




gRPC是什么?
gRPC vs. Restful API
gRPC优势
gRPC缺点
Protobuf
编码结构
何为 ProtoBuf?
使用 ProtoBuf
关于 ProtoBuf 的一些思考
深入 ProtoBuf - 编码
Varints 编码
HTTP2
静态表
动态表
HPACK 头压缩
数据压缩
gRPC是什么?
gRPC是什么可以用官网的一句话来概括
A high-performance, open-source universal RPC framework 高性能、开源的通用RPC框架
所谓RPC(remote procedure call 远程过程调用)框架实际是提供了一套机制,使得应用程序之间可以进行通信,而且也遵从server/client模型。使用的时候客户端调用server端提供的接口就像是调用本地的函数一样。
参考我前面的文章《什么是RPC?》
gRPC VS Restful
gRPC和restful API都提供了一套通信机制,用于server/client模型通信,而且它们都使用http作为底层的传输协议(严格地说, gRPC使用的http2.0,而restful api则不一定)。不过gRPC还是有些特有的优势,如下:
gRPC可以通过protobuf来定义接口,从而可以有更加严格的接口约束条件。关于protobuf可以参见笔者之前的小文Google Protobuf简明教程
另外,通过protobuf可以将数据序列化为二进制编码,这会大幅减少需要传输的数据量,从而大幅提高性能。
gRPC可以方便地支持流式通信(理论上通过http2.0就可以使用streaming模式, 但是通常web服务的restful api似乎很少这么用,通常的流式数据应用如视频流,一般都会使用专门的协议如HLS,RTMP等,这些就不是我们通常web服务了,而是有专门的服务器应用。)
gRPC优势
需要使用protobuf定义接口,即.proto文件,压缩率比Json更好。
基于HTTP2,支持流数据处理,性能更好。
强类型,也就是说,写的时候,编译器会帮你检查很多东西,这样就不会留着在运行时报错,正所谓动态一时爽,重构火葬场。从我个人体验来说,强类型的确能够帮助减少很多bug。
当你对接很多RESTful API时,你会发现,每个语言都要封装一份SDK,否则就只能大家都裸写JSON,这是一件很蛋疼的 重复劳动的事情,gRPC解决了这个痛点(其它RPC大多也解决了)。
gRPC缺点
GRPC尚未提供连接池
尚未提供“服务发现”、“负载均衡”机制
因为基于HTTP2,绝大多数HTTP Server、Nginx都尚不支持
就是GRPC生成的接口
Protobuf
何为 ProtoBuf?
protocol buffers 是一种语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于(数据)通信协议、数据存储等。
Protocol Buffers 是一种灵活,高效,自动化机制的结构数据序列化方法-可类比 XML,但是比 XML 更小(3 ~ 10倍)、更快(20 ~ 100倍)、更为简单。
你可以定义数据的结构,然后使用特殊生成的源代码轻松的在各种数据流中使用各种语言进行编写和读取结构数据。你甚至可以更新数据结构,而不破坏由旧数据结构编译的已部署程序。
简单来讲, ProtoBuf 是结构数据序列化[1] 方法,可简单类比于 XML[2],其具有以下特点:
语言无关、平台无关。即 ProtoBuf 支持 Java、C++、Python 等多种语言,支持多个平台
高效。即比 XML 更小(3 ~ 10倍)、更快(20 ~ 100倍)、更为简单
扩展性、兼容性好。你可以更新数据结构,而不影响和破坏原有的旧程序
使用 ProtoBuf
第一步,创建 .proto 文件,定义数据结构
第二步,protoc 编译 .proto 文件生成读写接口
第三步,调用接口实现序列化、反序列化以及读写
关于 ProtoBuf 的一些思考
最终对这些个人思考做一些小小的总结:
XML、JSON、ProtoBuf 都具有数据结构化和数据序列化的能力
XML、JSON 更注重数据结构化,关注人类可读性和语义表达能力。ProtoBuf 更注重数据序列化,关注效率、空间、速度,人类可读性差,语义表达能力不足(为保证极致的效率,会舍弃一部分元信息)
ProtoBuf 的应用场景更为明确,XML、JSON 的应用场景更为丰富。
深入 ProtoBuf - 编码
在对 ProtoBuf 做了一些基本介绍之后,这篇开始进入正题,深入 ProtoBuf 的一些原理,让我们看看 ProtoBuf 是如何尽其所能的压榨编码性能和效率的。
编码结构
TLV 格式是我们比较熟悉的编码格式。
所谓的 TLV 即 Tag - Length - Value。Tag 作为该字段的唯一标识,Length 代表 Value 数据域的长度,最后的 Value 便是数据本身。
ProtoBuf 编码采用类似的结构,但是实际上又有较大区别,其编码结构可见下图: 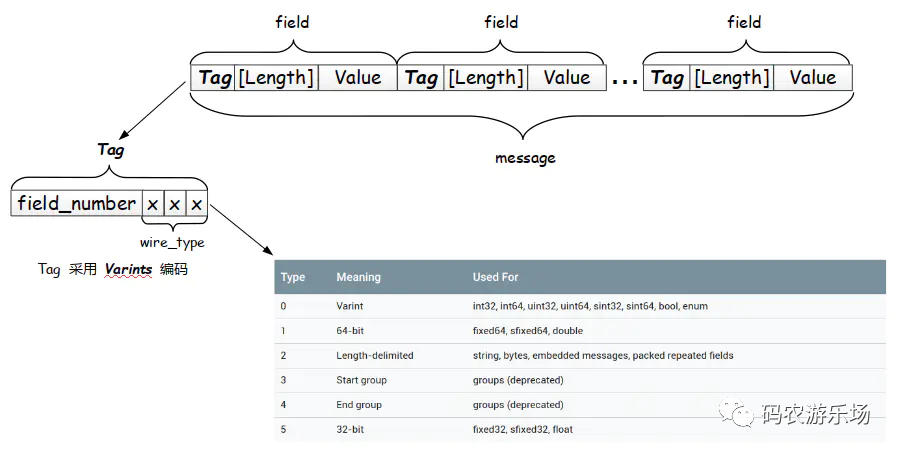
我们来一步步解析上图所表达的编码结构。
首先,每一个 message 进行编码,其结果由一个个字段组成,每个字段可划分为 Tag - [Length] - Value,如下图所示:
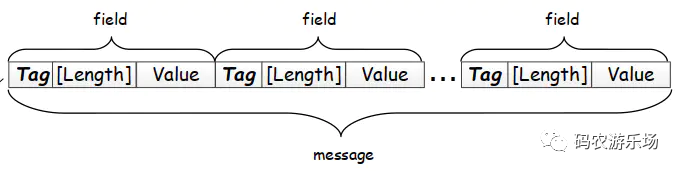
特别注意这里的 [Length] 是可选的,含义是针对不同类型的数据编码结构可能会变成 Tag - Value 的形式,如果变成这样的形式,没有了 Length 我们该如何确定 Value 的边界?答案就是 Varint 编码,在后面将详细介绍。
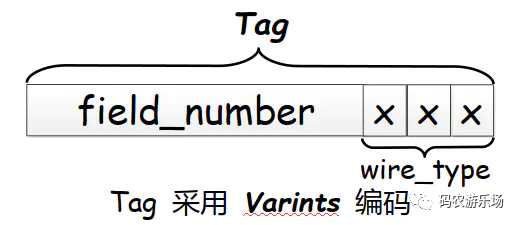
继续深入 Tag ,Tag 由 field_number 和 wire_type 两个部分组成:
field_number: message 定义字段时指定的字段编号
wire_type: ProtoBuf 编码类型,根据这个类型选择不同的 Value 编码方案。
整个 Tag 采用 Varints 编码方案进行编码,Varints 编码会在后面详细介绍。
Tag 结构如下图所示:
3 bit 的 wire_type 最多可以表达 8 种编码类型,目前 ProtoBuf 已经定义了 6 种,如下图所示:
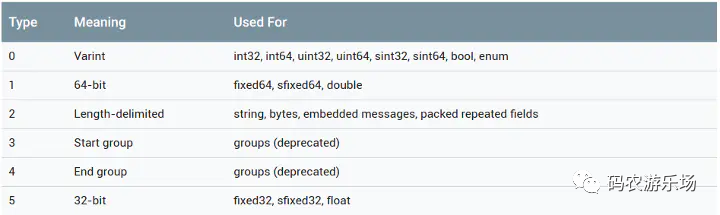
第一列即是对应的类型编号,第二列为面向最终编码的编码类型,第三列是面向开发者的 message 字段的类型。
注意其中的 Start group 和 End group 两种类型已被遗弃。
另外要特别注意一点,虽然 wire_type 代表编码类型,但是 Varint 这个编码类型里针对 sint32、sint64 又会有一些特别编码(ZigTag 编码)处理,相当于 Varint 这个编码类型里又存在两种不同编码。
Varints 编码
总结的讲,Varints 编码的规则主要为以下三点:
在每个字节开头的 bit 设置了 msb(most significant bit ),标识是否需要继续读取下一个字节
存储数字对应的二进制补码
补码的低位排在前面
为什么低位排在前面?这里主要是为编码实现(移位操作)做的一个小优化。可以尝试写个二进制移位进行编码解码的小例子来体会这一点。
HTTP2
HPACK 头压缩
静态表
静态表是写死的,其索引值共有61对,表的内容如下:
| Index | Header Name | Header Value |
+-------+-----------------------------+---------------+
| 1 | :authority ||
| 2 | :method | GET |
| 3 | :method | POST |
| 4 | :path | |
| 5 | :path | index.html |
| 6 | :scheme | http |
| 7 | :scheme | https |
| 8 | :status | 200 |
| 9 | :status | 204 |
| 10 | :status | 206 |
| 11 | :status | 304 |
| 12 | :status | 400 |
| 13 | :status | 404 |
| 14 | :status | 500 |
| 15 | accept-charset ||
| 16 | accept-encoding | gzip, deflate |
| 17 | accept-language ||
| 18 | accept-ranges ||
| 19 | accept ||
| 20 | access-control-allow-origin ||
| 21 | age ||
| 22 | allow ||
| 23 | authorization ||
| 24 | cache-control ||
| 25 | content-disposition ||
| 26 | content-encoding ||
| 27 | content-language ||
| 28 | content-length ||
| 29 | content-location ||
| 30 | content-range ||
| 31 | content-type ||
| 32 | cookie ||
| 33 | date ||
| 34 | etag ||
| 35 | expect ||
| 36 | expires ||
| 37 | from ||
| 38 | host ||
| 39 | if-match ||
| 40 | if-modified-since ||
| 41 | if-none-match ||
| 42 | if-range ||
| 43 | if-unmodified-since ||
| 44 | last-modified ||
| 45 | link ||
| 46 | location ||
| 47 | max-forwards ||
| 48 | proxy-authenticate ||
| 49 | proxy-authorization ||
| 50 | range ||
| 51 | referer ||
| 52 | refresh ||
| 53 | retry-after ||
| 54 | server ||
| 55 | set-cookie ||
| 56 | strict-transport-security ||
| 57 | transfer-encoding ||
| 58 | user-agent ||
| 59 | vary ||
| 60 | via ||
| 61 | www-authenticate ||复制
动态表
动态表的值却是在每次请求中,由发送端进行扩充的。静态表和动态表共同构成了索引值,索引值最小为。其中,动态表的大小k是可以增大的,每次在动态表中插入新的索引,新插入的键值对索引下标是s+1,动态表里的其他数据下标依次往后挪。
动态表的大小并不是无限大的,有一个可设置的最大值,如果新插入数据时,发现table size超过这个值,会把索引最大的键值对移除。
数据压缩
哈夫曼树?
贪婪算法?
关于数据压缩,后面单独发一篇来介绍。
总结
Protobuf的压缩率是非常高的。
Http/2的优势很多,多路复用、二进制分帧、首部压缩。
微信识别二维码关注

