





大数据环境下的数据存储方案和存储格式多种多样,开发人员和数据分析人员需要熟悉多种数据查询引擎,并且需要按照不同的方式及数据格式对数据进行处理才能得到最终的结果。
在这样的环境下,屏蔽底层存储及计算引擎对用户的影响,提供统一的查询语法,则变得尤为必要。用户无需关注数据的来源与数据格式,只需要关注查询本身即可。当然要想降低用户的使用门槛,当然是用用户比较熟悉的SQL查询方式最为简单。
本篇文章就调研了一些突出的跨数据源的查询工具,包括Presto、XQL/IQL、Moonbox、QuickSQL等。其中除了Presto其他工具都是基于Spark的实现,所以就不对Spark进行赘述,我们分别从SQL解析、项目架构、优缺点等方面依次对这些方案进行介绍。
Presto
架构:
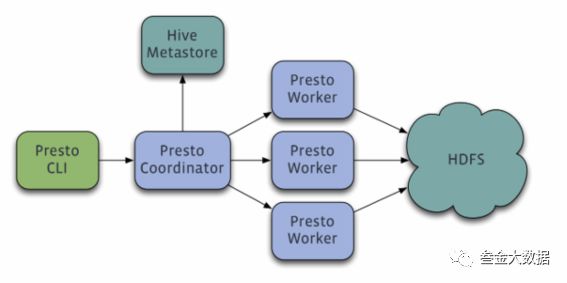
Presto查询引擎是一个Master-Slave的架构,由下面三部分组成:
一个Coordinator节点
一个Discovery Server节点
多个Worker节点
其中:
Coordinator: 负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行
Discovery Server: 通常内嵌于Coordinator节点中,提供Coordinator、Worker及Connection的服务发现功能
Worker节点: 负责实际执行查询任务,负责与HDFS交互读取数据
SQL解析:基于Antlr生成的SQL语法解析(Antlr是一个常用的语法解析器生成器(parser generator))
查询流程:
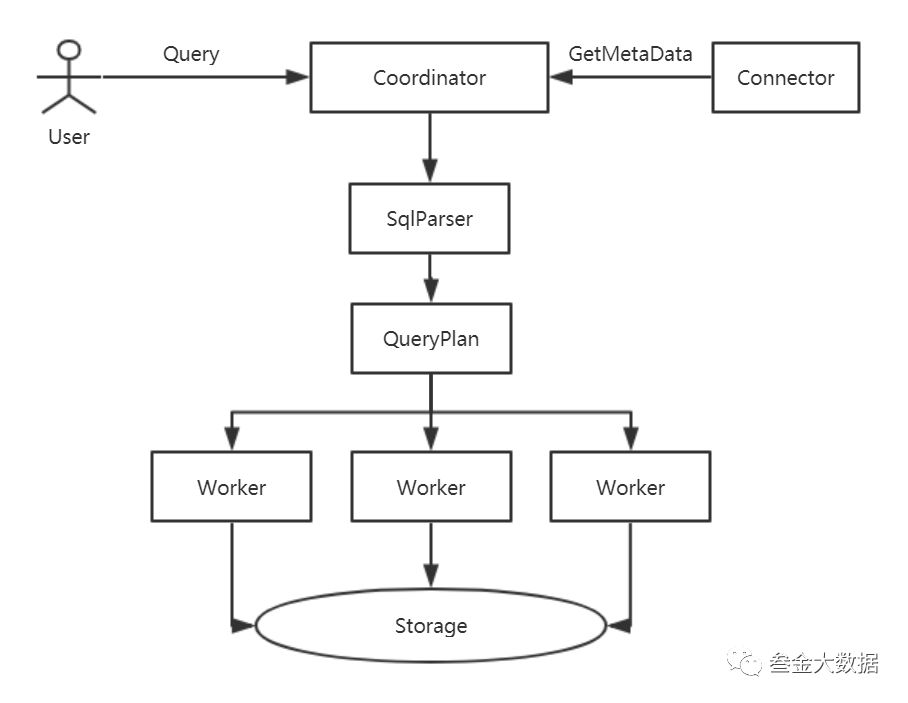
用户提交SQL查询语句
Coordinator收到查询请求后调用SqlParser解析SQL语句得到Statement对象
Presto对逻辑执行计划进行切分,将每一个SubPlan都会提交到一个或者多个Worker节点上执行
计算完成后通知Coordinator结束查询,并将数据发送给Coordinator
优缺点:
容错性差,当某个worker的查询失败后,整个query失效,没有重试机制。
纯内存计算,受到硬件的制约。当集群内存不够时Presto本身不会进行数据落盘,导致查询失败。
短板效应,MPP架构导致某一个worker性能缓慢则导致整个查询性能差。
单点问题,presto的coordinate和discovery server存在单点问题
元数据管理不友好
Github地址:https://github.com/prestodb/presto
XQL/IQL
XQL未开源,其架构及执行过程均由其文档得出。IQL可以看作XQL的一个简单实现版本。
架构:
SQL解析:基于Antlr生成的SQL语法解析
查询流程:
查询语法示例:

解析查询语句
根据元数据信息加载各个数据源的数据到DataFrame
最后对通过spark sql对DataFrames进行联合查询操作。
IQL github地址:https://github.com/teeyog/IQL
Moonbox
架构:
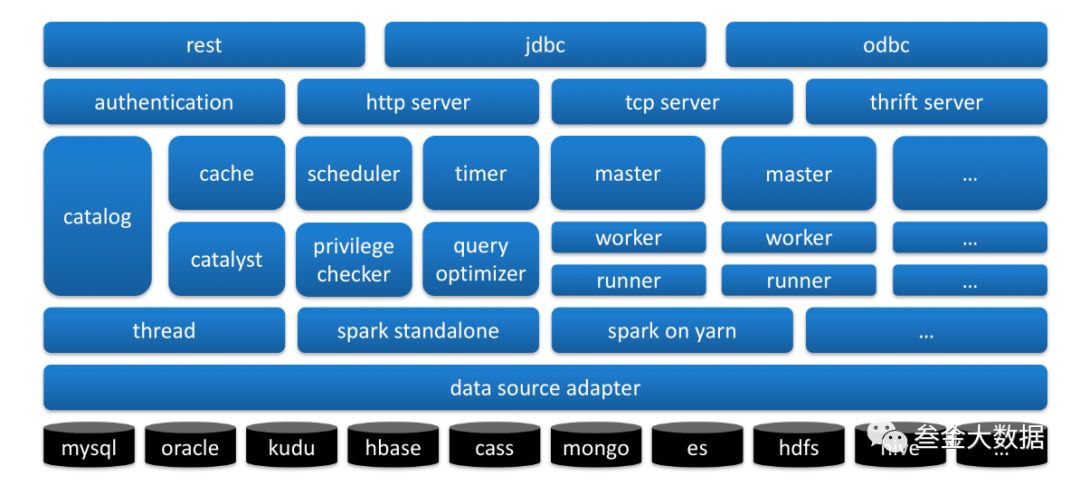
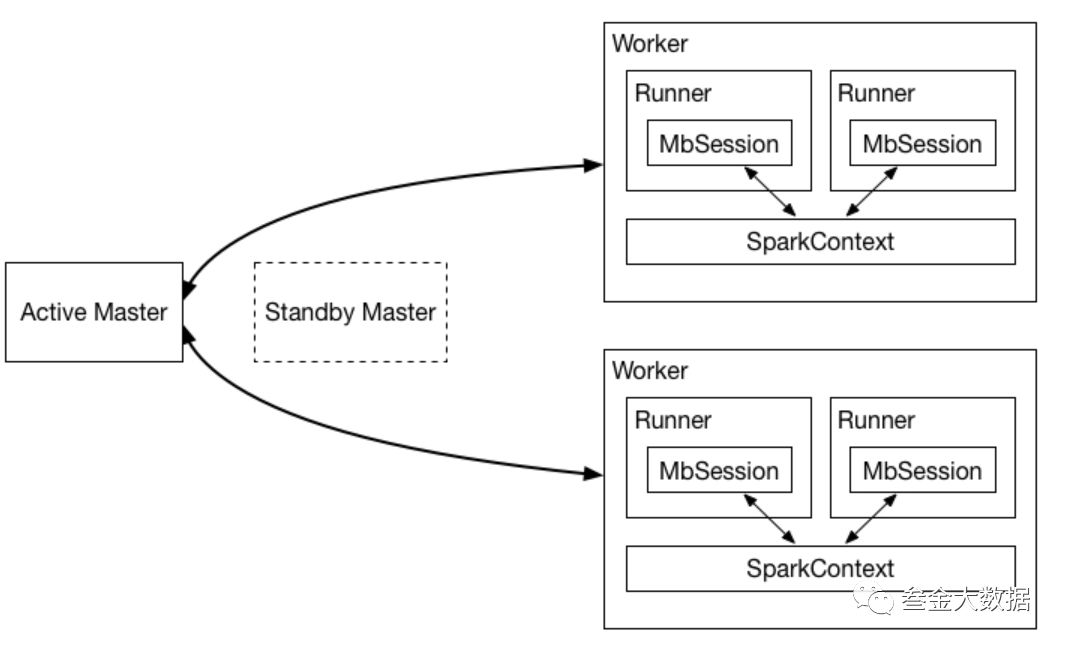
SQL解析:基于Antlr生成的SQL语法解析
查询流程:
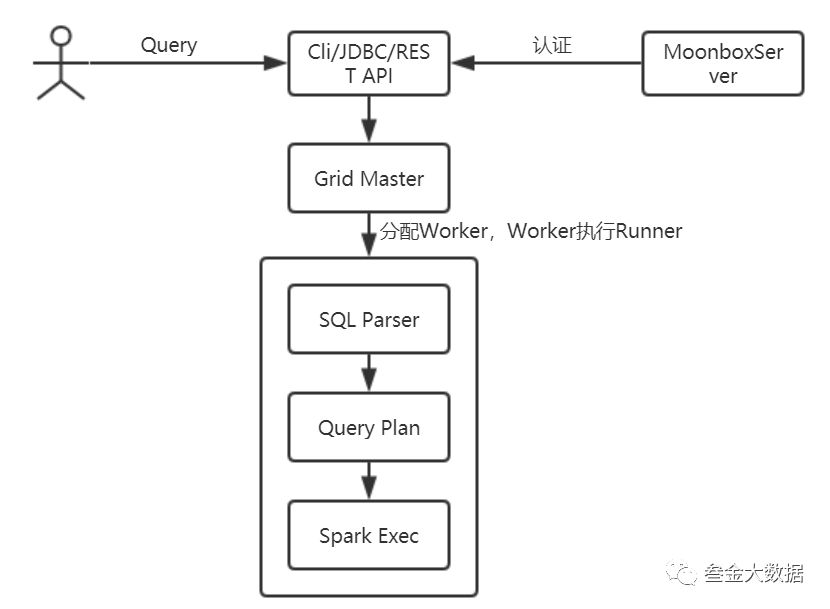
对SQL解析生成对各个数据源的查询计划
分别对各个数据源进行查询,得到对应的DataFrame
最后对DataFrames进行联合查询操作。
优点:
不维护元数据信息,则无元数据更新同步等问题
Github地址:https://github.com/edp963/moonbox
QuickSql
架构:
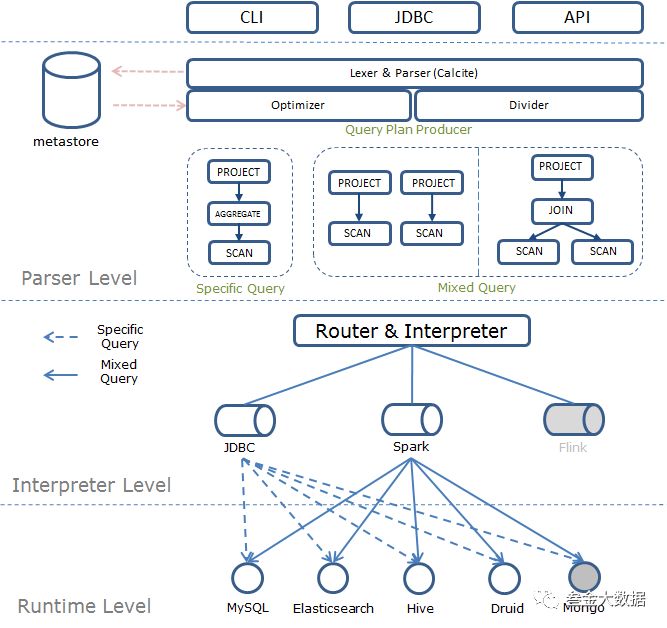
SQL解析:基于Apache Calcite进行SQL语法解析
查询流程:
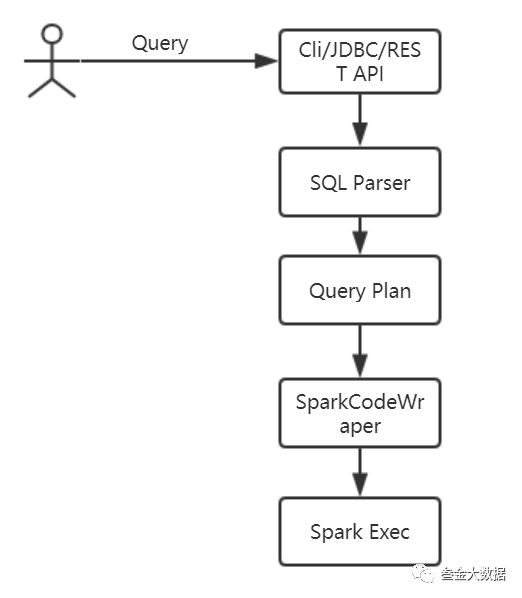
对用户输入的SQL通过Calcite进行解析优化
生成对各个数据源的查询计划
通过SparkCodeWrapper生成spark执行代码,提交到spark集群进行执行。代码中包括各个数据源的连接方式,查询语句等,查询出各个DataFrame
对DataFrames进行联合查询。
Github地址:https://github.com/Qihoo360/Quicksql
通过对以上的项目介绍,发现他们各有优劣,对于跨数据源的数据查询分析系统有了一个大致的了解,那么我们该从哪些角度思考设计一个跨数据源的数据查询系统就是接下来要思考的问题了。
扶我起来,我还能更新~

