


4条回答
默认
最新

 评论
评论


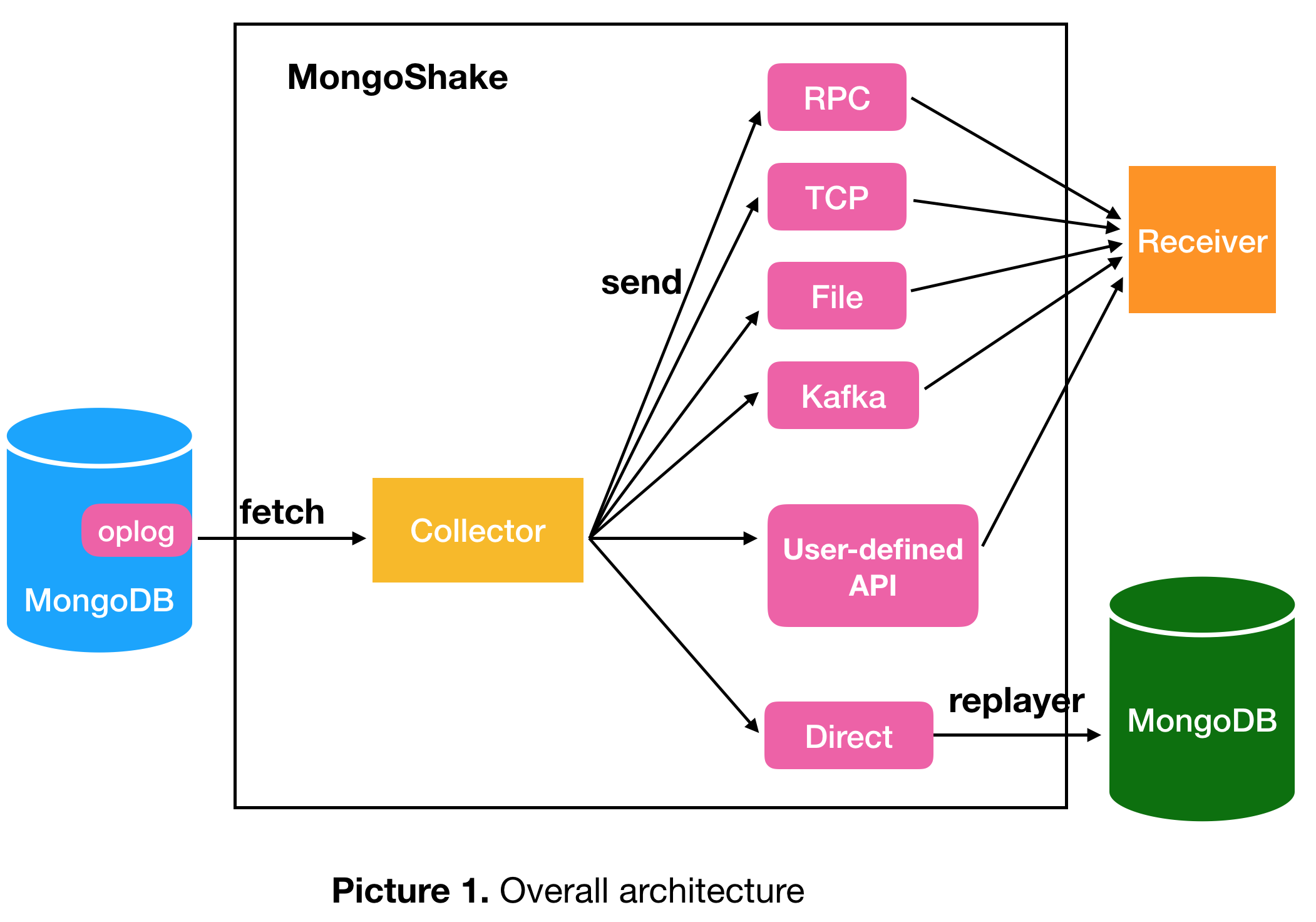
回答交流
Markdown
请输入正文
提交
相关推荐
Mac 系统下 新安装的mongodb 怎么导入数据?
回答 1
已采纳
macOS不建议安装mongodb数据库,可以用容器或者虚拟机方式代替
mongodb 怎么查询历史执行的sql?
回答 1
【方法一】查询v$sqltext、v$sqlarea、v$sqlstats视图selectfromv$sqlareatwheret.PARSINGSCHEMANAMEin('schema')order
mongodb创建单个字段全文索引后,业务数据插入很慢
回答 5
模糊查询本身就存在性能问题。因为索引的内容不在内存中,索引需要不停的读取文件,加载到内存,导致io高。现有情况下最好的办法是内存加大,把数据全部放在内存。或则模糊查询更改逻辑。底层硬盘必须是ssd
请问以下截图哪里有错?显示invalid character' /r' in regular expression literal
回答 1
是不是包含特殊字符。可以加jsonArrayandlegacy看看
mongo分片集群中 想要查看分片中chunk的大小 (不是设置的chunkSize的大小) 想要手动迁移数据 怎么查看块的大小
回答 1
已采纳
chunksize默认的大小是64M,用mongos连接到config数据库,通过查看config.settings可以看到这个值:例如:mongos>useconfigmongos>db
mongodb 分组统计然后insert into其他表,怎么实现呢?
回答 1
已采纳
db.orders.find().forEach(function(i){i.tsimportednewDate();db.orders1.insert(i);});
mongdb同步到mysql怎么做?有什么推荐的学习资料么?
回答 1
对于这方面没什么好的方式。直接把mongodb执行语句分解,用语句方式刷到mysql上面。mongob里oplog,changestream都可以捕捉到变化。或尝试ETL工具kettle也可以
mongo书籍
回答 1
1、《MongoDB权威指南第3版》2、官方文档
MongoDB建表(集合)的时候可以加中文表名字注释吗?
回答 1
已采纳
没有直接向集合添加注释的方法。可以创建一个存储元数据的集合。
云数据库mysql和普通的安装的mysql有什么区别?
回答 1
云数据库的好处就是可以做到即买即用,跟我们日常购物一样便捷,省去的自己找安装包,找依赖包,下载安装的过程。
问题信息
请登录之后查看
邀请回答
暂无人订阅该标签,敬请期待~~

