




SIGMOD2024_Flux- Decoupled Auto-Scaling for Heterogeneous Query Workload in Alibaba AnalyticDB_阿里云.pdf
免费下载

Flux: Decoupled Auto-Scaling for Heterogeneous ery
Workload in Alibaba AnalyticDB
Wei Li
∗
Alibaba Group
Hangzhou, China
liwei.li@alibaba-inc.com
Jiachi Zhang
∗
Alibaba Group
Hangzhou, China
zhangjiachi.zjc@alibaba-
inc.com
Ye Yin
Alibaba Group
Hangzhou, China
yinye.yin@alibaba-
inc.com
Yan Li
Alibaba Group
Hangzhou, China
chenzhou.ly@alibaba-
inc.com
Zhanyang Zhu
Alibaba Group
Hangzhou, China
zhuzhanyang.zzy@alibaba-
inc.com
Wenchao Zhou
Alibaba Group
Hangzhou, China
zwc231487@alibaba-
inc.com
Liang Lin
Alibaba Group
Hangzhou, China
yibo.ll@alibaba-inc.com
Feifei Li
Alibaba Group
Hangzhou, China
lifeifei@alibaba-inc.com
ABSTRACT
Modern cloud data warehouses are integral to processing hetero-
geneous query workloads, which range from quick online trans-
actions to intensive ad-hoc queries and extract, transform, load
(ETL) processes. The synchronization of heterogeneous workloads,
particularly the blend of short and long-running queries, often
degrades performance due to intricate concurrency controls and
cooperative multi-tasking execution models. Additionally, the auto-
scaling mechanisms for mixed workloads can lead to spikes in
demand and underutilized resources, impacting both performance
and cost-eciency. This paper introduces the Flux, a cloud-native
workload auto-scaling platform designed for Alibaba AnalyticDB,
which implements a pioneering decoupled auto-scaling architecture.
By separating the scaling mechanisms for short and long-running
queries, Flux not only resolves performance bottlenecks but also
harnesses the elasticity of serverless container instances for on-
demand resource provisioning. Our extensive evaluations demon-
strate Flux’s superiority over traditional scaling methods, with up
to a 75% reduction in query response time (RT), a 19.0% increase in
resource utilization ratio, and a 77.8% decrease in cost overhead.
CCS CONCEPTS
• Information systems
→
Data warehouses; Autonomous
database administration.
KEYWORDS
cloud data warehouse, auto-scaling, heterogeneous workloads
∗
Both authors contributed equally to this research.
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for prot or commercial advantage and that copies bear this notice and the full citation
on the rst page. Copyrights for components of this work owned by others than the
author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or
republish, to post on servers or to redistribute to lists, requires prior specic permission
and/or a fee. Request permissions from permissions@acm.org.
SIGMOD-Companion ’24, June 9–15, 2024, Santiago, AA, Chile
© 2024 Copyright held by the owner/author(s). Publication rights licensed to ACM.
ACM ISBN 979-8-4007-0422-2/24/06... $15.00
https://doi.org/10.1145/3626246.3653381
ACM Reference Format:
Wei Li, Jiachi Zhang, Ye Yin, Yan Li, Zhanyang Zhu, Wenchao Zhou, Liang
Lin, and Feifei Li. 2024. Flux: Decoupled Auto-Scaling for Heterogeneous
Query Workload in Alibaba AnalyticDB. In Companion of the 2024 In-
ternational Conference on Management of Data (SIGMOD-Companion ’24),
June 9–15, 2024, Santiago, AA, Chile. ACM, New York, NY, USA, 14 pages.
https://doi.org/10.1145/3626246.3653381
1 INTRODUCTION
In the era of cloud computing, an increasing number of cloud ven-
dors oer data warehouse services, such as Amazon Redshift [
1
],
Snowake [
15
], and Alibaba AnalyticDB [
7
,
40
]. These services
must adeptly handle mixed heterogeneous query workloads, rang-
ing from swift, online transactions to extensive ad-hoc analyses
and complex extract, transform, load (ETL) processes.
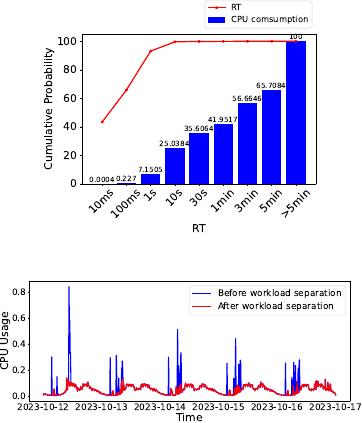
Statistical analysis from an instance of Alibaba AnalyticDB [
6
],
illustrated in Figure 1, shows a distribution of query workload types
along with their associated CPU consumption (i.e., CPU time). This
analysis reveals that response times (RT) can span from a mere 10
milliseconds to over 5 minutes. Notably, queries with longer dura-
tions tend to be more complex, demanding a substantially greater
amount of computational resources. For instance, queries exceeding
5 minutes in RT are observed to consume greater CPU resources
than those of the briefest queries by ve orders of magnitude.
The diversity of query workloads in cloud data warehouses
causes considerable uctuations in resource utilization over time.
As depicted in Figure 2, the real-time CPU usage (blue line) of an
AnalyticDB instance uctuates signicantly over a span of ve days.
Notably, the CPU usage can surge to levels up to 19.54 times higher
than periods of relative inactivity. This variability is compounded
by the unpredictability of complex ad-hoc queries, which can oc-
cur at any time and without warning. To address these challenges,
prior research have primarily centered on workload management
systems and dynamic auto-scaling solutions.
Figure 3 (a) depicts a basic approach where all queries are en-
queued within a static cluster. Such an architecture does not dis-
tinguish between the diverse resource demands of short and long-
running queries. Consequently, long-running queries may deplete
computational resources, leading to increased response times (RTs)
255
SIGMOD-Companion ’24, June 9–15, 2024, Santiago, AA, Chile Wei Li et al.
Figure 1: Query workloads from an AnalyticDB instance.
Figure 2: CPU usage over a ve-day period.
for short-running queries. A more advanced strategy, termed work-
load isolation, is showcased in Figure 3 (b). Systems like IBM DB2 [
13
],
Microsoft SQL Server [25], and Teradata [38] adopt this approach,
enabling the segregation of queries into multiple queues with des-
ignated resource caps and concurrency limits. Approaches such as
Auto-WLM [
33
] have introduced auto-scaling into cloud data ware-
houses. As demonstrated in Figure 3 (c), auto-scaling dynamically
adjusts the size of a multi-cluster group, such as Snowake’s multi-
cluster warehouses [
10
,
14
,
24
] and Redshift’s concurrency scaling
clusters [
33
] in response to workload uctuations. Furthermore, to
facilitate ecient resource provisioning across multiple database
instances, cloud providers often manage a shared resource pool,
such as Twine [37] and Eigen [19], serving as prime examples.
Despite the signicant evolution of workload management and
auto-scaling in cloud data warehouses, to the best of our knowledge,
no existing solutions have addressed all the challenges below:
First, the execution of mixed heterogeneous workloads leads to
poor performance of long-running queries due to:
C1
Cooperative multi-tasking query execution. The preva-
lent cooperative multi-tasking model [
18
,
35
] in cloud data
warehouses, which limits query tasks to one-second thread
execution, boosts short-running query performance at the
expense of long-running query eciency.
C2
Complex concurrency control. Given the skewed distri-
bution of query types (Figure 1), workload managers that
prioritize short-running queries often diminish the perfor-
mance of long-running ones.
And the auto-scaling of mixed heterogeneous workloads on multi-
cluster groups is facing the following challenge:
C3
Stranded resources caused by workload spikes. Proac-
tive auto-scaling depends on precise time series forecasting
to anticipate workload demands accurately. Existing method-
ologies like Autopilot [
30
], P-Store [
36
], and Eigen [
19
] of-
ten fall short in predicting workload spikes, such as those
caused by ad-hoc queries. To solve this problem, these sys-
tems typically implement a buer strategy, allocating addi-
tional resource margins. However, the cost of the margins is
non-negligible (i.e., stranded resources).
To address the challenges, we present Flux, a cloud-native work-
load auto-scaling platform for Alibaba AnalyticDB. As shown in
Figure 3 (d), Flux implements a pioneering de coupled auto-scaling
architecture which addresses the challenges associated with mixed
execution workloads (C1 and C2) and resource ineciency dur-
ing spikes (C3). Flux separates the management of short-running
and long-running queries to enhance overall system performance.
For short-running queries, Flux adeptly adjusts the multi-cluster
group’s size by either scaling in/out, relying on proactive work-
load forecasting algorithms. Long-running queries, characterized
by their substantial resource demands and high elasticity toler-
ance, are managed distinctly. Flux dynamically allocates resources
by constructing and scaling clusters up or down as required, and
then promptly releases these resources once the query execution is
complete. Figure 2 illustrates that, following the separation of long-
running queries, the CPU usage associated with short-running
queries (red line) exhibits greater seasonality and predictability,
making it more amenable to accurate forecasting.
To fulll the objectives, we rst created a query dispatcher
equipped with a SQL template classier and a machine learning
(ML) classier to identify short-running and long-running queries.
Short-running queries are sent to a multi-cluster group for prompt
processing, while long-running queries are assigned to dedicated
per-job clusters. Second, we engineered a multi-cluster auto-scaler
for short-running queries and a job resource scheduler for long-
running queries that independently scale/schedule resources.
In addition, to reduce stranded resources in the shared resource
pool (C3), we leverage the emerging serverless container instance
services, such as Alibaba ECI [
8
] and AWS Fargate [
2
]. These ser-
vices enable rapid resource provisioning and oer a serverless pric-
ing model, thus facilitating the creation of an on-demand resource
pool. While this on-demand pool provides exibility, it comes with
a higher per-hour cost. To address this, we have constructed a cost
model that operates across both the shared and on-demand resource
pools. Utilizing this model, we devised innovative auto-scaling al-
gorithms aimed at minimizing the overall resource cost.
Our contributions include the following:
•
Architecture: We introduce the architecture of Flux, a pi-
oneering decoupled auto-scaling architecture. This novel
architecture addresses challenges C1-C3 by enhancing query
performance and the resource utilization ratio.
•
Resource Cost Model: We develop a cost model that inte-
grates shared and on-demand resource pools, utilizing Al-
ibaba ECI services. Our model aims to minimize resource
costs for cloud vendors, ensuring economic operation with-
out sacricing service quality.
•
Empirical Evaluation: We evaluate Flux using both public
benchmarks and production clusters with real-world work-
loads. Our results demonstrate substantial improvements
over existing methods: query response time (RT) is reduced
by up to 75%, resource utilization ratio is increased by 19.0%,
and the cost of stranded resources is cut by 77.8%.
256

Flux: Decoupled Auto-Scaling for Heterogeneous ery Workload in Alibaba AnalyticDB SIGMOD-Companion ’24, June 9–15, 2024, Santiago, AA, Chile
Cluster
(a) (b)
(c)
Scale
in/out
Cluster
Cluster
Cluster
(d)
Scale
in/out
Cluster
Cluster
Cluster
Shared resource pool
Shared resource pool
On-demand resource pool
Waiting… Waiting…
Figure 3: Four workload management designs on cloud data warehouses.
Coordination layer
Execution layer
Storage layer
Scale
in/out
ClusterCluster
Workload manager
Optimizer
Scheduler
Analyzer
& Parser
Executor
Auto-scaler
Thread pool
Task 0.0
Stage 0
TaskInstance 0.0.1
Task 0.0
TaskInstance 0.0.2
TaskInstance 0.0.3
TaskInstance 0.0.4
Task 0.1
TaskInstance queue
Elapsed time
Figure 4: Architecture of AnalyticDB.
The remainder of this paper is organized as follows. Section 2
introduces background knowledge to further explain the challenges
C1-C3. Section 3 presents the architecture and key components of
Flux. Section 4 and 5 present the query dispatcher and auto-scaling
algorithms of Flux. The evaluation results are shown in Section 6.
We discuss the future research in Section 7, the related works in
Section 8, then conclude in Section 9.
2 BACKGROUND AND MOTIVATION
In this section, we rst present the background knowledge of Ana-
lyticDB, including its query execution engine in Section 2.1. Next,
we discuss workload management in Section 2.2, and auto-scaling
in Section 2.3.
2.1 AnalyticDB
AnalyticDB [
40
] is a cloud-native data warehouse developed by Al-
ibaba Cloud. It adopts a massively-parallel and elastically-scalable
query execution engine, which decouples computing from stor-
age [
20
]. To explain, we present a simplied architecture of Analyt-
icDB in Figure 4. The left part of this gure illustrates the overall
three-tiered architecture of AnalyticDB. The rst layer consists
of coordinator nodes that are responsible for admitting, parsing,
optimizing, and scheduling the queries. The second layer consists
of symmetric executors deployed on executor nodes. In practice, we
build a multi-cluster group that consists of Kubernetes [
16
] clusters
and pods (yellow rounds in Figure 4) as the executor nodes. The last
layer consists of storage nodes from distributed storage systems.
AnalyticDB controls the entire lifecycle of query execution. The
process is depicted in Figure 4. Briey speaking, a raw SQL query
is converted to a physical plan where the nodes that have the same
distributed property (i.e., processing the data from the same data
partition) forms a stage. The scheduler is responsible for scheduling
the stages to the executors. Notably, AnalyticDB supports two
levels of parallelism. At the inter-node level, as shown in Figure 4, a
stage is divided into tasks that run on dierent executors in parallel
(e.g., task 0.0 and task 0.1 of stage 0 are assigned to the executor in
Figure 4). At the intra-node level, a task is divided into task instances.
AnalyticDB adopts a cooperative multi-tasking model [
35
] to run
the task instances in parallel. Specically, the task instances from
multiple queries are enqueued and then assigned to threads from a
thread pool.
While AnalyticDB’s query execution engine is engineered for
high performance and elasticity, handling a mixture of heteroge-
neous workloads presents a specic challenge:
The cooperative multi-tasking is designed to optimize CPU usage
and improve the performance of short-running queries. This model
typically enforces time slicing, where each task instance is allowed
to run on a thread for a predetermined maximum time unit (e.g.,
one second). Once this time limit is reached, the task instance must
yield the thread and re-enter the queue, regardless of whether it
has completed its execution. This scheduling technique, however,
poses a signicant challenge (C1) for long-running queries. The
issue is exemplied in Figure 4 where the orange and green boxes
in the thread pool represent task instances of short-running queries
and a long-running query. It takes three rounds of execution and
substantial queuing time before the completion of the long-running
query in the task instance queue.
2.2 Workload Management
Workload management [
41
] in database management systems is a
process of monitoring, admission, scheduling and controlling work-
load execution to achieve ecient resource utilization and workload
performance objectives. It has become a well-developed discipline
and has been used by commercial databases, such as IBM DB2
Workload Manager [
13
], Microsoft SQL Server Resource and Query
Governor [
25
], and Teradata Active System Management [
38
]. The
workload managers are responsible for tasks, including (1) work-
load characterization that classies workloads by properties (e.g.,
response time), (2) admission control that decides the concurrency
of dierent workloads, (3) scheduling that decides a particular order
of workload execution, and (4) execution control that dynamically
adjusts the priority or order of workload execution.
Unfortunately, workload management could become complex
when dealing with mixed heterogeneous workloads (C2). As il-
lustrated in Figure 1, long-running queries consume signicantly
more resources than short-running queries. This disparity creates
a tension between optimizing for the quick completion of short-
running queries and the more resource-consuming execution of
long-running queries. Dynamic workload conditions exacerbate
257
of 14
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
墨天轮 运营
最新上传
下载排行榜
1
2
9-数据库人的进阶之路:从PG分区、SQL优化到拥抱AI未来(罗敏).pptx
3
1-PG版本兼容性案例(彭冲).pptx
4
2-TDSQL PG在复杂查询场景中的挑战与实践-opensource.pdf
5
6-PostgreSQL 哈希索引原理浅析(文一).pdf
6
8-基于PG向量和RAG技术的开源知识库问答系统MaxKB.pptx
7
3-AI时代的变革者-面向机器的接口语言(MOQL)_吕海波.pptx
8
4-IvorySQL V4:双解析器架构下的兼容性创新实践.pptx
9
7-拉起PG好伙伴DifySupaOdoo.pdf
10
《云原生安全攻防启示录》李帅臻.pdf

评论