





导读:我们在创建Hive表的时候,一般都会指定数据文件的存储格式,不同的数据格式会对日后的数据读写性能产生不同的影响。Presto目前支持Hive提供的几种存储格式,但是如果我们自定义了一些数据存储格式,Presto要如何适配呢?
导读:我们在创建Hive表的时候,一般都会指定数据文件的存储格式,不同的数据格式会对日后的数据读写性能产生不同的影响。Presto目前支持Hive提供的几种存储格式,但是如果我们自定义了一些数据存储格式,Presto要如何适配呢?

1.Hive表源文件存储格式
create table test ( id int, name string ) stored as parquet.
Hive表源文件存储格式包括比如数据是否序列化,明文还是二进制,行存还是列存,是否压缩等方面。例如上面是一个hive的建表语句,最后通过stored as命令将表的源文件存储格式定为parquet格式。
目前Hive常用的存储格式有以下几种:
(1)TEXTFILE,默认格式,建表时不指定默认为这个格式,数据在HDFS上不进行任何处理,可以直接明文获取到内容;
(2)SEQUENCEFILE,是一种Hadoop API提供的二进制文件,使用方便、可分割、可压缩等特点。
(3)RCFILE ,一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
(4)ORC 属于RCFILE的升级版。
(5)Parquet也是一种优秀的列式存储格式。
这几种存储格式在这里非本文重点就不着重展开讲了,我们只需要大概知道Hive支持的几种不同的存储格式即可。
2.Presto支持的存储格式
Presto是一个OLAP类型的引擎,因此Presto天然地对列式存储比较友好,Presto默认的数据文件存储类型就是ORC格式。从Presto源码的HiveConfig中我们就可以看到,如下:


3.Presto的自定义格式支持
那么Presto读取Hive表到底能支持哪些存储格式呢?在HiveStorageFormat类中我们可以看到,这些可以被支持的存储格式是通过枚举列出来的,分别是序列化和反序列化、输入格式和输出格式。
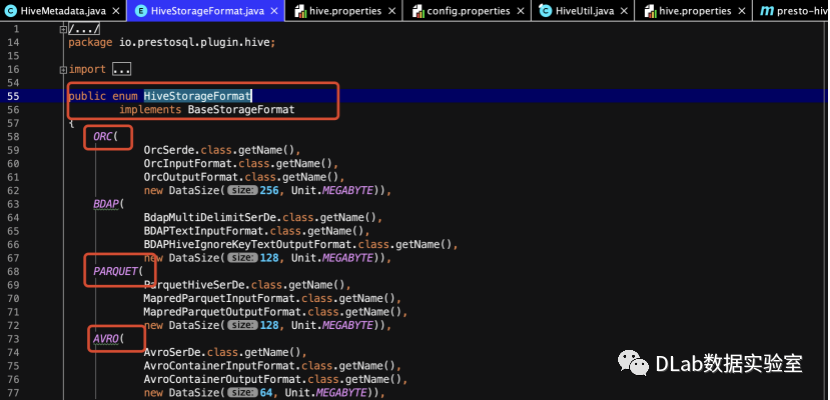
在进行Hive Connector初始化的时候,会通过这个构造方法将每个枚举类型的存储格式进行初始化.

当查询一个表的时候,会通过该方法判断表的元数据中记录的该表存储格式在Hive Connector中是否存在,如果存在就会调用,如果不存在就会抛出一个unsupport的异常。

但是在企业的复杂场景中,难免会出现一些企业自定义的存储格式,例如我将要讲的例子中,我们自定义了适合我们自己业务的输入输出格式以及序列化方式,比如我们对于每字段之间的分割和换行有我们自己的一套分隔符,但是很显然这个存储格式并不在Presto的引擎支持范畴里。所以在进行查询的时候就会出现如下的异常。
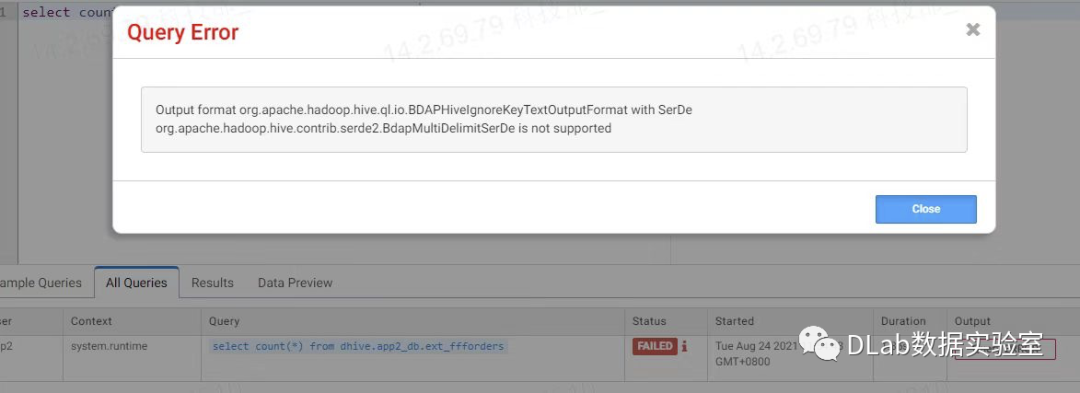
如何解决呢,其实有了上面的分析就会发现比较简单了,我们只需要将我们的自定义存储格式的jar包引入进来,然后在我们的枚举类型中添加自己的存储格式即可,如下所示

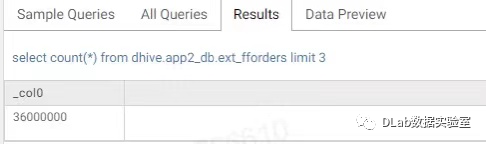
这样我们就可以用到我们的自定义存储格式了,编译打包后可以发现已经可以支持我们的格式,可以查询出结果了。
总结
到这里我们就了解了Hive的源数据存储格式以及Presto引擎对于Hive表的数据格式的支持现状,以及兼容自定义数据格式的方法。其实目前Presto在社区最新的版本中已经可以根据传入的存储格式jar包自动解析出相应的存储格式,但是我们在真实的场景中也不可能做到永远使用最新的版本,通过这种修改其实已经可以支持我们的功能需求了。
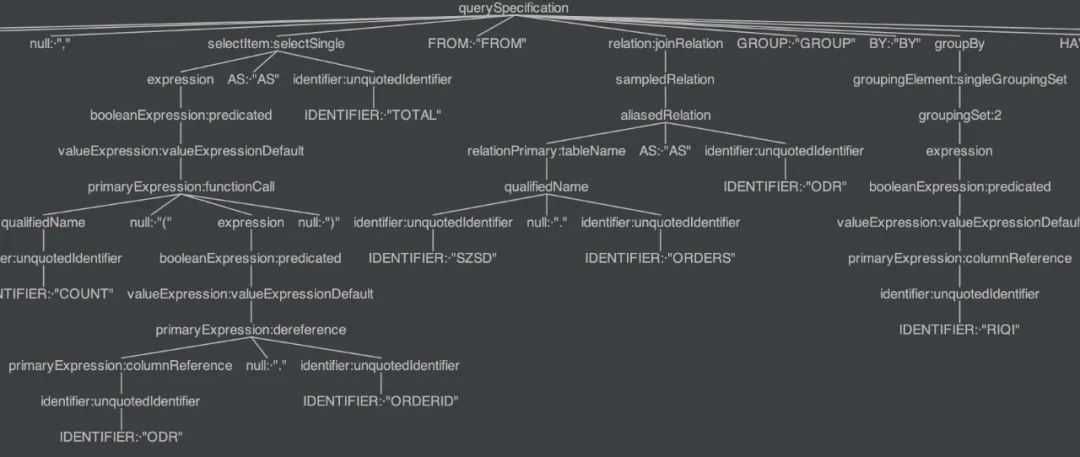
SQL引擎如何把语句转换为一个抽象语法树

【论文分享】Presto: SQL on Everything
