





导读:前几日测试的同事突然问我我写的SparkSQL跑出的结果跟他们之前用Hive跑数据的结果不一致是怎么回事,临近上线突然一惊。我的脑海立刻涌现出了几种结论:
“不可能,
不可能,
绝对不可能!”
当然,又经过了我理智的思考后,我还是觉得这里面必有蹊跷。
导读:前几日测试的同事突然问我我写的SparkSQL跑出的结果跟他们之前用Hive跑数据的结果不一致是怎么回事,临近上线突然一惊。我的脑海立刻涌现出了几种结论:
“不可能,
不可能,
绝对不可能!”
当然,又经过了我理智的思考后,我还是觉得这里面必有蹊跷。
作者:小舰 中国人民大学计算机硕士
来源:DLab数据实验室(ID:rucdlab)
1.排查原因
首先是spark中本身会出现的问题,就是 join on 两边的字段类型是否一致。
当 on 条件两边字段类型,一边是string,一边是bigint,在hive中 会 把 string,bigint 都转成 double,结果错误;当 on 条件两边字段类型,一边是string,一边是decimal;spark中会 把 string,decimal 都转成了 double,结果错误。(本原因是网上看到的,未经验证,仅作参考)
然而,我的两个join表是前一天的数据和今天的数据进行join,也就是字段和类型一模一样,自然就不是上述的原因了。
2.复现
于是我将sql拿来,分别在hive和spark中执行了一下,果然,在hive中有结果在spark中是空的。于是我将所有参与join的字段先拿掉,发现有数据,加上某一个字段突然有没数据了,凭借着十足的运气迅速发现了可疑字段。
 于是我查询了几条数据,惊人的发现这个字段不简单,竟然隐藏这一个小空格在后面,这显然是数据处理没到位,连trim都不trim一下,就把数据弄进来了。于是,问题很容易就解决了,对该字段加trim后就可以了。
于是我查询了几条数据,惊人的发现这个字段不简单,竟然隐藏这一个小空格在后面,这显然是数据处理没到位,连trim都不trim一下,就把数据弄进来了。于是,问题很容易就解决了,对该字段加trim后就可以了。 加了trim之后,果然spark和hive跑出的结果一致了。
加了trim之后,果然spark和hive跑出的结果一致了。
3.究因
如果你以为以上问题就这么解决了,那也太不严谨了。为啥同样的sql,spark跑出的结果需要加trim去空格,而hive就不需要呢?难道是hive在进行sql处理的时候,会自动对字段前后的空格进行trim?显然不太可能。所以这背后肯定还有更大的瓜。
4.深挖
上面我们讲到了为啥hive和sparksql跑出的结果对不上号的问题,我讲到了是因为spark中读取到的两个表中,其中一个表的相同字段中有空格,另一个表没有。当然我们根据这个结论可以通过加trim来解决问题,但是如果到这里就结束了,显然有失风度,我们要透过现象看本质,为啥会一个有空格一个没有空格呢,空格从何而来?
1)带着这个问题,我首先分析了一下两个表,发现出问题的字段有个很迷人的数据类型 char(3),请记住它不是varchar(3),学过数据库的都知道char是定长存储,如果插入的长度小于定义长度都会用空格进行补充。 于是转机来了,可能是因为两表的字段类型不一样这个原因。
但紧接着被打脸,两个连接表的该字段都是char(3),但却一个表有空格,一个表没有空格。
2)于是带着满脸疑惑继续看,原来内表的数据是不带空格的,外表的数据是带空格的。难道是因为内外表的原因么,于是我创建了两个简单的测试表,一个内表一个外表。如下所示:
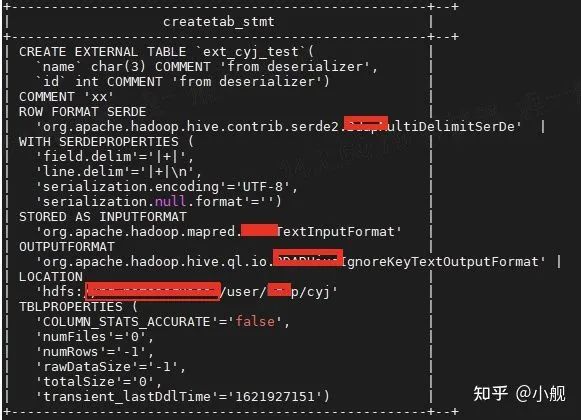
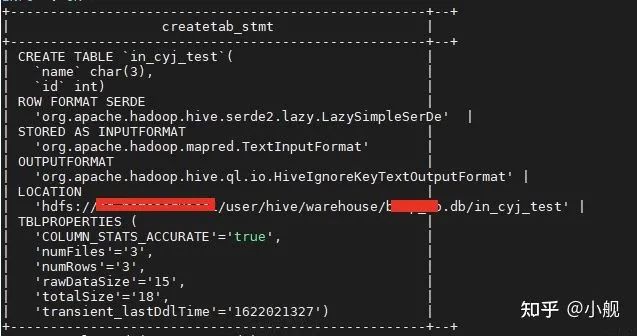 内表
内表然后我分别向两个表里插入数据:

复制
再然后进行查询
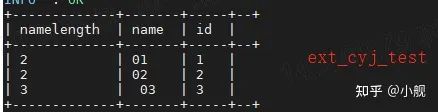
通过SPARK查询外表结果:
spark.sql("select length(name) nameLength, name,id from ext_cyj_test").show;

通过hive查询外表结果:
select length(name) nameLength, name,id from ext_cyj_test;
通过SPARK查询内表结果:
spark.sql("select length(name) nameLength, name,id from in_cyj_test").show;

通过Hive查询内表结果:
select length(name) nameLength, name,id from in_cyj_test
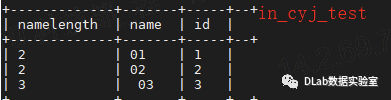
通过上述查询发现,记录(3,3),name字段前面有空格,无论是hive还是spark都没有trim掉;对于另外两条记录,无论字段后面有无空格,hive的查询结果都是无空格,spark的结果都是会填补空格。这个结果显然与我们的情况不符合。
5.黎明前的黑暗
突然间,我又灵机一动,貌似这两个表都是默认的TextInput格式存储,我们的内表用的是parquet存储啊。我仿佛抓住了最后一丝希望,以迅雷不及掩耳盗铃之势创建了一个parquet存储的内表。
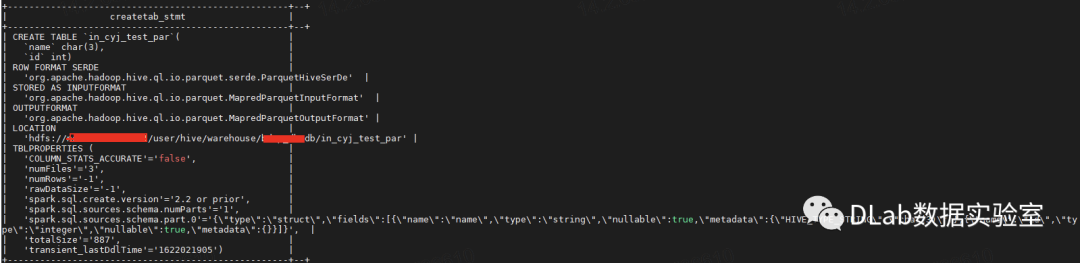
插入数据复制

6.真相大白
查询采用parquet存储的表
SPARK查询结果:
spark.sql("select length(name) nameLength, name,id from in_cyj_test_par").show;
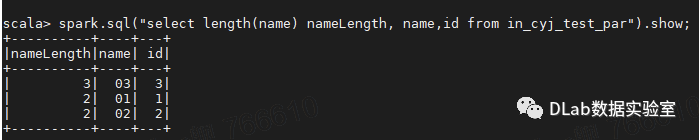
hive查询结果:
select length(name) nameLength, name,id from in_cyj_test_par;
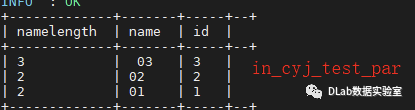
终于破案了,hive和spark查询出来的表竟然一致了,除了前面有空格的记录(03,3),另外两条一致了,说明最初的hive与sparksql结果对不上的问题终于复现了。
那这是什么原因呢?跟存储有关,于是我就去看这里面的猫腻,原来parquet支持的数据类型有限,都是最基本的数据类型,因此对于char/varchar等这种,他都会统一以parquet中定义的byte数组的类型进行存储,这样也就没有了char(3)插入两条数据还要再补占位符一说了。而TextInputFormat则可以支持,于是就造成了这样的结果--sparksql读取采用parquet存储的内表数据没有空格,采用textinput格式的内外表有空格,但对于hive来说,无论什么格式都不会有空格,因为hive会将空格给trim掉。但是的但是,如果字段的前面有空格,sparksql和hive是都不会给trim掉的哦~
7.结案
这个小小的bug经过了我的一顿骚操作变成了一件大案子,但是往往是这种会被轻易忽视的小问题会像蝴蝶效应一样造成很大的影响。一步步把他拆解开,让真相一步步水落石出,也是很有趣味性的~
