




SIGMOD2024_PolarDB-MP- A Multi-Primary Cloud-Native Database via Disaggregated Shared Memory_阿里云.pdf
免费下载

PolarDB-MP: A Multi-Primar y Cloud-Native Database via
Disaggregated Shared Memory
Xinjun Yang
∗
xinjun.y@alibaba-inc.com
Alibaba Group
Yingqiang Zhang
∗
yingqiang.zyq@alibaba-inc.com
Alibaba Group
Hao Chen
†
ch341982@alibaba-inc.com
Alibaba Group
Feifei Li
lifeifei@alibaba-inc.com
Alibaba Group
Bo Wang
xiangluo.wb@alibaba-inc.com
Alibaba Group
Jing Fang
hangfeng.fj@alibaba-inc.com
Alibaba Group
Chuan Sun
hualuo.sc@alibaba-inc.com
Alibaba Group
Yuhui Wang
yuhui.wyh@alibaba-inc.com
Alibaba Group
ABSTRACT
Primary-secondary databases often have limited write throughput
as they rely on a single primary node. To improve this, some sys-
tems use a shared-nothing architecture for scalable multi-primary
clusters. However, these face performance issues due to distributed
transaction overheads. Recently, shared-storage-based multi-primary
cloud-native databases have emerged to avoid these issues, but they
still struggle with performance in high-conict scenarios, often due
to expensive conict resolution and inecient data fusion.
This paper proposes PolarDB-MP, an innovative multi-primary
cloud-native database that leverages both disaggregated shared
memory and storage. In PolarDB-MP, each node has equal access
to all data, enabling transactions to be processed on individual
nodes without the need for distributed transactions. At the core of
PolarDB-MP is the Polar Multi-Primary Fusion Server (PMFS), built
on disaggregated shared memory. PMFS plays a critical role in facil-
itating global transaction coordination and enhancing buer fusion,
seamlessly integrated with RDMA for minimal latency. Its three
main functionalities include Transaction Fusion for transaction
ordering and visibility, Buer Fusion providing a distributed shared
buer, and Lock Fusion for cross-node concurrency control. More-
over, PolarDB-MP introduces an LLSN design, establishing a partial
order for write-ahead logs generated across dierent nodes, accom-
panied by a tailored recovery policy. Our evaluations of PolarDB-
MP demonstrate its superior performance when compared to the
state-of-the-art solutions. Notably, PolarDB-MP is already in pro-
duction and undergoing commercial trials at Alibaba Cloud. To
*Both authors contributed equally to this work.
†
Hao Chen is the corresponding author.
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for prot or commercial advantage and that copies bear this notice and the full citation
on the rst page. Copyrights for components of this work owned by others than the
author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or
republish, to post on servers or to redistribute to lists, requires prior specic permission
and/or a fee. Request permissions from permissions@acm.org.
SIGMOD-Companion ’24, June 9–15, 2024, Santiago, AA, Chile
© 2024 Copyright held by the owner/author(s). Publication rights licensed to ACM.
ACM ISBN 979-8-4007-0422-2/24/06.. . $15.00
https://doi.org/10.1145/3626246.3653377
our knowledge, PolarDB-MP is the rst multi-primary cloud-native
database that utilizes disaggregated shared memory and shared
storage for transaction coordination and buer fusion.
CCS CONCEPTS
• Information systems → Relational database model.
KEYWORDS
cloud-native database, multi-primary database, disaggregated shared
memory
ACM Reference Format:
Xinjun Yang
∗
, Yingqiang Zhang
∗
, Hao Chen
†
, Feifei Li, Bo Wang, Jing Fang,
Chuan Sun, and Yuhui Wang. 2024. PolarDB-MP: A Multi-Primary Cloud-
Native Database via Disaggregated Shared Memory . In Companion of the
2024 International Conference on Management of Data (SIGMOD-Companion
’24), June 9–15, 2024, Santiago, AA, Chile. ACM, New York, NY, USA, 14 pages.
https://doi.org/10.1145/3626246.3653377
1 INTRODUCTION
Many cloud-native databases (such as AWS Aurora [
49
], Azure
Hyperscale [
14
,
26
], Azure Socrates [
1
] and Alibaba PolarDB [
27
])
have adopted a primary-secondary architecture based on a disag-
gregated shared storage architecture, typically consisting of one
primary node and one or more secondary nodes. However, this
primary-secondary model faces a signicant bottleneck in write-
heavy workloads due to the usage of a single primary node. Addi-
tionally, in scenarios where the primary node fails or shuts down
for upgrade, one of the secondary nodes will be promoted to the
primary role. This transition, while necessary, leads to a brief period
of downtime during the failover process. Consequently, there is
a growing demand for multi-primary cloud-native databases that
can provide enhanced scalability for write-intensive operations
(especially for highly concurrent workloads) as well as improved
high availability with seamless failover capability.
The two most popular multi-primary architectures are shared-
nothing and shared-storage. In the shared-nothing architecture
(e.g., Spanner[
11
], DynamoDB [
15
], CockroachDB [
15
], PolarDB-
X [
6
], Aurora Limitless [
2
], TiDB [
19
] and OceanBase [
55
], etc),
295
SIGMOD-Companion ’24, June 9–15, 2024, Santiago, AA, Chile Xinjun Yang et al.
the whole database is partitioned. Each node is independent and
accesses data exclusively within its designated partition. When a
transaction spans multiple partitions, it must require cross-partition
distributed transaction mechanisms, such as the two-phase commit
policy, which typically induces signicant extra overhead [
57
,
61
].
The shared-storage architecture is essentially the opposite, where
all data is accessible from all cluster nodes, such as IBM pureScale [
20
],
Oracle RAC [
9
], AWS Aurora Multi-Master (Aurora-MM) [
3
] and
Huawei Taurus-MM [
16
]. IBM pureScale and Oracle RAC are the
two traditional database products based on shared-storage archi-
tecture. They rely on expensive distributed lock management and
high network overhead. They are usually deployed in their dedi-
cated machines and are too rigid for a dynamic cloud environment.
Consequently, they usually have a much higher total cost of owner-
ship (TCO) than modern cloud-native databases. Aurora-MM and
Taurus-MM are the recently proposed products for a multi-primary
cloud-native database. Aurora-MM utilizes optimistic concurrent
control for write conict, thus inducing a substantial abortion rate
when conicts occur. In some scenarios, its four-node cluster’s
throughput is even lower than that of a single node [
16
]. On the
contrary, Taurus-MM adopts the pessimistic concurrent control
but it relies on page stores and log replays for cache coherence.
As such, it suers from the high overhead of concurrent control
and data synchronization. The eight-node cluster only improves
the throughput by 1.8
×
compared to the single-node version in the
read-write workload with 50% shared data.
To address these challenges, this paper proposes PolarDB-MP,
a multi-primary cloud-native database via disaggregated shared
memory (and with a shared storage). PolarDB-MP inherits the disag-
gregated shared storage model from PolarDB, allowing all primary
nodes equal access to the storage. This enables a transaction to
be processed in a node without resorting to a distributed transac-
tion. In contrast to optimistic concurrency control, PolarDB-MP em-
ploys pessimistic concurrency control to mitigate transaction aborts
caused by write conicts. Dierent from other cloud databases that
rely on log replay and page servers for data coherence between
nodes, PolarDB-MP uses disaggregated shared memory for e-
cient cache and data coherence. With the growing availability of
RDMA networks in cloud vendors’ data centers [
54
], PolarDB-MP
is intricately co-designed with RDMA to enhance its performance.
The core component of PolarDB-MP is Polar Multi-Primary Fu-
sion Server (PMFS), which is built on disaggregated shared memory.
PMFS comprises Transaction Fusion, Buer Fusion and Lock Fusion.
Transaction Fusion facilitates transaction visibility and ordering
across multiple nodes. It utilizes a Timestamp Oracle (TSO) for
ordering and allocates shared memory on each node to store lo-
cal transaction data that are accessible remotely by other nodes.
This decentralized transaction management approach via shared
memory ensures low latency and high performance in global trans-
action processing. Buer Fusion implements a distributed buer
pool (DBP), also based on disaggregated shared memory and acces-
sible by all nodes. Nodes can both push modied data to and retrieve
data from the DBP remotely. This setup allows swift propagation
of changes from one node to others, ensuring cache coherency
and rapid data access. Lock Fusion eciently manages both page-
level and row-level locking schemes, thus enabling concurrent data
page access across dierent nodes while ensuring physical data
consistency and maintaining transactional consistency.
PolarDB-MP also adeptly manages write-ahead logs across mul-
tiple nodes, using a logical log sequence number (LLSN) to establish
a partial order for logs from dierent nodes. LLSN ensures that all
logs associated with a page are maintained in the same order as they
were generated, thereby preserving data consistency and simplify-
ing recovery processes. On the other hand, PolarDB-MP designs
a new recovery policy based on the LLSN framework, eectively
managing crash recovery scenarios.
Additionally, PolarDB-MP’s message passing and RPC operations
are enhanced by a highly optimized RDMA library, boosting overall
eciency. These advanced designs position PolarDB-MP as a robust,
ecient solution for multi-primary cloud-native databases.
We summarize our main contributions as follows:
•
We propose a multi-primary cloud-native relational database via
disaggregated shared memory over shared storage (the rst of
its kind), delivering high performance and scalability.
•
We leverage the RDMA-based disaggregated shared memory to
design and implement Polar Multi-Primary Fusion Server (PMFS)
that achieves global buer pool management, global page/row
locking protocol, and global transaction coordination.
•
We propose an LLSN design to oer a partial order for write-
ahead logs generated across dierent nodes, accompanied by a
tailored recovery policy.
•
We thoroughly evaluate PolarDB-MP with dierent workloads
and compare it with dierent systems. It shows high performance,
scalability, and availability.
This paper is structured as follows. First, we present the back-
ground and motivation in Section 2. Then we provide PolarDB-MP’s
overview and detailed design in Section 3 and Section 4. Next, we
evaluate PolarDB-MP in Section 5 and review the related works in
Section 6. Finally, we conclude the paper in Section 7.
2 BACKGROUND AND MOTIVATION
2.1 Single-primary cloud-native database
Nowadays, there are many cloud-native databases based on the
primary-secondary architecture, such as Aurora [
49
], Hyperscale [
14
,
26
], Socrates [
1
] and PolarDB [
27
]. Figure 1 depicts the typical ar-
chitecture of a primary-secondary cloud-native database. It usually
comprises a primary node for processing both read and write re-
quests and one or more secondary nodes dedicated to handling
read requests. Each node is a complete database instance, equipped
with standard components. However, a distinctive feature of these
databases, as opposed to traditional monolithic databases, is the
usage of disaggregated shared storage. This shared storage ensures
fault tolerance and consistency, and uniquely, adding more sec-
ondary nodes does not necessitate additional storage. This contrasts
with conventional primary/secondary database clusters, where each
node maintains its own storage.
While the primary-secondary-based databases oer certain ben-
ets, they face signicant challenges under write-heavy workloads.
Scaling out to improve performance is not an option in such ar-
chitecture, and scaling up is limited by the available resources on
the physical machine. Cloud providers typically maximize the use
of physical resources, but since these resources are shared across
296
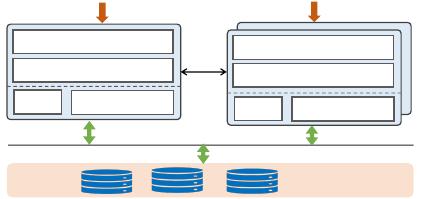
PolarDB-MP: A Multi-Primary Cloud-Native Database via Disaggregated Shared Memory SIGMOD-Companion ’24, June 9–15, 2024, Santiago, AA, Chile
Primary node
CPU
Memory
Buffer pool
SQL/TRX
CPU
Memory
Buffer pool
SQL/TRX
Secondary nodes
Shared cloud storage
Network
write /re ad
read
Figure 1: The architecture of a typical primary-secondary-
based cloud-native database.
many instances, there’s often little room for scaling up a specic in-
stance on the same machine (e.g., adding CPU/memory resources).
Furthermore, migrating to a less crowded machine can result in
signicant downtime and still faces the limitations of a single ma-
chine’s capacity. Another critical challenge in a single-primary
cluster is the issue of failover. If the primary node crashes, it takes
time for a secondary node to assume its role, leading to brief down-
time. Therefore, to achieve high scalability and availability, the
multi-primary database is increasingly becoming a necessity.
2.2 Shared-nothing architecture
The shared-nothing architecture [
43
] is a prevalent model for scal-
ing out, enjoying widespread use in both distributed computing [
52
,
56
] and distributed databases [
6
,
19
,
25
,
45
]. In this architecture,
each request is processed independently by a single node (proces-
sor/memory/storage unit) within a cluster. The primary aim is to
eliminate contention between nodes, as well as to remove single
points of failure, thus allowing the system to continue function-
ing despite individual node failures. This also permits upgrades of
individual nodes without necessitating a system-wide shutdown.
In databases based on shared-nothing architecture, it typically
partitions data across several nodes, with each node having ex-
clusive access (both read and write) to the data in its partition.
This architecture oers robust scalability when application traf-
c is eectively partitioned. However, if a transaction spans more
than one partition, it requires distributed transaction processing
to maintain the transaction’s ACID properties. Managing ecient
synchronization among nodes to ensure these properties while
maintaining performance is challenging [
57
,
61
], which hinders
scalability [
13
,
21
,
40
,
44
,
47
]. Various techniques, like locality-aware
partitioning [
13
,
35
,
38
,
58
], speculative execution [
36
], consistency
levels [
23
] and the relaxation of durability guarantees [
24
], have
been proposed to mitigate this issue. However, these solutions often
lack transparency and require users to understand their intricacies
and carefully design their databases. Additionally, when the system
needs to scale in or out, data may need to be repartitioned, a pro-
cess often fraught with heavy, time-consuming data movements [
6
].
Overall, while shared-nothing architecture oers signicant ben-
ets for scalability, these advantages come with their own set of
challenges and complexities.
2.3 Shared-storage architecture
The shared-storage architecture represents a stark contrast to the
shared-nothing model, as it allows each node within the cluster to
read and write any record in the entire database. In such a setup, to
facilitate concurrent transaction execution across dierent nodes,
global coordination of transaction execution is necessary. This
typically involves mechanisms like a global lock manager and a
centralized Timestamp Oracle (TSO). Conventional shared-storage-
based databases such as IBM pureScale [
20
] and Oracle RAC [
9
]
embody this architecture. However, detailed descriptions of their
implementation are sparse. These systems often struggle with the
complexities and costs associated with distributed lock management
and high network overhead. Additionally, they were designed prior
to the advent of cloud computing and are typically deployed on
their own dedicated hardware, making them unsuited for modern
cloud environments. Their rigidity in this context often results in a
signicantly higher Total Cost of Ownership (TCO) compared to
modern cloud-native databases.
Aurora-MM [
3
] and Taurus-MM [
16
] are the two recent propos-
als to bring the multi-primary database to the cloud. Aurora-MM
adopts the shared storage architecture and employs optimistic con-
currency control to manage write conicts. This approach can lead
to high performance when there is no contention between nodes.
However, a signicant downside is that, in scenarios with conicts,
such as when dierent nodes attempt to modify the same data page
simultaneously, it results in a high rate of transaction aborts. In
such cases, it reports such write conicts to the application as a
deadlock error, requiring applications to detect these errors, roll
back transactions, and retry them later. This not only diminishes
throughput and consumes additional resources, but also presents
a challenge as many applications are not adept at handling high
abort rates. According to Taurus-MM ’s research [
16
], Aurora-MM’s
four-node cluster only shows a throughput improvement of less
than 50% compared to a single node under the SysBench read-write
workload with a mere 10% data sharing between nodes (the detailed
conguration is presented in Section 5). Moreover, in a SysBench
write-only workload with 10% shared data, the four-node cluster’s
throughput is even lower than that of a single node.
To improve performance, Taurus-MM utilizes the pessimistic
concurrency control. It introduces a Vector-scalar clocks algorithm
for transaction ordering and a hybrid page-row locking mechanism
to enable concurrent transaction executions and data access on dif-
ferent nodes. However, this approach encounters issues with buer
coherency. When a node requests a page that has been modied
by another node, it must request both the page and corresponding
logs from the page/log stores, and then apply the logs to obtain the
latest version of the page. This process typically involves storage
I/Os, which can impact performance, and the log application also
consumes extra CPU cycles. In their evaluations [
16
], the through-
put of Taurus-MM ’s eight-node cluster is approximately 1.8
×
that
of a single node under the SysBench write-only workload with 30%
shared data, illustrating the trade-os and challenges in optimizing
multi-primary cloud databases.
2.4 MVCC and transaction isolation
Multi-version concurrency control (MVCC) is currently the most
popular transaction management scheme in modern database [
10
,
32
,
53
] and it is used in almost every major relational database.
MVCC diers from traditional methods by not overwriting data
with updates; instead, it creates new versions of the data item. This
297
of 14
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。

评论