




Spanner - Google’s Globally-Distributed Database.pdf
免费下载
Spanner: Google’s Globally-Distributed Database
James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, JJ Furman,
Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, Wilson Hsieh,
Sebastian Kanthak, Eugene Kogan, Hongyi Li, Alexander Lloyd, Sergey Melnik, David Mwaura,
David Nagle, Sean Quinlan, Rajesh Rao, Lindsay Rolig, Yasushi Saito, Michal Szymaniak,
Christopher Taylor, Ruth Wang, Dale Woodford
Google, Inc.
Abstract
Spanner is Google’s scalable, multi-version, globally-
distributed, and synchronously-replicated database. It is
the first system to distribute data at global scale and sup-
port externally-consistent distributed transactions. This
paper describes how Spanner is structured, its feature set,
the rationale underlying various design decisions, and a
novel time API that exposes clock uncertainty. This API
and its implementation are critical to supporting exter-
nal consistency and a variety of powerful features: non-
blocking reads in the past, lock-free read-only transac-
tions, and atomic schema changes, across all of Spanner.
1 Introduction
Spanner is a scalable, globally-distributed database de-
signed, built, and deployed at Google. At the high-
est level of abstraction, it is a database that shards data
across many sets of Paxos [21] state machines in data-
centers spread all over the world. Replication is used for
global availability and geographic locality; clients auto-
matically failover between replicas. Spanner automati-
cally reshards data across machines as the amount of data
or the number of servers changes, and it automatically
migrates data across machines (even across datacenters)
to balance load and in response to failures. Spanner is
designed to scale up to millions of machines across hun-
dreds of datacenters and trillions of database rows.
Applications can use Spanner for high availability,
even in the face of wide-area natural disasters, by repli-
cating their data within or even across continents. Our
initial customer was F1 [35], a rewrite of Google’s ad-
vertising backend. F1 uses five replicas spread across
the United States. Most other applications will probably
replicate their data across 3 to 5 datacenters in one ge-
ographic region, but with relatively independent failure
modes. That is, most applications will choose lower la-
tency over higher availability, as long as they can survive
1 or 2 datacenter failures.
Spanner’s main focus is managing cross-datacenter
replicated data, but we have also spent a great deal of
time in designing and implementing important database
features on top of our distributed-systems infrastructure.
Even though many projects happily use Bigtable [9], we
have also consistently received complaints from users
that Bigtable can be difficult to use for some kinds of ap-
plications: those that have complex, evolving schemas,
or those that want strong consistency in the presence of
wide-area replication. (Similar claims have been made
by other authors [37].) Many applications at Google
have chosen to use Megastore [5] because of its semi-
relational data model and support for synchronous repli-
cation, despite its relatively poor write throughput. As a
consequence, Spanner has evolved from a Bigtable-like
versioned key-value store into a temporal multi-version
database. Data is stored in schematized semi-relational
tables; data is versioned, and each version is automati-
cally timestamped with its commit time; old versions of
data are subject to configurable garbage-collection poli-
cies; and applications can read data at old timestamps.
Spanner supports general-purpose transactions, and pro-
vides a SQL-based query language.
As a globally-distributed database, Spanner provides
several interesting features. First, the replication con-
figurations for data can be dynamically controlled at a
fine grain by applications. Applications can specify con-
straints to control which datacenters contain which data,
how far data is from its users (to control read latency),
how far replicas are from each other (to control write la-
tency), and how many replicas are maintained (to con-
trol durability, availability, and read performance). Data
can also be dynamically and transparently moved be-
tween datacenters by the system to balance resource us-
age across datacenters. Second, Spanner has two features
that are difficult to implement in a distributed database: it
Published in the Proceedings of OSDI 2012 1
provides externally consistent [16] reads and writes, and
globally-consistent reads across the database at a time-
stamp. These features enable Spanner to support con-
sistent backups, consistent MapReduce executions [12],
and atomic schema updates, all at global scale, and even
in the presence of ongoing transactions.
These features are enabled by the fact that Spanner as-
signs globally-meaningful commit timestamps to trans-
actions, even though transactions may be distributed.
The timestamps reflect serialization order. In addition,
the serialization order satisfies external consistency (or
equivalently, linearizability [20]): if a transaction T
1
commits before another transaction T
2
starts, then T
1
’s
commit timestamp is smaller than T
2
’s. Spanner is the
first system to provide such guarantees at global scale.
The key enabler of these properties is a new TrueTime
API and its implementation. The API directly exposes
clock uncertainty, and the guarantees on Spanner’s times-
tamps depend on the bounds that the implementation pro-
vides. If the uncertainty is large, Spanner slows down to
wait out that uncertainty. Google’s cluster-management
software provides an implementation of the TrueTime
API. This implementation keeps uncertainty small (gen-
erally less than 10ms) by using multiple modern clock
references (GPS and atomic clocks).
Section 2 describes the structure of Spanner’s imple-
mentation, its feature set, and the engineering decisions
that went into their design. Section 3 describes our new
TrueTime API and sketches its implementation. Sec-
tion 4 describes how Spanner uses TrueTime to imple-
ment externally-consistent distributed transactions, lock-
free read-only transactions, and atomic schema updates.
Section 5 provides some benchmarks on Spanner’s per-
formance and TrueTime behavior, and discusses the ex-
periences of F1. Sections 6, 7, and 8 describe related and
future work, and summarize our conclusions.
2 Implementation
This section describes the structure of and rationale un-
derlying Spanner’s implementation. It then describes the
directory abstraction, which is used to manage replica-
tion and locality, and is the unit of data movement. Fi-
nally, it describes our data model, why Spanner looks
like a relational database instead of a key-value store, and
how applications can control data locality.
A Spanner deployment is called a universe. Given
that Spanner manages data globally, there will be only
a handful of running universes. We currently run a
test/playground universe, a development/production uni-
verse, and a production-only universe.
Spanner is organized as a set of zones, where each
zone is the rough analog of a deployment of Bigtable
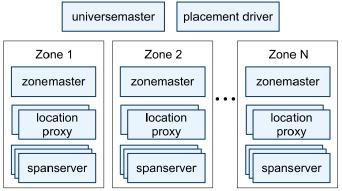
Figure 1: Spanner server organization.
servers [9]. Zones are the unit of administrative deploy-
ment. The set of zones is also the set of locations across
which data can be replicated. Zones can be added to or
removed from a running system as new datacenters are
brought into service and old ones are turned off, respec-
tively. Zones are also the unit of physical isolation: there
may be one or more zones in a datacenter, for example,
if different applications’ data must be partitioned across
different sets of servers in the same datacenter.
Figure 1 illustrates the servers in a Spanner universe.
A zone has one zonemaster and between one hundred
and several thousand spanservers. The former assigns
data to spanservers; the latter serve data to clients. The
per-zone location proxies are used by clients to locate
the spanservers assigned to serve their data. The uni-
verse master and the placement driver are currently sin-
gletons. The universe master is primarily a console that
displays status information about all the zones for inter-
active debugging. The placement driver handles auto-
mated movement of data across zones on the timescale
of minutes. The placement driver periodically commu-
nicates with the spanservers to find data that needs to be
moved, either to meet updated replication constraints or
to balance load. For space reasons, we will only describe
the spanserver in any detail.
2.1 Spanserver Software Stack
This section focuses on the spanserver implementation
to illustrate how replication and distributed transactions
have been layered onto our Bigtable-based implementa-
tion. The software stack is shown in Figure 2. At the
bottom, each spanserver is responsible for between 100
and 1000 instances of a data structure called a tablet. A
tablet is similar to Bigtable’s tablet abstraction, in that it
implements a bag of the following mappings:
(key:string, timestamp:int64) → string
Unlike Bigtable, Spanner assigns timestamps to data,
which is an important way in which Spanner is more
like a multi-version database than a key-value store. A
Published in the Proceedings of OSDI 2012 2

Figure 2: Spanserver software stack.
tablet’s state is stored in set of B-tree-like files and a
write-ahead log, all on a distributed file system called
Colossus (the successor to the Google File System [15]).
To support replication, each spanserver implements a
single Paxos state machine on top of each tablet. (An
early Spanner incarnation supported multiple Paxos state
machines per tablet, which allowed for more flexible
replication configurations. The complexity of that de-
sign led us to abandon it.) Each state machine stores
its metadata and log in its corresponding tablet. Our
Paxos implementation supports long-lived leaders with
time-based leader leases, whose length defaults to 10
seconds. The current Spanner implementation logs ev-
ery Paxos write twice: once in the tablet’s log, and once
in the Paxos log. This choice was made out of expedi-
ency, and we are likely to remedy this eventually. Our
implementation of Paxos is pipelined, so as to improve
Spanner’s throughput in the presence of WAN latencies;
but writes are applied by Paxos in order (a fact on which
we will depend in Section 4).
The Paxos state machines are used to implement a
consistently replicated bag of mappings. The key-value
mapping state of each replica is stored in its correspond-
ing tablet. Writes must initiate the Paxos protocol at the
leader; reads access state directly from the underlying
tablet at any replica that is sufficiently up-to-date. The
set of replicas is collectively a Paxos group.
At every replica that is a leader, each spanserver im-
plements a lock table to implement concurrency control.
The lock table contains the state for two-phase lock-
ing: it maps ranges of keys to lock states. (Note that
having a long-lived Paxos leader is critical to efficiently
managing the lock table.) In both Bigtable and Span-
ner, we designed for long-lived transactions (for exam-
ple, for report generation, which might take on the order
of minutes), which perform poorly under optimistic con-
currency control in the presence of conflicts. Operations
Figure 3: Directories are the unit of data movement between
Paxos groups.
that require synchronization, such as transactional reads,
acquire locks in the lock table; other operations bypass
the lock table.
At every replica that is a leader, each spanserver also
implements a transaction manager to support distributed
transactions. The transaction manager is used to imple-
ment a participant leader; the other replicas in the group
will be referred to as participant slaves. If a transac-
tion involves only one Paxos group (as is the case for
most transactions), it can bypass the transaction manager,
since the lock table and Paxos together provide transac-
tionality. If a transaction involves more than one Paxos
group, those groups’ leaders coordinate to perform two-
phase commit. One of the participant groups is chosen as
the coordinator: the participant leader of that group will
be referred to as the coordinator leader, and the slaves of
that group as coordinator slaves . The state of each trans-
action manager is stored in the underlying Paxos group
(and therefore is replicated).
2.2 Directories and Placement
On top of the bag of key-value mappings, the Spanner
implementation supports a bucketing abstraction called a
directory, which is a set of contiguous keys that share a
common prefix. (The choice of the term directory is a
historical accident; a better term might be bucket.) We
will explain the source of that prefix in Section 2.3. Sup-
porting directories allows applications to control the lo-
cality of their data by choosing keys carefully.
A directory is the unit of data placement. All data in
a directory has the same replication configuration. When
data is moved between Paxos groups, it is moved direc-
tory by directory, as shown in Figure 3. Spanner might
move a directory to shed load from a Paxos group; to put
directories that are frequently accessed together into the
same group; or to move a directory into a group that is
closer to its accessors. Directories can be moved while
client operations are ongoing. One could expect that a
50MB directory can be moved in a few seconds.
The fact that a Paxos group may contain multiple di-
rectories implies that a Spanner tablet is different from
Published in the Proceedings of OSDI 2012 3
of 14
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
盛天
最新上传

文档被以下合辑收录
相关文档
评论