




5分钟内使用go对2张8000万表进行对比
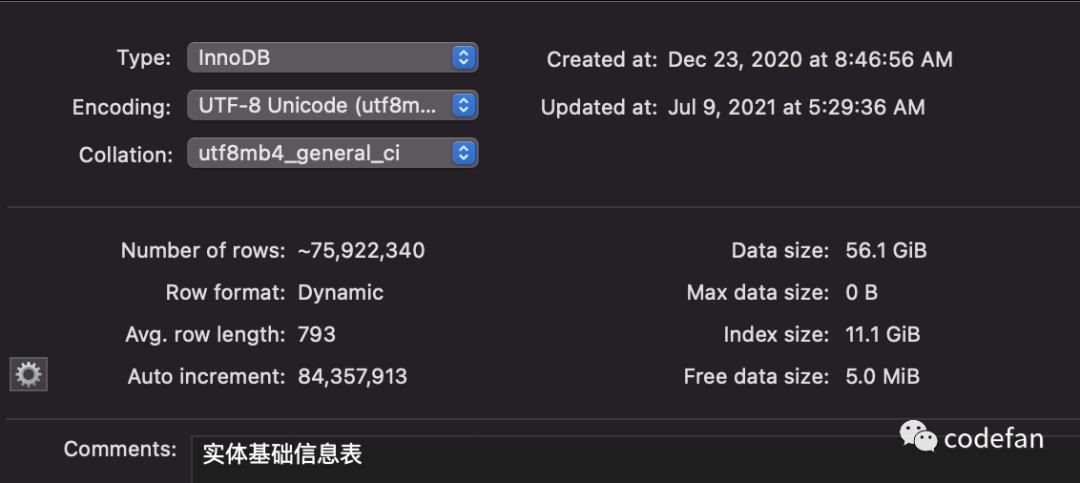
之前为了保证服务稳定,程序是运行在了预生产环境,更新以后将增量的数据发布到生产环境。今天这个例子,用到的表属于一张实体基本信息表,字段多,数据量大,大约在8000多万,数据56G,索引11G,之前分析过上游每天增量大约在几十万,每天上传还是挺快的。昨天上游修复上周反馈的bug,推送了2000多万的数据,早晨7点多看了下增量发布任务,没有执行完,看了下这个表的发布流程,一张全量表一张增量表,表结构完全一样。
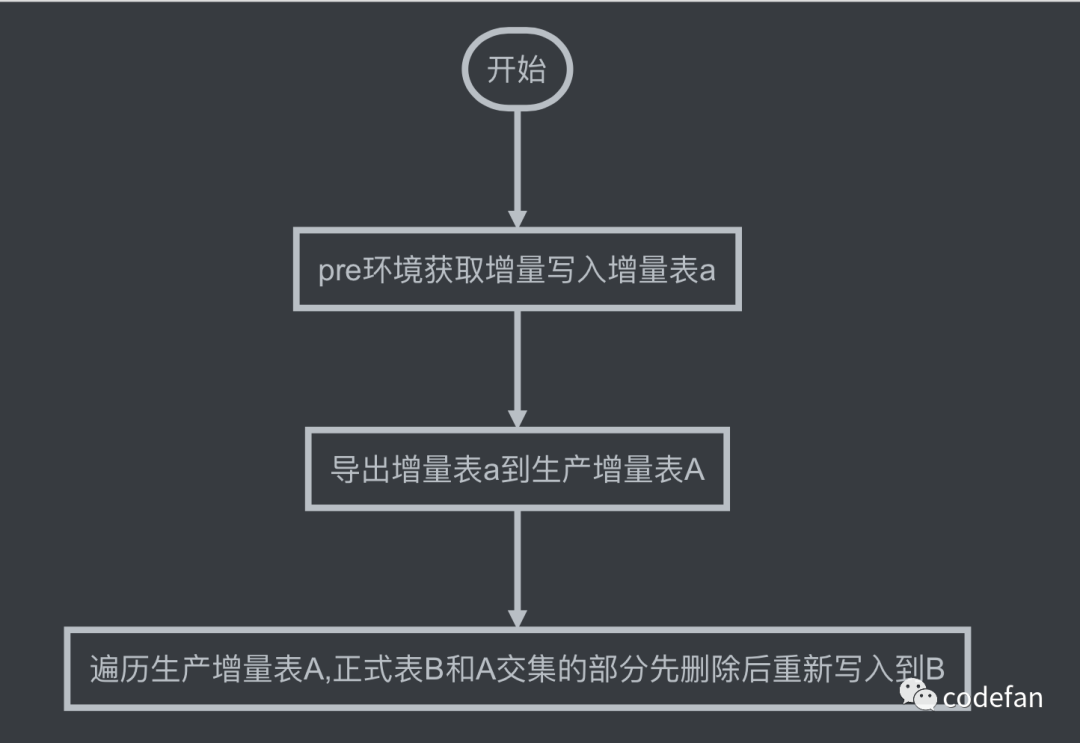
由于发布时间过久,避免上班后线上使用出问题,我在调度平台暂停了上传任务,注意此时其实已经有数据被删除,但是可能还没写入到正式表。所以需要赶紧将数据发布,重新用go写了上传脚本,多协程从增量表读取数据切分,按先删除后写入的操作完成导入。到公司后,心想还是做个数据检验,对比一下哪些数据在预生产有生产环境无。这个表唯一索引是entity_id,是业务主键,为什么不用主键自增id去做校验,涉及到业务曾用名处理问题,有可能会报索引冲突,线上的数据其实会比pre多,因为pre环境会因为曾用名表更的情况删除数据,这部分数据在上次上传到生产环境后不会被删除,因为其他表不会再使用到这部分id,所以同步pre删除的相当于不做处理。
如何对2张8000多万表做对比
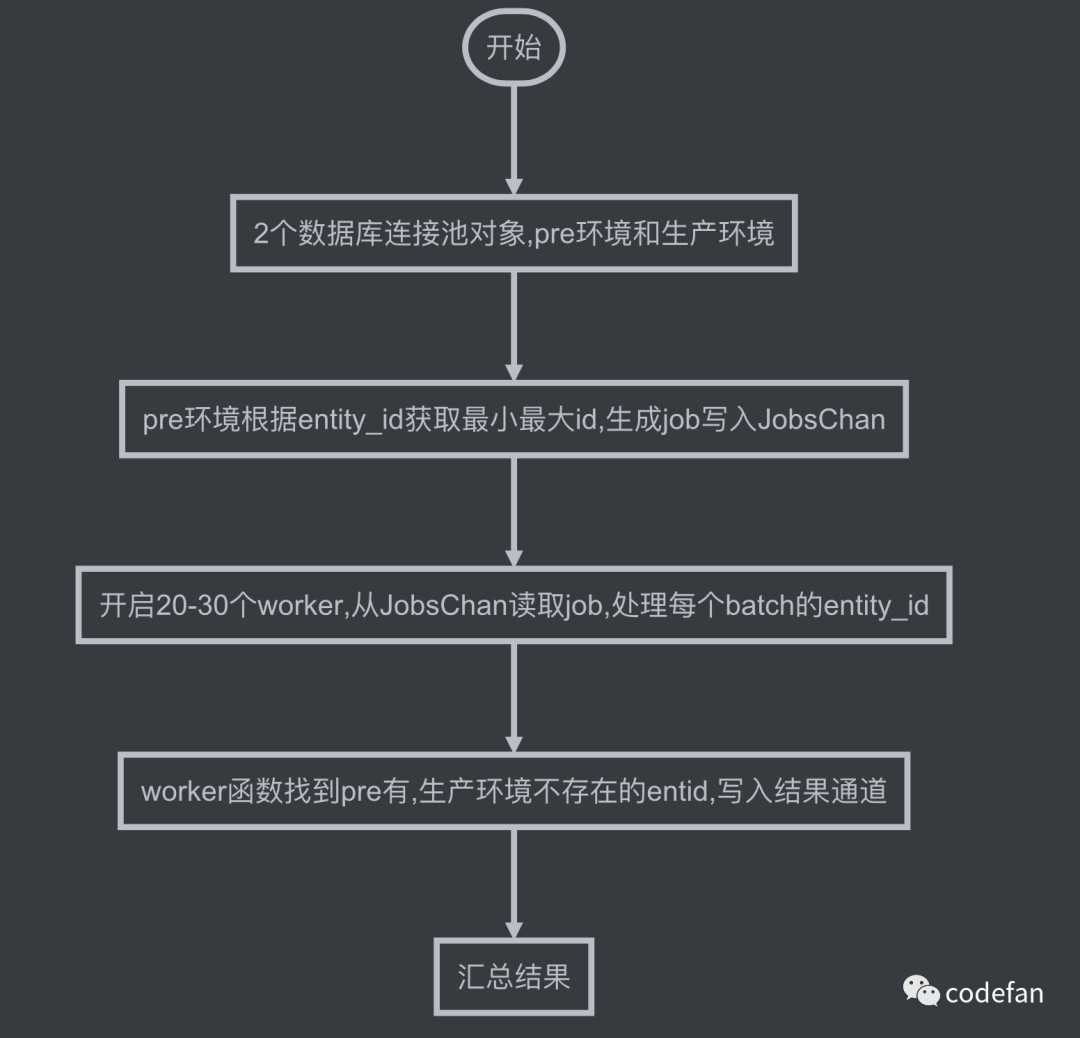
任务切分的时候做了特殊处理,entity_id因为业务问题,之前数据类型是int(11) 后数据源扩充到了上游全库,改成了bigint(20),因此这个字段数据是倾斜的,并非是自增连续的 处理方法如下
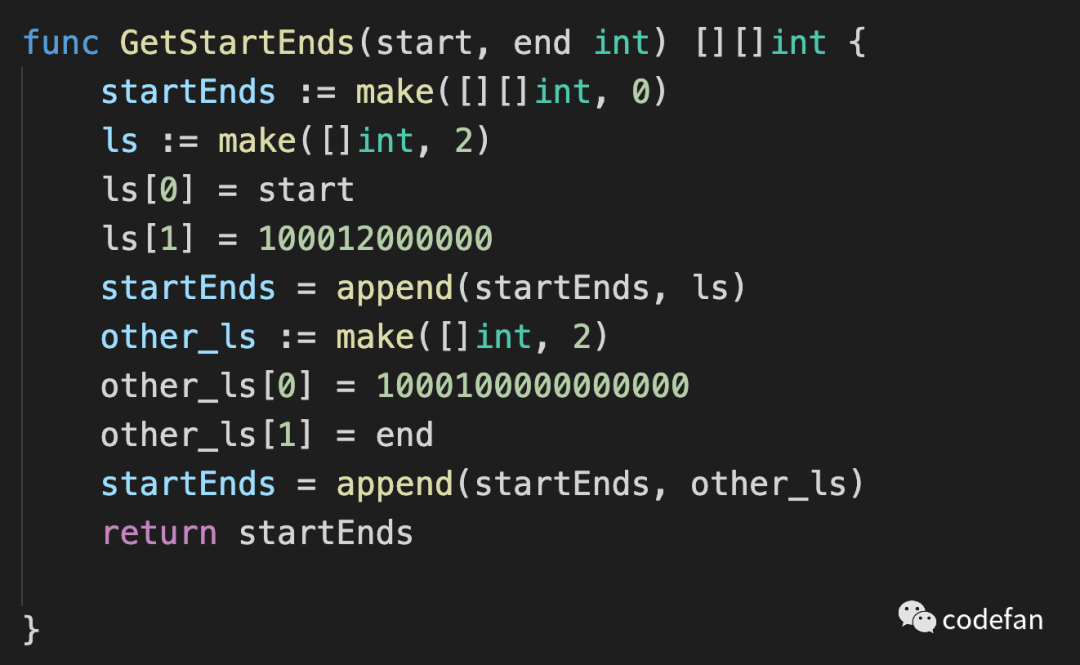
func GetStartEnds(start, end int) [][]int {
startEnds := make([][]int, 0)
ls := make([]int, 2)
ls[0] = start
ls[1] = 100012000000
startEnds = append(startEnds, ls)
other_ls := make([]int, 2)
other_ls[0] = 1000100000000000
other_ls[1] = end
startEnds = append(startEnds, other_ls)
return startEnds
}复制
初始化2个数据库连接池
func init(){
StartTime = time.Now()
DbName = "z_pe"
TableName = "base_entity_basic_info"
PK = "entity_id"
mc := &backends.MysqlConfig{
Host:HOST,
User:UserName,
Password:Password,
Db:DATABASE,
Port:PORT,
Charset:CHARSET,
}
mc.ConnUri = mc.GetConnUri()
mysql = backends.NewMysqlClient(mc)
pmc := &backends.MysqlConfig{
Host:PHOST,
User:PUserName,
Password:PPassword,
Db:DATABASE,
Port:PORT,
Charset:CHARSET,
}
pmc.ConnUri = pmc.GetConnUri()
pmysql = backends.NewMysqlClient(pmc)
}复制
分发任务 开启协程
start := mysql.GetMinId(DbName,TableName,PK)
end := mysql.GetMaxId(DbName,TableName,PK)
startEnds := GetStartEnds(start,end)
JobsChan := make(chan *Job,0)
ResultChan := make(chan *Result,0)
workerNum := 20
Batch := 10000
for i:=1;i<=workerNum;i++{
wg.Add(1)
go worker(i,JobsChan,ResultChan)
}
go func(){
for _, ls := range startEnds {
start, end := ls[0], ls[1]
log.Println("start,end ", start, end)
for start < end{
_end := start + Batch
if _end > end{
_end = end
}
p := make([]int,2)
p[0] = start
p[1] = _end
JobsChan <- &Job{Start:start,End:_end}
start = _end
}
}
close(JobsChan)
}()复制
worker函数 使用了wg(sync.WaitGroup) 当JobsChan关闭后wg.Done() 退出协程
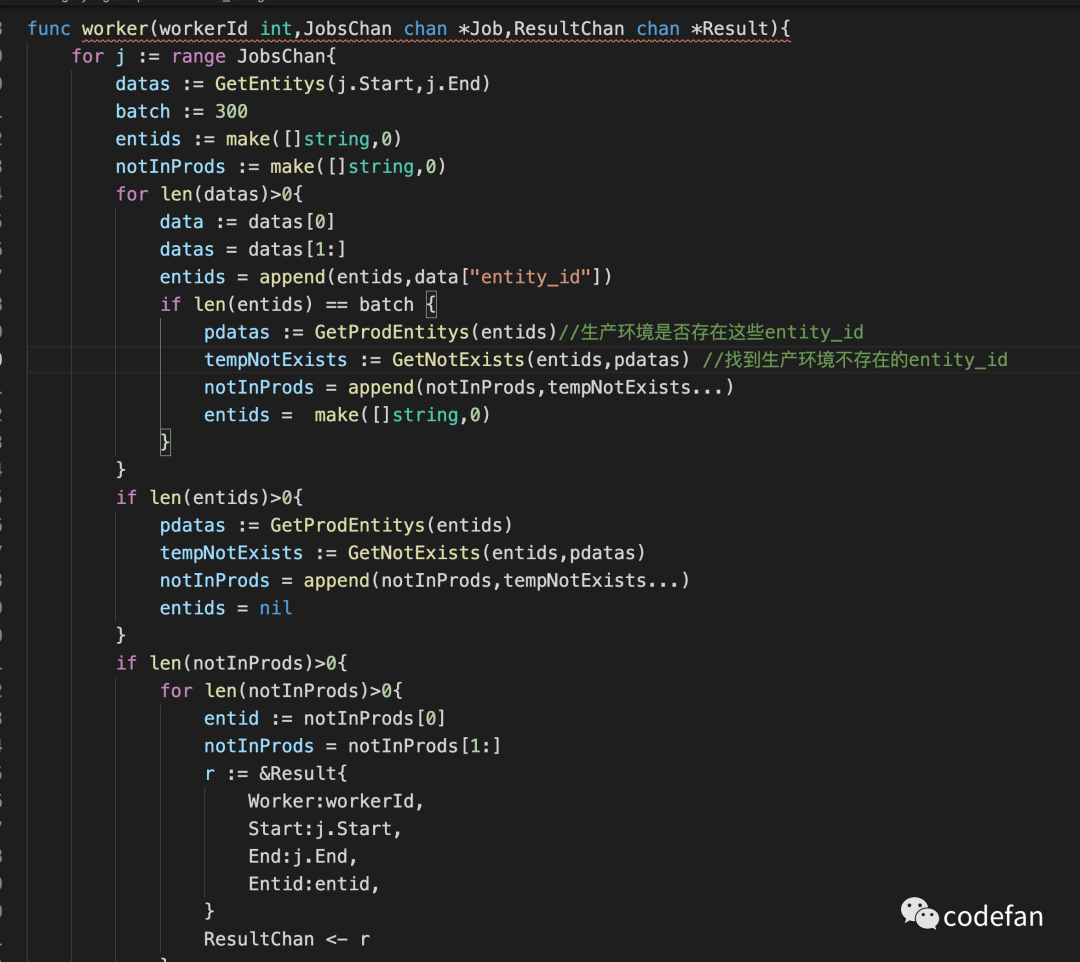
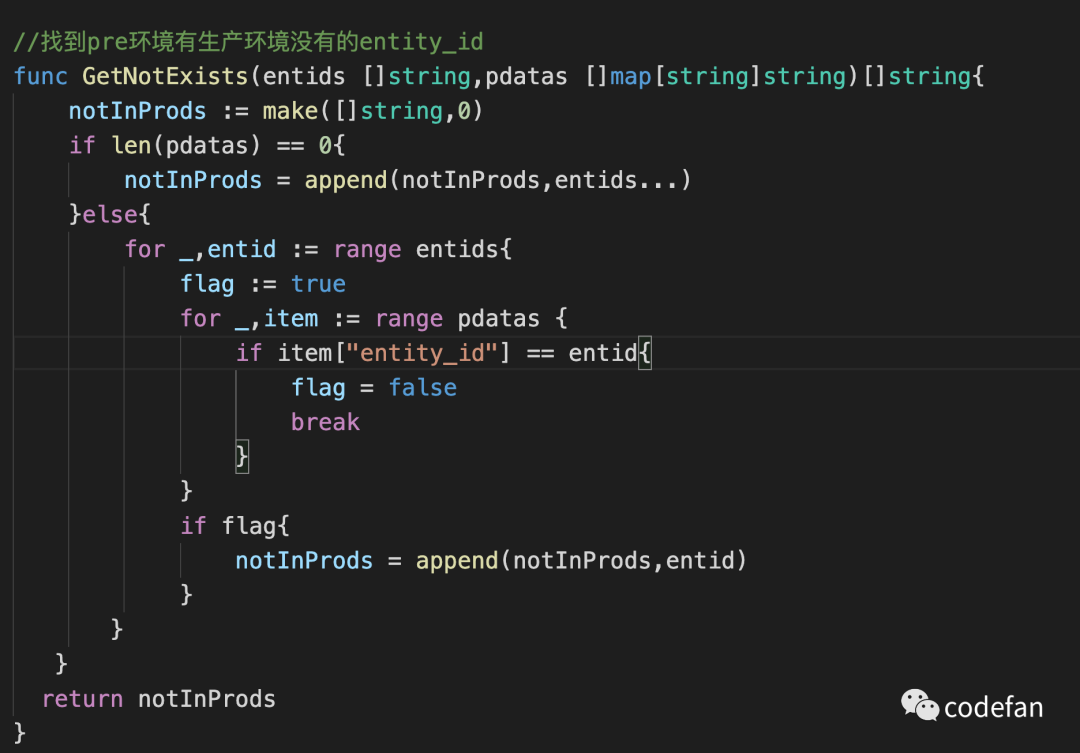
GetNotExists函数 找到pre环境有生产环境没有的entity_id
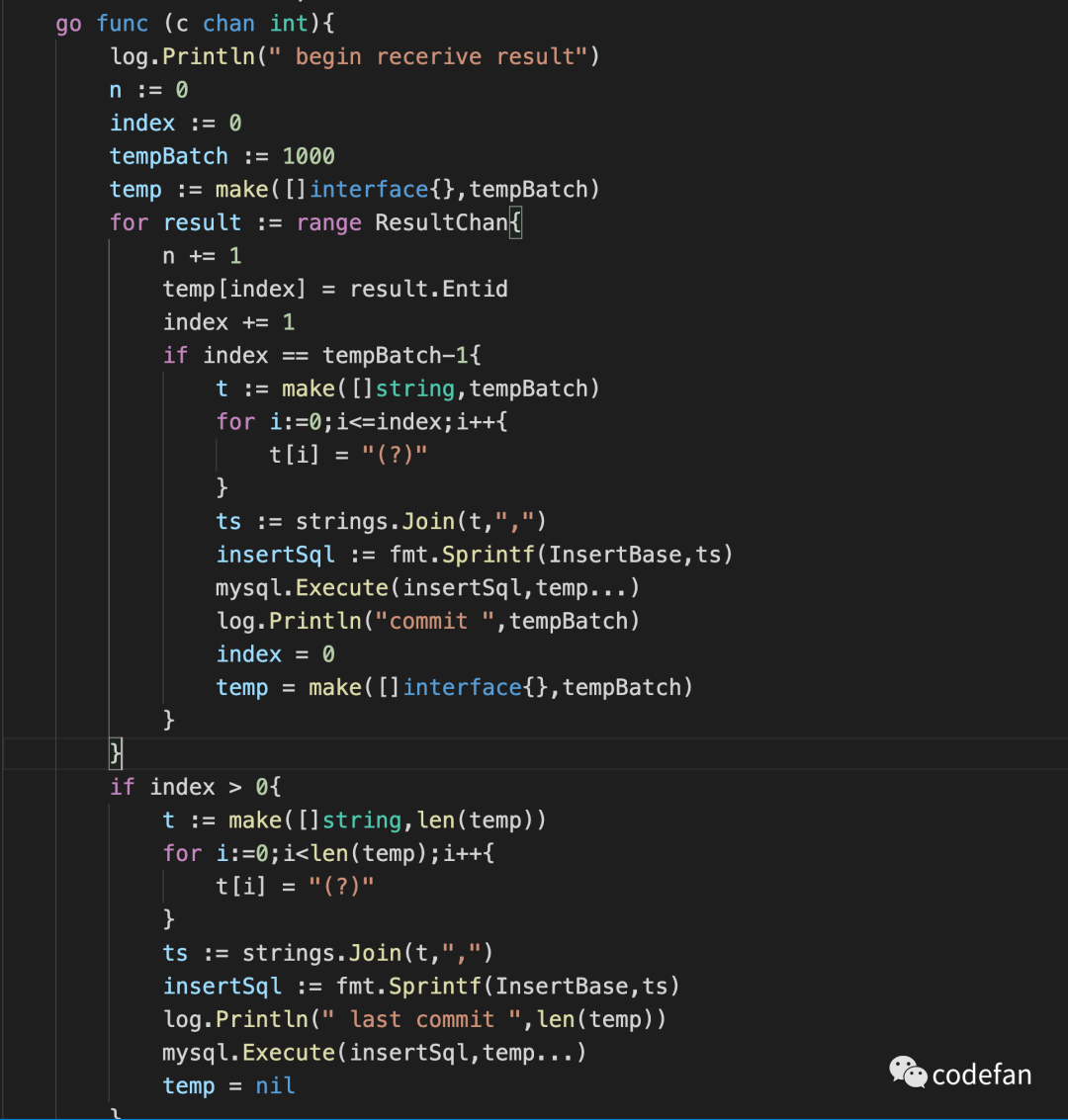
汇总结果 使用了单独的协程处理入库所以无需加锁
脚本发布到服务器跑一下结果,检测出2921条不存在生产环境,用时4m52s,查了下入库时间是今天pre环境通过binlog进来的数据明天自动发布,校验通过 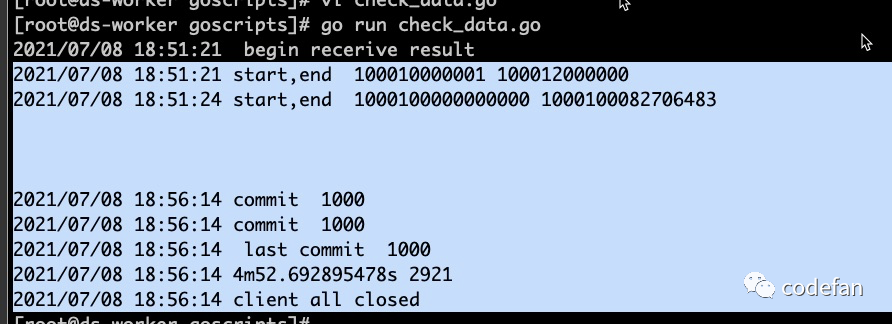
文章转载自codefan,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
2025年4月中国数据库流行度排行榜:OB高分复登顶,崖山稳驭撼十强
墨天轮编辑部
1532次阅读
2025-04-09 15:33:27
2025年3月国产数据库大事记
墨天轮编辑部
789次阅读
2025-04-03 15:21:16
2025年3月国产数据库中标情况一览:TDSQL大单622万、GaussDB大单581万……
通讯员
564次阅读
2025-04-10 15:35:48
征文大赛 |「码」上数据库—— KWDB 2025 创作者计划启动
KaiwuDB
479次阅读
2025-04-01 20:42:12
数据库,没有关税却有壁垒
多明戈教你玩狼人杀
442次阅读
2025-04-11 09:38:42
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
422次阅读
2025-04-14 09:40:20
最近我为什么不写评论国产数据库的文章了
白鳝的洞穴
344次阅读
2025-04-07 09:44:54
天津市政府数据库框采结果公布!
通讯员
327次阅读
2025-04-10 12:32:35
从HaloDB体验到国产数据库兼容性
多明戈教你玩狼人杀
282次阅读
2025-04-07 09:36:17
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
266次阅读
2025-04-17 17:02:24
