





通过我们前面对Calcite的介绍,我们知道Apache Calcite 是一个独立于存储与执行的SQL优化引擎,广泛应用于开源大数据计算引擎中,如Flink、Drill、Hive、Kylin等。Calcite的架构如图所示:
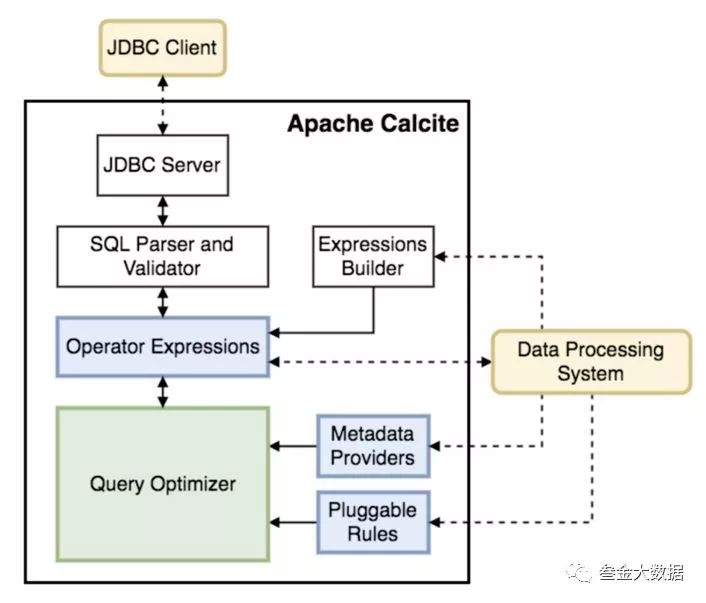
图中的Operator Expressions
指的就是关系表达式即查询计划,一个关系表达式在Calcite中被表示为RelNode
(Calcite介绍时代码中有提到过),往往以根节点代表整个查询树。从图中我们可以看到Operator Expressions
的来源有两处,分别时SQL Parser
和Expressions Builder
。
SQL Paser And Validator
Calcite自身提供了Parser用于SQL解析,是基于JavaCC实现的,直接使用Parser就能得到RelNode Tree。有兴趣的话可以看一下JavaCC相关的语法,在Calcite中Drop Table
的解析实现大概就是这样的:
1SqlDrop SqlDropTable(Span s, boolean replace) :
2{
3 SqlIdentifier name;
4 boolean ifExists = false;
5}
6{
7 <TABLE>
8 [
9 (<IF> <EXISTS>) { ifExists = true; }
10 ]
11 name = CompoundIdentifier()
12 {
13 return new SqlDropTable(s.end(name), name, ifExists);
14 }
15}复制
Expressions Builder
不同系统语法有差异,所以Parser也可能不同。针对这种情况,Calcite提供了Expressions Builder来对抽象语法树(或其他数据结构)进行转换得到RelNode Tree。如Hive(某一种Data Processing System)使用的就是这种方法。
Query Optimizer
终于到我们的重头戏了,Query Optimizer
根据优化规则(Pluggable Rules
)对Operator Expressions
进行一系列的等价转换,生成不同的执行计划,最后选择代价最小的执行计划,其中代价计算时会用到Metadata Providers
提供的统计信息。所以Query Optimizer
就是Calcite CBO的核心实现。
比如我们有这样一条SQL语句:
1INSERT INTO test_table
2SELECT t1.id, t1.name, t2.val
3FROM table1 as t1 INNER JOIN table2 AS t2
4ON t1.id = t2.id and t1.name = t2.name where t1.val > 5 and t2.val = 3;复制
通过Calcite生成的未经优化的RelNode树如下:
1LogicalTableModify(table=[[TEST_TABLE]], operation=[INSERT], flattened=[false])
2 LogicalProject(ID=[$0], NAME=[$1], VAL=[$7])
3 LogicalFilter(condition=[AND(>($2, 5), =($8, 3))])
4 LogicalJoin(condition=[AND(=($0, $5), =($1, $6))], joinType=[INNER])
5 LogicalTableScan(table=[[TABLE1]])
6 LogicalTableScan(table=[[TABLE2]])复制
结合我们前面提到的逻辑算子,可以发现最底层是TableScan,也是读取表的原始数据,紧接着是LogicalJoin,Joiner的类型为INNER JOIN, LogicalJoin之后接下做LogicalFilter 操作,对应SQL中的Where条件,最后做LogicalProject也就是投影操作。
根据我们前面了解的优化规则我们知道对于INNER JOIN
而言是可以进行谓词下推的,那么优化后的RelNode如下:
1LogicalTableModify(table=[[TEST_TABLE]], operation=[INSERT], flattened=[false])
2 LogicalProject(ID=[$0], NAME=[$1], VAL=[$5])
3 LogicalJoin(condition=[AND(=($0, $3), =($1, $4))], joinType=[inner])
4 LogicalFilter(condition=[=($2, 3)])
5 LogicalProject(ID=[$3], NAME=[$4], VAL=[$5])
6 LogicalTableScan(table=[[TABLE2]])
7 LogicalFilter(condition=[>($2,5)])
8 LogicalProject(ID=[$0], NAME=[$1], VAL=[$2])
9 LogicalTableScan(table=[[TABLE1]])复制
当然,上面的Logical Tree
只是简单的示例,由此也能看出Optimizer
主要目的就是减小SQL所处理的数据量、减少所消耗的资源并最大程度提高SQL执行效率。所使用的方法就是我们前面提到了SQL优化规则如:裁剪掉无用的列、合并投影、子查询转化成JOIN、JOIN重排序、下推投影、下推过滤等等。
总结一下,Calcite会将每一种操作(如LogicaJoin
、LocialFilter
、 LogicalProject
、LogicalScan
) 结合实际的Schema转化成具体的代价数,比较不同的执行计划所具有的代价,然后选择相对小计划作为最终的结果,之所以说相对小,这是因为如果要完全遍历计算所有可能的代价可能得不偿失,花费更多的人力与资源,因此只是说选择相对最优的执行计划。
CBO目的是“避免使用最差的执行计划,而不是找到最好的“
参考资料:
https://zhuanlan.zhihu.com/p/40478975
https://www.jianshu.com/p/2dfbd71b7f0f
扶我起来,我还能更新~

