




分布式流处理综述.docx
免费下载
分布式流处理综述
随着互联网技术的发展,越来越多的行业领域对数据和数据处理提出了较高的要求,
其高速产生的海量数据的处理需求日渐增多,近几年来更是呈现出爆炸式增长的趋势。很
多领域,这些处理需求已经成为了当务之急。
1. 简介
当前被业界广泛采用的大数据处理架构是 MapReduce,在处理传统大数据时 ,
MapReduce 十分有效,但是它并不适合大数据的高速实时处理。主要原因是因为它是一
个批处理计算模型,并不适合于其他类型的计算。
一般来讲,我们将大数据的批处理模式和流处理模式看成两种不同的模式。虽然都是
面对海量数据的处理,两者之间还是有很多不同点。传统的批处理模式更倾向与重视数据
处理的吞吐量,因此会在处理的时效性上略显不足,而在很多场合下,数据处理的时效性
是非常关键的,对数据处理过程的整体延迟要求非常高,要求很快的得出处理结果并进行
下一步计算,因此流处理模式得到发展。
在批处理模式中,静态数据的中间结果数据被持久化到外部存储介质上,等待节点处
理完毕之后才会发送到下一个节点,这种方法显然会浪费大量的 I/O 时间,从而成为数据
处理实时性的瓶颈。
在流处理模式中,处理的中间结果在写入缓存后直接发送给下一个节点,因此,不仅
拥有更低的处理延迟,还可以应对不断更新的动态数据,不断的进行数据输入的同时,不
断的进行数据处理并且很快的产生结果,因此得到很多需要实时处理的系统的使用。
在分布式数据流处理产生之前,就有很多早期的数据流处理系统出现,这也是流处理
模式最早的起源和应用,尽管采用相似的流处理模式进行数据处理,但是传统的集中式架
构无法适应海量数据处理的需求,而且传统系统普遍面向单一的应用领域,模块之间具有
较高的耦合度,扩展性差,难以适应和发展。
面对这些问题,Hadoop 平台的出现指出了解决方向,并行化和平台式成为主流,分
布式大数据流处理技术成为了理想的解决方案,提出了很多可以高性能低延迟的处理大数
据流的平台,例如 Storm,Spark Streaming,Samza 等。这些平台采用分布式架构,
其数据处理能力可以随着分布式节点的数目增长而增长,可以良好的适应海量数据的处理,
同时实现了平台化,即自身只有基础模块,负责数据传输和任务分配等工作,而逻辑模块
由用户自己编码开发,因此具有很高的扩展性,可以方便的用于实现各类系统。
2. 特性
一个典型的数据处理系统可以有几个分类维度,例如数据形态、依托介质和处理粒度。
传统的 MapReduce 是面向静态数据,依托磁盘的粗粒度处理模式,因此可以有很高的
数据吞吐量,适合用于海量静态数据的处理,但是由于其依托于磁盘,因此获得处理结果
需要相对长的时间,一般形象的称之为离线处理。
和之相对的就是面向动态数据,依托内存的细粒度处理模式,即分布式流处理模式,
数据进行流式的动态输入并且同样的实时产生流式的处理结果,处理延迟低,由于数据是
不断产生输入并处理的,因此理论上只要在高峰期不产生数据堆积,系统不需要很高的吞
吐量,相对的,则对延迟提出了更高的要求,因此要求系统是细粒度的,从而更及时的产
生数据处理结果。
目前世面上存在很多种分布式流处理平台,各有特色,但是其中很大一部分的核心思
想是有很大共同之处的。和传统分布式系统中所应用的 MapReduce 思想相同,分布式
流处理同样是将需要处理的数据流进行切分,然后采用多个节点进行计算,从而实现低延
迟快速处理大量数据的效果。如图所示。
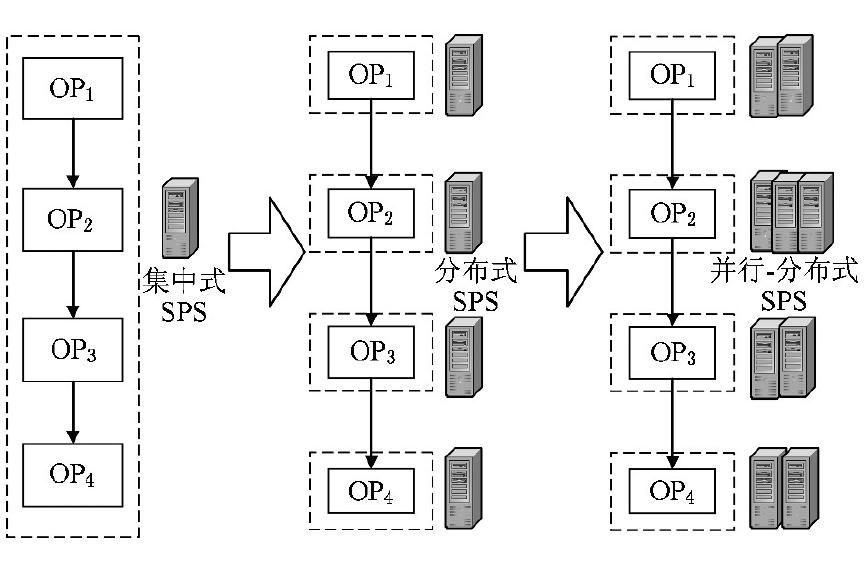
显然,用这种方法去实现一个分布式流处理系统,首要的问题在于如何实现并行化。
不管什么分布式系统,如何实行有效的并行化都是系统处理效率的关键,对此,不同的实
现方案在细节上有很大不同。
3. 面临问题
3.1 数据模型
首先是需要解决的是数据模型的问题,和程序语言中数据结构的概念相似,任何数据
处理系统都需要解决的数据抽象问题,即数据以什么样的形式输入到系统中并在系统中进
行传递。显然,数据建模的好坏直接决定了一个分布式流处理系统的可行性和执行效率。
常见的如,Storm 使用元祖(tuple),Spark Streaming 使用 DStream,而 Samza
使用消息等等。每种数据模型都各有特色,和各自的系统模型互相契合,从而达到良好的
使用效果。
of 11
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。

评论