash families are known
with varying performance and accuracy characteristics, including
random hyperplanes in E
2
LSH [
35
], binary projections in
IndexLSH
[1], and overlapping spheres in FALCONN [23, 25].
(2) Learning to Hash (L2H). Learning to hash aims to use machine
learning techniques to directly learn a hash function that can bucket
similar vectors together. One technique is
𝑘
-means clustering in
SPANN, where each vector is bucketed along with other members
of the same cluster [
32
]. The SPANN index also introduces several
techniques for disk-resident collections such as overlapping buckets
to reduce I/O retrievals. Other techniques include spectral hashing
[
85
] and techniques based on neural networks [
71
]. While these
techniques may produce high quality partitionings, they are data
dependent and cannot easily handle out-of-distribution updates. A
survey of techniques can be found in [81].
599
of 8
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。


相关文档
评论