作者 | teemohong(洪峰)
导读
SQL作为简单易用的数据开发利器,大家都会用。各类SQL虽然语法大同小异,但是其内部运行原理还是有很大区别。本文章给大家介绍的是Spark SQL及通用调优,这里Spark基础原理只做介绍,侧重点是在SQL调优部分。希望大家看后能够有所收益。
什么是SQL?Spark SQL?
结构化查询语言简称SQL,是一种数据库查询语言,
用于存取数据以及查询,更新和管理数据。
Spark SQL是spark套件中一个组件,
它将数据的计算任务通过SQL的形式转换成了RDD的计算,
类似于Hive通过SQL的形式将数据的计算任务转换成了MapReduce。复制
一.认识Spark SQL
大数据平台的FDW(分期乐数据仓库)、ETL使用的正是Spark SQL进行查询分析及逻辑处理。所以我们在了解Spark SQL调优前,有必要对大数据计算通用概念,Spark表的存储结构与设计、Spark SQL执行过程等有一个基本的了解。这样才能更好的进行SQL优化,写出既优美执行又快的SQL。
Hadoop与Spark
通常来说Hadoop是一整套大数据解决方案包括了存储(HDFS)、
计算(MapReduce)和资源调度管理(Yarn)。
Hive是Hadoop生态发展起来的一个数据仓库组件,
可以使用Hive SQL实现MR,并且将HDFS映射成表。
而Spark是基于内存计算的大数据并行计算框架。可以更快的实现数据计算。复制
1.1 为什么使用Spark SQL
快!基于内存分布式计算。按照官方说法Spark比Hadoop要快10-100倍。只要资源够多,集群够大,代码写的好,数据再多都不是事。
简单!其中Spark SQL提供标准SQL的支持,SQL简单易学,能够有效的覆盖大多数离线分析场景。
全!Spark有一套完整的生态体系包含Spark SQL、Spark Streaming,MLib,Graphx等,分别解决离线、实时、机器学习和图计算等使用场景。其中选择Spark SQL也是大数据平台使用的最多、最频繁。

图1.1.1 Spark与Hadoop对比
1.2 表的文件格式
大数据平台大部分离线数据是存储在Hive表上。
Hive表的文件格式非常多,常见的有:
TEXTFILE:默认格式,数据不做压缩,磁盘开销大,数据解析可以并行度读多个文件
SEQUENCEFILE:SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以的形式序列化到文件中
RCFILE:RCFILE是一种行列存储相结合的存储方式
ORCFILE:是对RCFILE的优化
大数据平台现在默认推荐使用的ORCFILE格式,这是由于ORC格式有以下特性:
1)每个task只输出单个文件,减少NameNode的负载
2)支持各种复杂数据类型
3)在文件中存储了轻量级索引
4)可以并行度读多个文件
5)基于数据类型的块模式压缩

1.3 非分区表和分区表
Spark中的表有两种创建方式,一种是加了分区字段的分区表,分区字段可以有多个,但是建议只使用一个(其实Hive表还可以进行分桶,进行更小粒度划分,但是由于大数据平台需要小文件合并,所以一般表是没有进行分桶的)。还有一种是默认的方式,没有分区字段。他们的存储结构下图:

图1.3.1 分区表
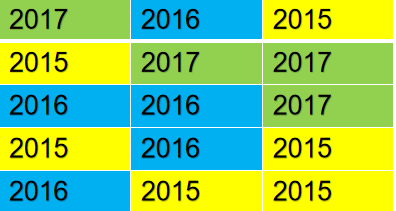
图1.3.2 非分区表
非分区表:适合需要全量更新的场景
分区表:适合按时间切片或增量更新的场景
分区表使用小技巧
通过我们对非分区表和分区表存储结构及特性的了解。
在使用分区表的时候请使用分区字段限制查询范围。
如果查询时间范围很大,请切成多个片分别计算再合并,或者使用存量+增量的方式进行更新。复制
1.4 Spark SQL执行步骤
绝大部分SQL,解析执行过程大致类似。通常是用户在客户端发送SQL请求,先判断游请求是否合法,包括权限检查等。然后SQL解析器对SQL进行语法语义解析,SQL优化器会生成最优执行计划。之后根据执行计划。
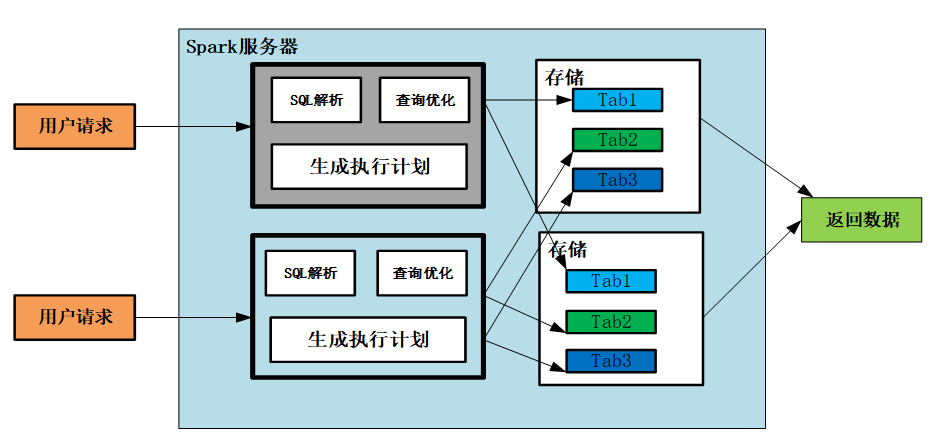
图1.4.1 SQL执行步骤示意图
查看执行计划
可以在FDW上使用explain sql语句查看Spark SQL执行计划。
SQL优化器会对执行计划进行一定优化。如谓词下推、列裁剪、常量替换、常量累加等。复制
1.5 Spark SQL执行顺序
要对SQL调优,肯定是要对SQL关键字执行顺序有所认识,这样便于我们更好的调整SQL。以下是一条SQL所有关键字执行顺序。
1.6 JOIN原理
SQL的所有操作,可以分为简单操作(如过滤where、限制次数limit等)和聚合操作(groupBy,join等),JOIN操作是最复杂、代价最大的操作类型。
当前SparkSQL支持三种Join算法-shuffle hash join、broadcast hash join以及sort merge join。其中前两者归根到底都属于hash join,只不过在hash join之前需要先shuffle还是先broadcast。详细可参考:https://www.jianshu.com/p/97e76dddcbfb
我们在实际应用中要尽可能避免大表和大表的join。
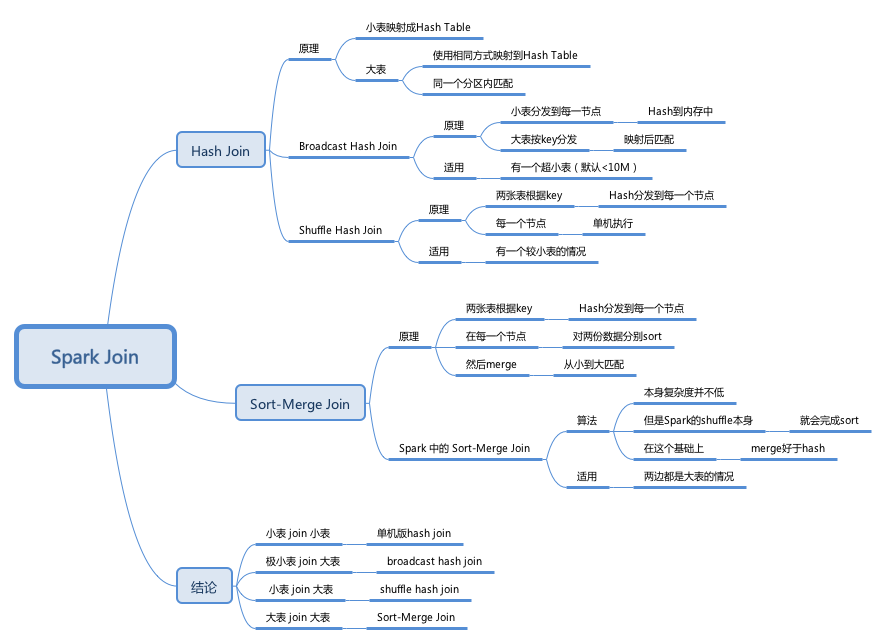
图1.6.1 Spark Join分类
二.Spark SQL优化
Spark SQL优化部分,我们将从大的优化原则、优化具体案例、资源调优等进行讨论。还会对常常遇到的数据倾斜进行探讨。
2.1 优化原则
结合笔者多年SQL优化经验,Spark SQL的优化主要是要做好以下几点:
1)明确需求
2)探索数据
3)良好代码习惯
4)裁剪数据
5)关注连接条件
6)善用分析函数
7)转变思维
8)了解SQL执行原理
第8条上面我们已经做了一定的探讨,接下来主要讨论前面7条。
2.1.1 明确需求
在写SQL或对SQL优化前,一定要明确需求,了解其意图。这样可以少走非常的多的弯路。如果在没有十分清楚需求前,如果是写SQL,二话不说就是干,最后虽然写出来,但是过于复杂,原本非常简单可以实现。如果需要优化别人的SQL,也需要了解需要优化的需求到底是想干什么。
2.1.2 探索数据
探索数据是一个非常好的习惯,有助于你对所统计的数据源有一个直接的认识。如拿到一个表,最先要了解基本数据字典,然后select一下,看看各个字段到底是什么东东。需要统计的连接条件是唯一,有没有空值,数据量级多大。另外表与表的对应关系,数据流统计表的记录情况,都是我们需要了解的。这些都会对我们优化SQL有比较好的指导意义。
2.1.3 良好的代码习惯
任何代码,都需要保持一个良好的编码习惯,SQL也一样。这样可以使SQL更易读、易维护。同样也使得SQL变得整洁、优美。
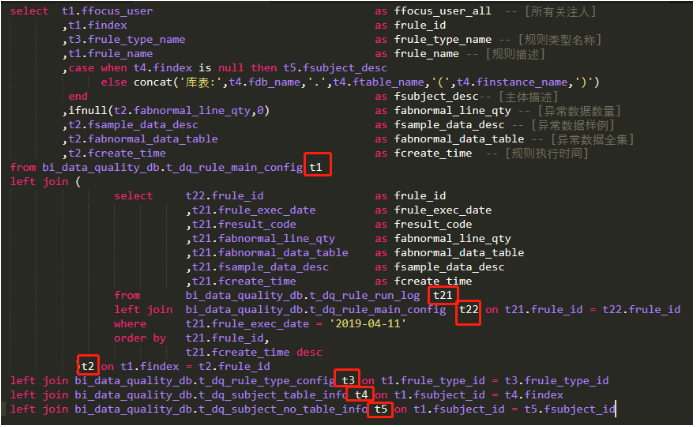
图2.1.4 一段规范的SQL
编码规范请参考:http://wiki.fenqile.com/pages/viewpage.action?pageId=44153158
2.1.4 裁剪数据
裁剪数据目的是为了减少数据量。包含列裁剪和行过滤。
列裁剪是指select部分尽可能只把需要的列写出来,不要什么都写*,这样Spark需要扫描读取更多的数据。
行过滤是指where部分,需要尽量缩小查询范围。
前面我们已知道join是代价最大的一种操作。如果涉及到多表join,一定是需要先过滤再join。不要吧过滤条件写到on上。
图2.1.4 裁剪数据
2.1.5 关注连接条件
SQL优化最难处理的就是Join操作了,谈到Join自然就要聊到on,也就是连接条件。很多新同学经常遇到的问题就是忘了写连接条件,连接条件写的不对,常常造成笛卡尔积、数据倾斜(后面会详细讨论)。这样跑了好久还不出来,关键如果sql很长,还不好看出来。
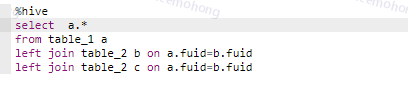
图2.1.5 连接条件有误
对于连接条件我们应该做到以下几点:
1)两个子表的连接条件,尽量要保证连接键在两个子表中是唯一的
2)连接键仅写等值连接,不要出现等值连接。如<>, like等。所有的不等值连接,都需要转换成等值连接。
3)尽量不要传递连接,所有子表都应该与主表连接。
2.1.6 善用分析函数
Spark Sql给我们提供了丰富的分析函数,这些函数可以让我们SQL做更多的事,而且是代码更加优雅,提高查询效率。
常用的分析函数:
RANK:值排名相同,其排名跳跃不连续
ROW_NUMBER:值排名,其排名连续不跳跃
DENSE_RANK:值排名相同,其排名不连续不跳跃
聚合函数:COUNT,SUM,MIN,MAX,AVG
Lag : 取前面的N行
Lead:取后面的N行
详细了解分析函数点击链接:https://blog.csdn.net/qq_34116784/article/details/89957804
小练习
有一场篮球赛,参赛双方是A队和B队,场边记录员记录下了每次得分的详细信息:
team:队名,number:球衣号,name:球员姓名,score_time:得分时间,score:当次得分
问(用sql表达):
1)输出每一次的比分的反超时刻,以及对应的完成反超的球员姓名
2)输出连续三次或以上得分的球员姓名,以及那一拨连续得分的数值复制
2.1.7 转变思维
比如遇到sql也写的最优了,似乎没什么可以优化了。但是sql就是跑不出。我的需求就是需要这么大的时间范围,几个月甚至几年;就是需要这么多的数据量几亿,几十亿。还要多表连接,怎么办?
这个时候需要我们转变思维。一个是业务的思维,一个是预计算+分层思想。
业务思维:
1)你真的理解清楚了需求吗?
2)一定需要这么久的时间范围?
3)一定需要这么多的数据量吗?
4)一定需要一次性计算吗?
预计算+分层思想:
1)增量+存量合并
2)分层预先计算数据中间表,逐层减少数据粒度与数据量级
2.2 数据倾斜
2.2.1 数据倾斜的表现
绝大多数task运行较快,但是个别task执行很慢。常常表现一个sql在以前运行是正常的,但是现在在FDW执行了很久,就是没有完成。查看yarn监控,有一个stage有200个task,199个task都完成了,唯有一个task一直在等待。
2.2.2 数据倾斜发生的原因
在进行shuffle的时候,必须将各个节点上相同的Key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或者join操作。如果某个key对应的数据量特别大的话,会发生数据倾斜。比如在统计订单表的时候某个业务分类特别大有1000万数据,而大部分分类只有1万条。
整个spark作业的运行进度是由运行时间最长的那个task决定的。因此出现数据倾斜的时候,spark作业看起来会运行得非常缓慢,甚至可能因为某个task处理的数据量过大导致OOM。
2.2.3 如何定位数据倾斜
如果表不多,可以查看各连接条件,在各个子表中的分布是否均匀,是否存在大量控制。
如果表多,可以利用yarn监控来定位。

第二步,查看记录数最大的记录数的task

第三步,点击SQL页面,鼠标放到正在运行的模块上,查看正在执行的sql段。
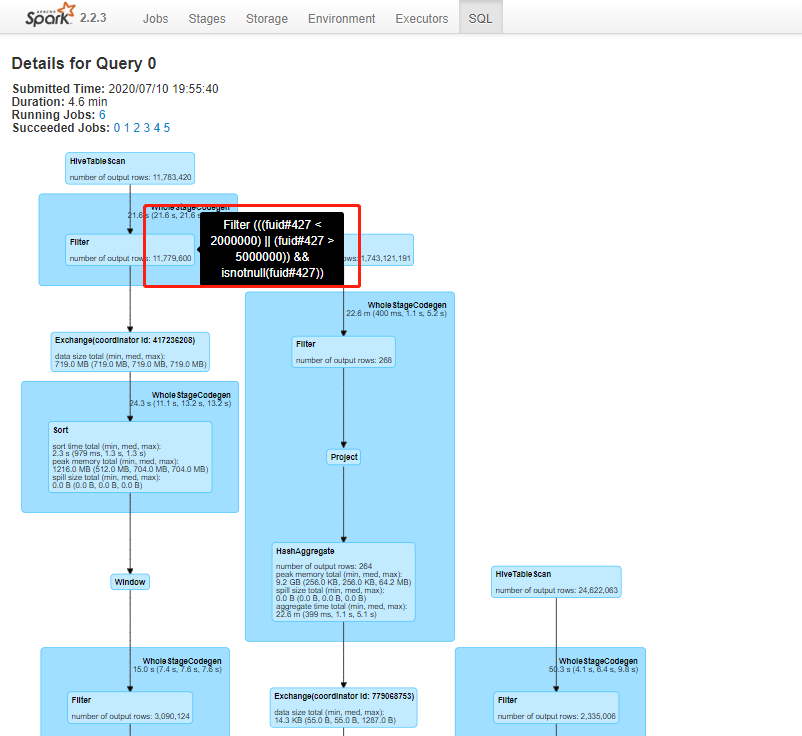
2.2.3 如何解决数据倾斜
1.使用Hive ETL(提取、转换和加载) 预处理数据 ;数据预先进行过聚合或者join操作;
2.过滤少数导致倾斜的key 。将key分布最大的部分,单独拿出来计算。再与其他key union起来;
3.提高shuffle操作的并行度。将参数spark.sql.shuffle.partitions调大,默认为200;
4.key随机分布。先给每个key都打上一个随机数,再聚合。
5.将reduce join 转为map join。不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类操作。
三.总结
在优化Spark SQL时,一定要结合Spark SQL底层基本原理及业务理解进行优化。同时也需要多写、多看积累丰富解决问题的经验和避坑的意识。实际工作中良好的SQL代码习惯是是写好Spark SQL的前提。
end

热门文章: