

2023-02-14
查询sql优化
sqltext:
SELECT COUNT(1)
FROM ACT_CARD_BANK
WHERE CARD_NO IN
(
SELECT CARD_NO
FROM XSHTEST.XSH_CARD_BANK
WHERE BIN_NO IN ('731018', '731023', '731024', '731025', '731026', '731027')
AND STATUS = '06'
)
AND STATUS = '04';
执行计划如下:
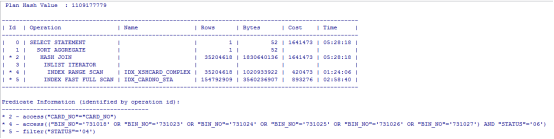
涉及表的索引情况:
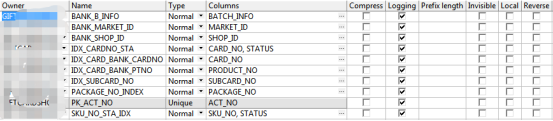

表的行数:
ACT_CARD_BANK 399187646
XSH_CARD_BANK 228751942
统计信息为2023-02-14重新收集,脚本如下:
exec dbms_stats.gather_table_stats(ownname => '$owner',tabname => 'XSH_CARD_BANK',estimate_percent => 0.1,method_opt=> 'for all indexed columns');
看看还有没有可以优化的地方,请多指教。
我来答
添加附件
收藏
分享
问题补充
3条回答
默认
最新
 评论
评论
回答交流
Markdown
请输入正文
提交
相关推荐
SQL SERVER数据库,怎么进行日常的维护和优化?
回答 2
优化SQL主要是看执行计划和执行时间。超出预期的就对照着执行计划进行,改写或者重新设计。
Mysql SQL索引优化
回答 7
首先createdate与updatedate谁的区分度更好。谁的区分度更好就决定了,这两个字段哪个排在前面。然后再看state与type这两个区分度好不好。如果也有较好的区分度,那就再往前放。如果区
mysql关于多表join关联的执行流程
回答 5
在驱动表上建立条件过滤索引。在被驱动表上建立关联字段索引
SQL优化减少逻辑读
回答 12
看T表关键列的数据分布,然后考虑建复合索引
GBase8a慢SQL优化
回答 1
与现场沟通怀疑是因为左侧关联字段ct.GROUPID加了函数造成索引失效,修改之后执行时间仍然在半小时以上,打开trace日志查看gnode层日志可见join返回行数远远大于两张源表的数据量,因此怀疑
千万级的大数据量如何快速查询
回答 2
已采纳
这个还得看具体SQL和你的查询需求。如果千万级数据量的表访问少量数据,过滤条件尽量按索引。如果需要查询大量数据,可以在资源允许的情况下对大表启用并行。如果查询条件比较规律,查询时效性要求不高,可以考虑
如何编写一个程序来实现SQL优化?
回答 1
没有这种程序,要不然DBA就失业了
MySQL SQL优化,干预表关联顺序
回答 3
在MySQL5.7中,确实无法像MySQL8.0那样使用显式的JOINhint来指定表的连接顺序。然而,可以通过优化查询语句的写法来尽量影响MySQL查询优化器的执行计划。在你的情况下,a表作为驱动表
SQL优化求助!!!
回答 7
已采纳
优化建议: 更换SSD存储; fixcontrol 308224461; 开并行(如果不更换存储, 意义不大,只是用来使用更多
查询计划的理解
回答 1
如果还没有解决,可以加微信oraservice提供详细信息以便进一步优化,感觉左边的执行计划也不是太好,还有sql的写法可能也有改进的地方。

