




ClickHouse - Lightning Fast Analytics for Everyone.pdf
5墨值下载

ClickHouse - Lightning Fast Analytics for Everyone
Robert Schulze
ClickHouse Inc.
robert@clickhouse.com
Tom Schreiber
ClickHouse Inc.
tom@clickhouse.com
Ilya Yatsishin
ClickHouse Inc.
iyatsishin@clickhouse.com
Ryadh Dahimene
ClickHouse Inc.
ryadh@clickhouse.com
Alexey Milovidov
ClickHouse Inc.
milovidov@clickhouse.com
ABSTRACT
Over the past several decades, the amount of data being stored
and analyzed has increased exponentially. Businesses across in-
dustries and sectors have begun relying on this data to improve
products, evaluate performance, and make business-critical deci-
sions. However, as data volumes have increasingly become internet-
scale, businesses have needed to manage historical and new data
in a cost-eective and scalable manner, while analyzing it using a
high number of concurrent queries and an expectation of real-time
latencies (e.g. less than one second, depending on the use case).
This paper presents an overview of ClickHouse, a popular open-
source OLAP database designed for high-performance analytics
over petabyte-scale data sets with high ingestion rates. Its storage
layer combines a data format based on traditional log-structured
merge (LSM) trees with novel techniques for continuous trans-
formation (e.g. aggregation, archiving) of historical data in the
background. Queries are written in a convenient SQL dialect and
processed by a state-of-the-art vectorized query execution engine
with optional code compilation. ClickHouse makes aggressive use
of pruning techniques to avoid evaluating irrelevant data in queries.
Other data management systems can be integrated at the table
function, table engine, or database engine level. Real-world bench-
marks demonstrate that ClickHouse is amongst the fastest analyti-
cal databases on the market.
PVLDB Reference Format:
Robert Schulze, Tom Schreiber, Ilya Yatsishin, Ryadh Dahimene,
and Alexey Milovidov. ClickHouse - Lightning Fast Analytics for Everyone.
PVLDB, 17(12): 3731 - 3744, 2024.
doi:10.14778/3685800.3685802
1 INTRODUCTION
This paper describes ClickHouse, a columnar OLAP database de-
signed for high-performance analytical queries on tables with tril-
lions of rows and hundreds of columns. ClickHouse was started
in 2009 as a lter and aggregation operator for web-scale log le
data
1
and was open sourced in 2016. Figure 1 illustrates when major
features described in this paper were introduced to ClickHouse.
This work is licensed under the Creative Commons BY-NC-ND 4.0 International
License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of
this license. For any use beyond those covered by this license, obtain permission by
emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights
licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 17, No. 12 ISSN 2150-8097.
doi:10.14778/3685800.3685802
1
Blog post: clickhou.se/evolution
ClickHouse is designed to address ve key challenges of modern
analytical data management:
1. Huge data sets with high ingestion rates. Many data-
driven applications in industries like web analytics, nance, and
e-commerce are characterized by huge and continuously grow-
ing amounts of data. To handle huge data sets, analytical databases
must not only provide ecient indexing and compression strategies,
but also allow data distribution across multiple nodes (scale-out)
as single servers are limited to several dozen terabytes of storage.
Moreover, recent data is often more relevant for real-time insights
than historical data. As a result, analytical databases must be able
to ingest new data at consistently high rates or in bursts, as well as
continuously "deprioritize" (e.g. aggregate, archive) historical data
without slowing down parallel reporting queries.
2. Many simultaneous queries with an expectation of low
latencies. Queries can generally be categorized as ad-hoc (e.g.
exploratory data analysis) or recurring (e.g. periodic dashboard
queries). The more interactive a use case is, the lower query laten-
cies are expected, leading to challenges in query optimization and
execution. Recurring queries additionally provide an opportunity
to adapt the physical database layout to the workload. As a result,
databases should oer pruning techniques that allow optimizing
frequent queries. Depending on the query priority, databases must
further grant equal or prioritized access to shared system resources
such as CPU, memory, disk and network I/O, even if a large number
of queries run simultaneously.
3. Diverse landscapes of data stores, storage locations, and
formats. To integrate with existing data architectures, modern
analytical databases should exhibit a high degree of openness to
read and write external data in any system, location, or format.
4. A convenient query language with support for perfor-
mance introspection. Real-world usage of OLAP databases poses
additional "soft" requirements. For example, instead of a niche pro-
gramming language, users often prefer to interface with databases
in an expressive SQL dialect with nested data types and a broad
range of regular, aggregation, and window functions. Analytical
databases should also provide sophisticated tooling to introspect
the performance of the system or individual queries.
5. Industry-grade robustness and versatile deployment. As
commodity hardware is unreliable, databases must provide data
replication for robustness against node failures. Also, databases
should run on any hardware, from old laptops to powerful servers.
Finally, to avoid the overhead of garbage collection in JVM-based
programs and enable bare-metal performance (e.g. SIMD), databases
are ideally deployed as native binaries for the target platform.
3731

Figure 1: ClickHouse timeline.
2 ARCHITECTURE
As shown by Figure 2, the ClickHouse engine is split into three main
layers: the query processing layer (described in Section 4), the stor-
age layer (Section 3), and the integration layer (Section 5). Besides
these, an access layer manages user sessions and communication
with applications via dierent protocols. There are orthogonal com-
ponents for threading, caching, role-based access control, backups,
and continuous monitoring. ClickHouse is built in C++ as a single,
statically-linked binary without dependencies.
Query processing follows the traditional paradigm of parsing in-
coming queries, building and optimizing logical and physical query
plans, and execution. ClickHouse uses a vectorized execution model
similar to MonetDB/X100 [
11
], in combination with opportunistic
code compilation [
53
]. Queries can be written in a feature-rich SQL
dialect, PRQL [76], or Kusto’s KQL [50].
The storage layer consists of dierent table engines that encap-
sulate the format and location of table data. Table engines fall into
three categories: The rst category is the MergeTree* family of
table engines which represent the primary persistence format in
ClickHouse. Based on the idea of LSM trees [
60
], tables are split
into horizontal, sorted parts, which are continuously merged by
a background process. Individual MergeTree* table engines dier
in the way the merge combines the rows from its input parts. For
example, rows can be aggregated or replaced, if outdated.
The second category are special-purpose table engines, which
are used to speed up or distribute query execution. This category
includes in-memory key-value table engines called dictionaries. A
dictionary caches the result of a query periodically executed against
an internal or external data source. This signicantly reduces ac-
cess latencies in scenarios, where a degree of data staleness can
be tolerated.
2
Other examples of special-purpose table engines in-
clude a pure in-memory engine used for temporary tables and the
Distributed table engine for transparent data sharding (see below).
The third category of table engines are virtual table engines for
bidirectional data exchange with external systems such as relational
databases (e.g. PostgreSQL, MySQL), publish/subscribe systems (e.g.
Kafka, RabbitMQ [
24
]), or key/value stores (e.g. Redis). Virtual
engines can also interact with data lakes (e.g. Iceberg, DeltaLake,
Hudi [36]) or les in object storage (e.g. AWS S3, Google GCP).
ClickHouse supports sharding and replication of tables across
multiple cluster nodes for scalability and availability. Sharding par-
titions a table into a set of table shards according to a sharding
expression. The individual shards are mutually independent ta-
bles and typically located on dierent nodes. Clients can read and
write shards directly, i.e. treat them as separate tables, or use the
Distributed special table engine, which provides a global view of
2
Blog post: clickhou.se/dictionaries
all table shards. The main purpose of sharding is to process data
sets which exceed the capacity of individual nodes (typically, a few
dozens terabytes of data). Another use of sharding is to distribute
the read-write load for a table over multiple nodes, i.e., load balanc-
ing. Orthogonal to that, a shard can be replicated across multiple
nodes for tolerance against node failures. To that end, each Merge-
Tree* table engine has a corresponding ReplicatedMergeTree* engine
which uses a multi-master coordination scheme based on Raft con-
sensus [
59
] (implemented by Keeper
3
, a drop-in replacement for
Apache Zookeeper written in C++) to guarantee that every shard
has, at all times, a congurable number of replicas. Section 3.6 dis-
cusses the replication mechanism in detail. As an example, Figure 2
shows a table with two shards, each replicated to two nodes.
Finally, the ClickHouse database engine can be operated in on-
premise, cloud, standalone, or in-process modes. In the on-premise
mode, users set up ClickHouse locally as a single server or multi-
node cluster with sharding and/or replication. Clients communi-
cate with the database over the native, MySQL’s, PostgreSQL’s
binary wire protocols, or an HTTP REST API. The cloud mode is
represented by ClickHouse Cloud, a fully managed and autoscal-
ing DBaaS oering. While this paper focuses on the on-premise
mode, we plan to describe the architecture of ClickHouse Cloud in
a follow-up publication. The standalone mode turns ClickHouse
into a command line utility for analyzing and transforming les,
making it a SQL-based alternative to Unix tools like
cat
and
grep
.
4
While this requires no prior conguration, the standalone mode is
restricted to a single server. Recently, an in-process mode called
chDB [
15
] has been developed for interactive data analysis use cases
like Jupyter notebooks [
37
] with Pandas dataframes [
61
]. Inspired
by DuckDB [
67
], chDB embeds ClickHouse as a high-performance
OLAP engine into a host process. Compared to the other modes,
this allows to pass source and result data between the database
engine and the application eciently without copying as they run
in the same address space.
5
3 STORAGE LAYER
This section discusses MergeTree* table engines as ClickHouse’s
native storage format. We describe their on-disk representation and
discuss three data pruning techniques in ClickHouse. Afterwards,
we present merge strategies which continuously transform data
without impacting simultaneous inserts. Finally, we explain how
updates and deletes are implemented, as well as data deduplication,
data replication, and ACID compliance.
3
Blog post: clickhou.se/keeper
4
Blog posts: clickhou.se/local, clickhou.se/local-fastest-tool
5
Blog post: clickhou.se/chdb-rocket-engine
3732
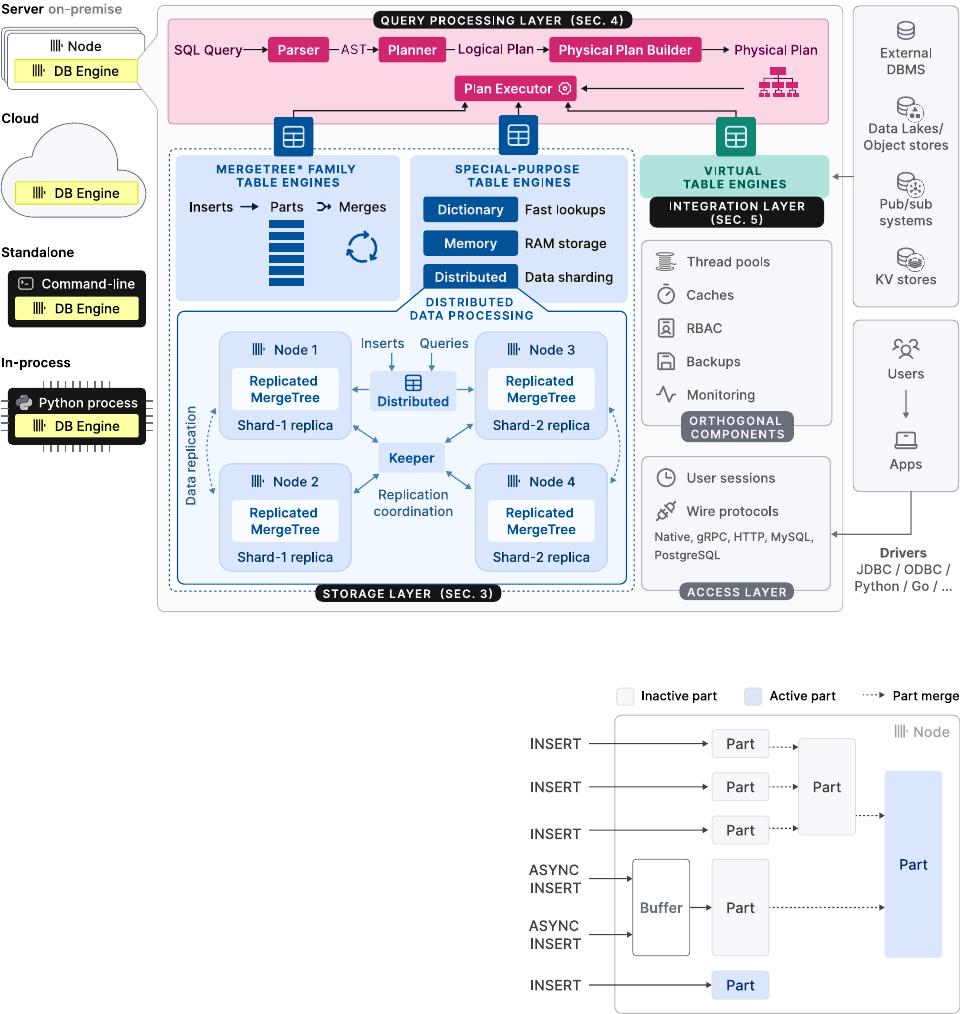
Figure 2: The high-level architecture of the ClickHouse database engine.
3.1 On-Disk Format
Each table in the MergeTree* table engine is organized as a collec-
tion of immutable table parts. A part is created whenever a set of
rows is inserted into the table. Parts are self-contained in the sense
that they include all metadata required to interpret their content
without additional lookups to a central catalog. To keep the number
of parts per table low, a background merge job periodically com-
bines multiple smaller parts into a larger part until a congurable
part size is reached (150 GB by default). Since parts are sorted by
the table’s primary key columns (see Section 3.2), ecient k-way
merge sort [
40
] is used for merging. The source parts are marked
as inactive and eventually deleted as soon as their reference count
drops to zero, i.e. no further queries read from them.
Rows can be inserted in two modes: In synchronous insert mode,
each
INSERT
statement creates a new part and appends it to the
table. To minimize the overhead of merges, database clients are
encouraged to insert tuples in bulk, e.g. 20,000 rows at once. How-
ever, delays caused by client-side batching are often unacceptable
if the data should be analyzed in real-time. For example, observabil-
ity use cases frequently involve thousands of monitoring agents
continuously sending small amounts of event and metrics data.
Such scenarios can utilize the asynchronous insert mode, in which
ClickHouse buers rows from multiple incoming
INSERT
s into the
same table and creates a new part only after the buer size exceeds
a congurable threshold or a timeout expires.
Figure 3: Inserts and merges for MergeTree*-engine tables.
Figure 3 illustrates four synchronous and two asynchronous
inserts into a MergeTree*-engine table. Two merges reduced the
number of active parts from initially ve to two.
Compared to LSM trees [
58
] and their implementation in various
databases [
13
,
26
,
56
], ClickHouse treats all parts as equal instead
of arranging them in a hierarchy. As a result, merges are no longer
limited to parts in the same level. Since this also forgoes the implicit
3733
of 14
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。

下载排行榜
1
2
9-数据库人的进阶之路:从PG分区、SQL优化到拥抱AI未来(罗敏).pptx
3
1-PG版本兼容性案例(彭冲).pptx
4
2-TDSQL PG在复杂查询场景中的挑战与实践-opensource.pdf
5
6-PostgreSQL 哈希索引原理浅析(文一).pdf
6
3-AI时代的变革者-面向机器的接口语言(MOQL)_吕海波.pptx
7
8-基于PG向量和RAG技术的开源知识库问答系统MaxKB.pptx
8
4-IvorySQL V4:双解析器架构下的兼容性创新实践.pptx
9
7-拉起PG好伙伴DifySupaOdoo.pdf
10
《云原生安全攻防启示录》李帅臻.pdf

文档被以下合辑收录
相关文档
评论