





导读:前面我们介绍了关于spark编程的基础知识以及三个简单示例,那么应该怎么去调试或者提交运行spark程序呢?
导读:前面我们介绍了关于spark编程的基础知识以及三个简单示例,那么应该怎么去调试或者提交运行spark程序呢?
作者:小舰 中国人民大学计算机硕士
来源:DLab数据实验室(ID:rucdlab)
Spark提供了两种运行的方式,一种是通过spark-shell的方式,另一种是通过IDE编译打包,然后通过spark-submit的方式提交运行.
一、spark-shell方式
spark-shell 是以一种交互式命令行方式将Spark应用程序跑在指定模式上,也可以通过Spark-submit提交指定运用程序,Spark-shell 底层调用的是Spark-submit,二者的使用参数一致的,通过- -help 查看参数:
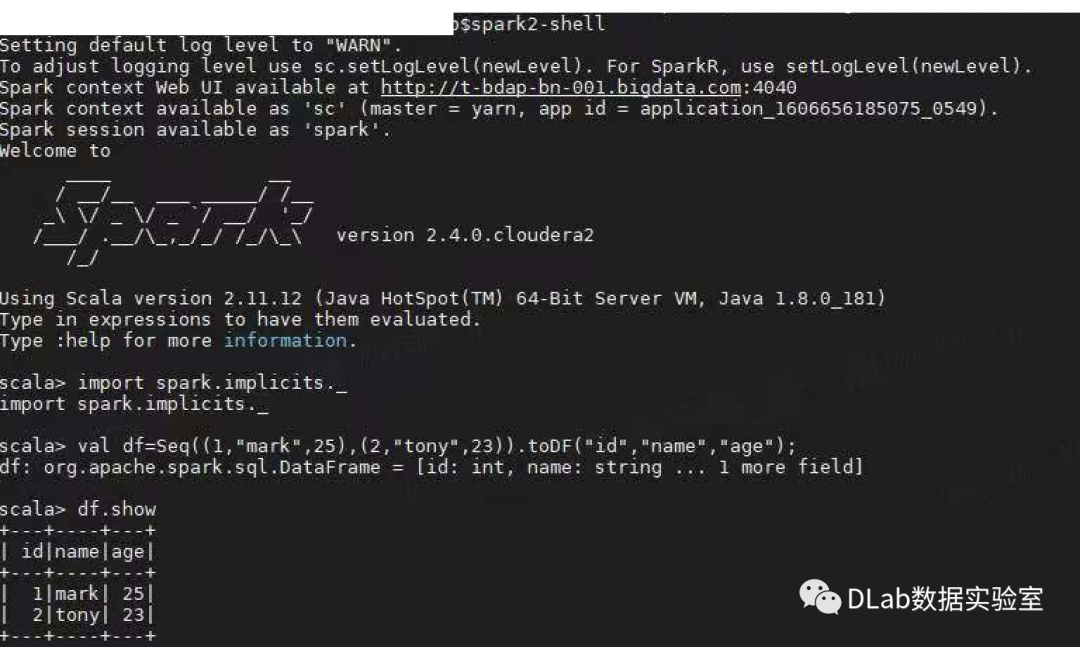
上图所示的就是我们已经进入了命令行了,我们可以看到已经为我们创建好了两个重要的实例变量Spark Context(sc)和Spark Session(spark),通过这两个变量我们可以进行一些操作。
同时,如果我们想要依赖第三方的包,或者增加一些初始化的配置参数,也可以通过一下的方式进行
spark-shell --master spark://ip:port/yarn/local --conf spark.sql.hive.metastore.jars=/xxx/.jar --jar xxx/.jar
二、spark-submit方式
另外一种就是通过在IDE里面编写代码,然后打包运行
1.打包
File->Project Structure->Artifacts
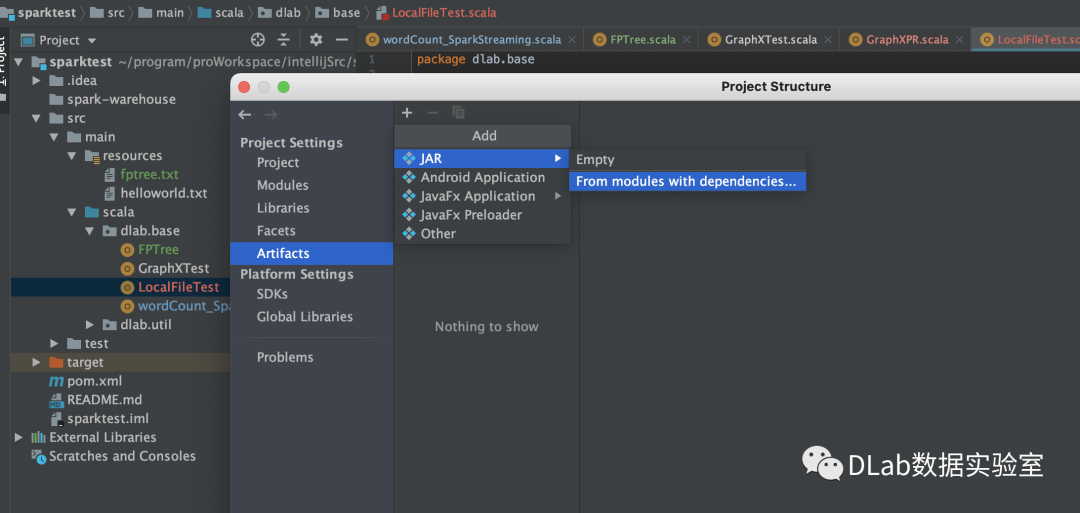
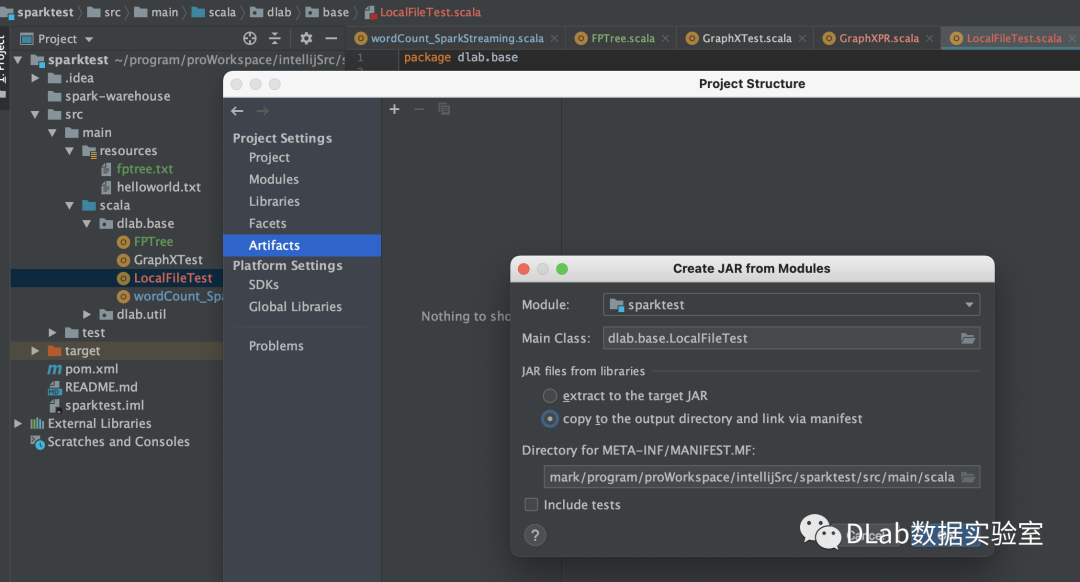
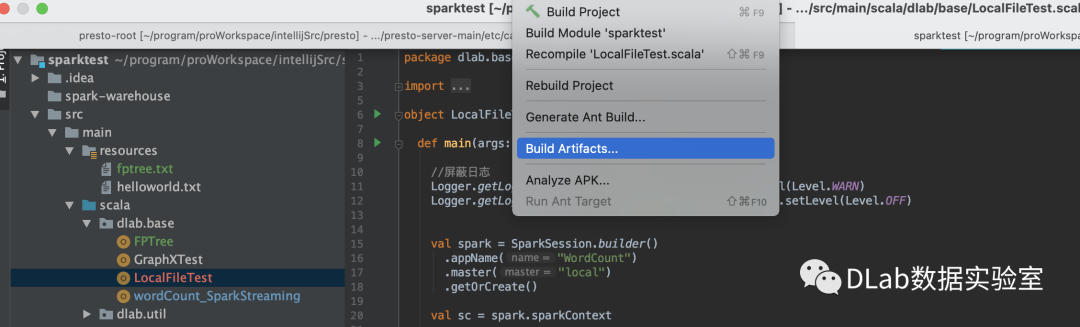
build完成之后你会在out目录下artifacts找到相应的jar包,例如我的这个就是sparktest.jar
2.提交
然后就是提交阶段,同样也可以指定部署模式、内存、内核以及一些其他的参数或第三方jar包,当然了还有很多提交参数,见附录。
spark2-submit --master spark://ip:port/yarn/local --deploy-mode client/cluster --num-executors 30 --executor-memory 8g --executor-cores 2 --conf spark.sql.broadcast.threshold=200 --jar xxx.jar --class dlab.base.localFileTest sparktest.jar
三、总结
以上就是spark常用的两种部署模式,一般spark-shell的方式多用于小的临时的任务以及一些测试,更多的还是通过打包提交的方式。上面也提到了部署模式的问题,下一期我们可以来聊一聊~
附录:
-master: 指定运行模式,spark://host:port, mesos://host:port, yarn, or local[n].
-deploy-mode: 指定将driver端运行在client 还是在cluster.
-class: 指定运行程序main方法类名,一般是应用程序的包名+类名
-name: 运用程序名称
-jars: 需要在driver端和executor端运行的jar,如mysql驱动包
-packages: maven管理的项目坐标GAV,多个以逗号分隔
-conf: 以key=value的形式传入sparkconf参数,所传入的参数必须是以spark.开头
-properties-file: 指定新的conf文件,默认使用spark-default.conf
-driver-memory:指定driver端运行内存,默认1G
-driver-cores:指定driver端cpu数量,默认1,仅在Standalone和Yarn的cluster模式下
-executor-memory:指定executor端的内存,默认1G
-total-executor-cores:所有executor使用的cores
-executor-cores: 每个executor使用的cores
-driver-class-path: driver端的classpath
-executor-class-path:executor端的classpath

●Spark原理与实战--SparkStreaming流处理(二)

文章都看完了 不点个
不点个 吗
吗
欢迎 点赞、在看、分享 三连哦~~
