




继续我的每月 PostgreSQL 基准测试系列,这些最新发现旨在帮助开发人员提高 PostgreSQL 性能稳定性。当我不得不重置用于每天500个用户基准测试的 AWS 实例并损失 20% 的性能时,我发现了性能稳定性问题。我唯一的解释是重置实例在数据中心物理移动。从正在进行的基准测试的角度来看,这是不可接受的。我需要知道性能回归是否是由于代码更改引起的,因此环境必须尽可能保持稳定。
测试
为了更好的控制环境,EDB购买了一台我们自己托管的专用服务器。为了帮助我们了解存储系统的 I/O 性能,我们使用fio运行了许多测试。这样做的原因是为了确保我们充分利用硬件,因为 EDB 团队内部对 NVMe 驱动器的性能以及使用 Linux 软件 RAID (mdraid) 是否会对CPU 结果。我们使用 2TB 测试来确保数据比系统上可用 RAM 大得多,但只有一个驱动器测试没有足够的空间。fio配置如下:
[root@chaos ~]# cat read-write.fio [read-write] rw=rw rwmixread=75 # 18g for 2+ drives size=13g directory=/nvme fadvise_hint=0 blocksize=8k direct=0 # 1 job per available CPU thread numjobs=112 nrfiles=1 runtime=1h time_based exec_prerun=echo 3 > /proc/sys/vm/drop_caches复制
结果如下所示:
| 读/写比 | 驱动配置 | # | 驱动器大小 | 大小/核心 (MiB) | 总大小 (GiB) | 读取 IOP | 写入 IOP | 总眼压 | 读取带宽 (MB/s) | 写入带宽 (MB/s) | 总体重 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 75/25 | 1 个 NVMe | 1 | 1.5TB | 13312 | 1456 | 305,766 | 101,877 | 407,643 | 2505 | 835 | 3340 |
| 75/25 | 2 个 NVMe,RAID 0 | 2 | 3.0TB | 18432 | 2016年 | 614,783 | 204,890 | 819,673 | 5037 | 1679 | 6716 |
| 75/25 | 4 个 NVMe,RAID 0 | 4 | 6.0TB | 18432 | 2016年 | 1,238,221 | 403,096 | 1,641,317 | 9907 | 3303 | 13210 |
| 75/25 | 6 个 NVMe,RAID 0 | 6 | 9.0TB | 18432 | 2016年 | 1,609,626 | 527,612 | 2,137,238 | 12288 | 4122 | 16410 |
或以图形形式:
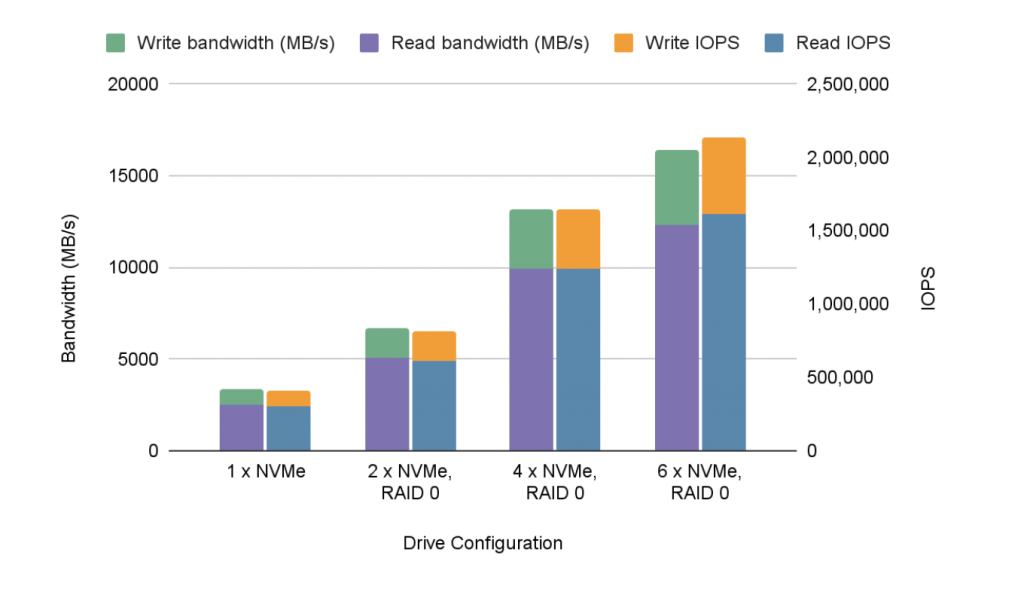
这些驱动器基本上是线性扩展的,这非常令人放心。我们的信念是,它可能会继续几乎线性扩展,直到驱动器使用的 PCI 通道数(它们是 x4 驱动器,因此每个通道有四个通道)接近系统中的通道数(每个通道 48 个)。两个 Xeon Gold 6258R CPU)。当然,我们只有六个驱动器,因此无法验证该理论。
请注意,这些测试是使用 RAID 0(条带化)执行的。Linux mdraid 很可能会使用更多(或更少)具有不同 RAID 级别的 CPU 资源。RAID 0 在这里是合适的,因为我们试图最大限度地提高跨设备并行读/写的可能性,因为这台机器旨在运行回归测试的基准测试,而不是存储有价值的生产数据。
结果
该机器的完整规格如下:
PowerEdge R740XD 服务器
- 2 个英特尔至强金牌 6258R 2.7G、28C/56T、10.4GT/s、38.5M 缓存
- 16 x 64GB RDIMM,3200MT/s,双列(共 1TB)
- 4 x 800GB SSD SAS 混合使用 12Gbps 512e 2.5 英寸热插拔 AG 驱动器
- 6 个戴尔 1.6TB、NVMe、混合使用 Express Flash、2.5 SFF 驱动器
- 1 个 Broadcom 57412 双端口 10GbE SFP+ 和 5720 双端口 1GbE BASE-T rNDC
如果您正在努力提高性能稳定性,这些发现应该有助于简化流程。请继续关注下个月,届时我将展示使用该机器的 PG 13.3 和 PG 14beta1 之间的比较。
