




本章目录:
0x02 Datax 实战使用
1.MySQL-To-HDFS
2.HDFS-To-MySQL
原文目录: https://www.bilibili.com/read/cv13760230
0x02 Datax 实战使用
1.MySQL-To-HDFS
环境&准备说明:描述: 为了快速搭建测试的数据库环境,本系列将采用docker容器
进行搭建部署,如没有安装docker 和 docker-compose
请参照本博客中的Docker系列课程。
(1) MySQL
# docker-compose.ymlversion: '3.1'services: db8: image: mysql container_name: mysql8.x command: --default-authentication-plugin=mysql_native_password restart: always environment: MYSQL_ROOT_PASSWORD: www.weiyigeek.top MYSQL_DATABASE: test MYSQL_USER: test MYSQL_PASSWORD: www.weiyigeek.top volumes: - "/app/mysql8:/var/lib/mysql" ports: - 3306:3306# 部署流程 #docker pull singularities/hadoopdocker-compose up -d# 创建测试表DROP TABLE IF EXISTS `user`;CREATE TABLE `user` ( `uid` int(0) NOT NULL AUTO_INCREMENT COMMENT '用户id', `name` varchar(32) CHARACTER SET utf8mb4 NOT NULL COMMENT '用户名称', `age` int(0) NOT NULL COMMENT '用户年龄', `hobby` varchar(255) CHARACTER SET utf8mb4 NOT NULL COMMENT '用户爱好', `operation_time` datetime(0) NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '插入时间', PRIMARY KEY (`uid`) USING BTREE) ENGINE = InnoDB AUTO_INCREMENT = 9 CHARACTER SET = utf8mb4 ROW_FORMAT = Dynamic;SET FOREIGN_KEY_CHECKS = 1;INSERT INTO `test`.`user`(`uid`, `name`, `age`, `hobby`, `operation_time`) VALUES (1, 'WeiyiGeek', 20, 'Network,Computer', '2021-10-12 14:34:03');INSERT INTO `test`.`user`(`uid`, `name`, `age`, `hobby`, `operation_time`) VALUES (2, 'Elastic', 18, '数据分析,数据采集,数据处理', '2021-10-12 17:16:34');INSERT INTO `test`.`user`(`uid`, `name`, `age`, `hobby`, `operation_time`) VALUES (3, 'Logstash', 20, '日志采集,日志过滤', '2021-10-12 17:16:59');INSERT INTO `test`.`user`(`uid`, `name`, `age`, `hobby`, `operation_time`) VALUES (4, 'Beats', 10, '通用日志采集', '2021-10-12 17:17:06');INSERT INTO `test`.`user`(`uid`, `name`, `age`, `hobby`, `operation_time`) VALUES (5, 'Kibana', 19, '数据分析,日志搜寻,日志数据展示,可视化', '2021-10-12 17:27:38');INSERT INTO `test`.`user`(`uid`, `name`, `age`, `hobby`, `operation_time`) VALUES (6, 'C', 25, '面向过程编程语言', '2021-10-13 02:43:30');INSERT INTO `test`.`user`(`uid`, `name`, `age`, `hobby`, `operation_time`) VALUES (7, 'C++', 25, '面向对象', '2021-10-13 10:44:59');INSERT INTO `test`.`user`(`uid`, `name`, `age`, `hobby`, `operation_time`) VALUES (8, 'Python', 26, '编程语言', '2021-10-13 10:48:45');# 此时test表中有如下数据。mysql> select * from test.user;+-----+-----------+-----+---------------------------------------+---------------------+| uid | name | age | hobby | operation_time |+-----+-----------+-----+---------------------------------------+---------------------+| 1 | WeiyiGeek | 20 | Network,Computer | 2021-10-12 14:34:03 || 2 | Elastic | 18 | 数据分析,数据采集,数据处理 | 2021-10-12 17:16:34 || 3 | Logstash | 20 | 日志采集,日志过滤 | 2021-10-12 17:16:59 || 4 | Beats | 10 | 通用日志采集 | 2021-10-12 17:17:06 || 5 | Kibana | 19 | 数据分析,日志搜寻,日志数据展示,可视化 | 2021-10-12 17:27:38 || 6 | C | 25 | 面向过程编程语言 | 2021-10-13 02:43:30 || 7 | C++ | 25 | 面向对象 | 2021-10-13 10:44:59 || 8 | Python | 26 | 编程语言 | 2021-10-13 10:48:45 |+-----+-----------+-----+---------------------------------------+---------------------+8 rows in set (0.04 sec)# 表中字段类型mysql> desc test.user;+----------------+--------------+------+-----+---------+-----------------------------+| Field | Type | Null | Key | Default | Extra |+----------------+--------------+------+-----+---------+-----------------------------+| uid | int | NO | PRI | NULL | auto_increment || name | varchar(32) | NO | | NULL | || age | int | NO | | NULL | || hobby | varchar(255) | NO | | NULL | || operation_time | datetime | YES | | NULL | on update CURRENT_TIMESTAMP |+----------------+--------------+------+-----+---------+-----------------------------+5 rows in set (0.04 sec)复制
(2) HDFSDocker HDFS镜像参考地址: https://registry.hub.docker.com/r/gradiant/hdfs
# hdfs-site 配置文件tee tmp/hdfs-site.xml <<'EOF'<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>dfs.namenode.name.dir</name><value>file:///hadoop/dfs/name</value></property><property><name>dfs.namenode.rpc-bind-host</name><value>0.0.0.0</value></property><property><name>dfs.namenode.servicerpc-bind-host</name><value>0.0.0.0</value></property><property><name>dfs.namenode.http-bind-host</name><value>0.0.0.0</value></property><property><name>dfs.namenode.https-bind-host</name><value>0.0.0.0</value></property><property><name>dfs.client.use.datanode.hostname</name><value>true</value></property><property><name>dfs.datanode.use.datanode.hostname</name><value>true</value></property><property><name>dfs.namenode.datanode.registration.ip-hostname-check</name><value>false</value></property><property><name>dfs.permissions.enabled</name><value>false</value></property></configuration>EOF# 部署流程 #docker pull gradiant/hdfs-namenodedocker pull gradiant/hdfs-datanodedocker run -d --name hdfs-namenode -v tmp/hdfs-site.xml:/opt/hadoop/etc/hadoop/hdfs-site.xml \ -p "8020:8020" \ -p "14000:14000" \ -p "50070:50070" \ -p "50075:50075" \ -p "10020:10020" \ -p "13562:13562" \ -p "19888:19888" gradiant/hdfs-namenode# 此处需要等待 hdfs-namenode 启动完毕后才执行如下命令docker run -d --link hdfs-namenode --name hdfs-datanode1 -e CORE_CONF_fs_defaultFS=hdfs://hdfs-namenode:8020 gradiant/hdfs-datanodedocker run -d --link hdfs-namenode --name hdfs-datanode2 -e CORE_CONF_fs_defaultFS=hdfs://hdfs-namenode:8020 gradiant/hdfs-datanodedocker run -d --link hdfs-namenode --name hdfs-datanode3 -e CORE_CONF_fs_defaultFS=hdfs://hdfs-namenode:8020 gradiant/hdfs-datanode# 测试:在 hdfs 中创建和列出示例文件夹docker exec -ti hdfs-namenode hadoop fs -mkdir hdfs # 在根目录下创建hdfs文件夹docker exec -ti hdfs-namenode hadoop fs -mkdir -p hdfs/d1/d2 # 创建多级目录docker exec -ti hdfs-namenode hadoop fs -ls # 列出根目录下的文件列表 # Found 1 items # drwxr-xr-x - hdfs supergroup 0 2021-10-27 08:42 hdfs# HDFS 常规命令帮助hadoop fs # 创建单级、多级目录hadoop fs -mkdir hdfshadoop fs -mkdir -p hdfs/d1/d2# 上传文件到HDFSecho "hello world" >> local.txt #创建文件hadoop fs -put local.txt hdfs/ #上传文件到hdfs# 下载hdfs文件hadoop fs -get hdfs/local.txt# 删除hdfs中的文件hadoop fs -rm hdfs/local.txt# 删除hdfs中的目录hadoop fs -rmdir hdfs/d1/d2复制
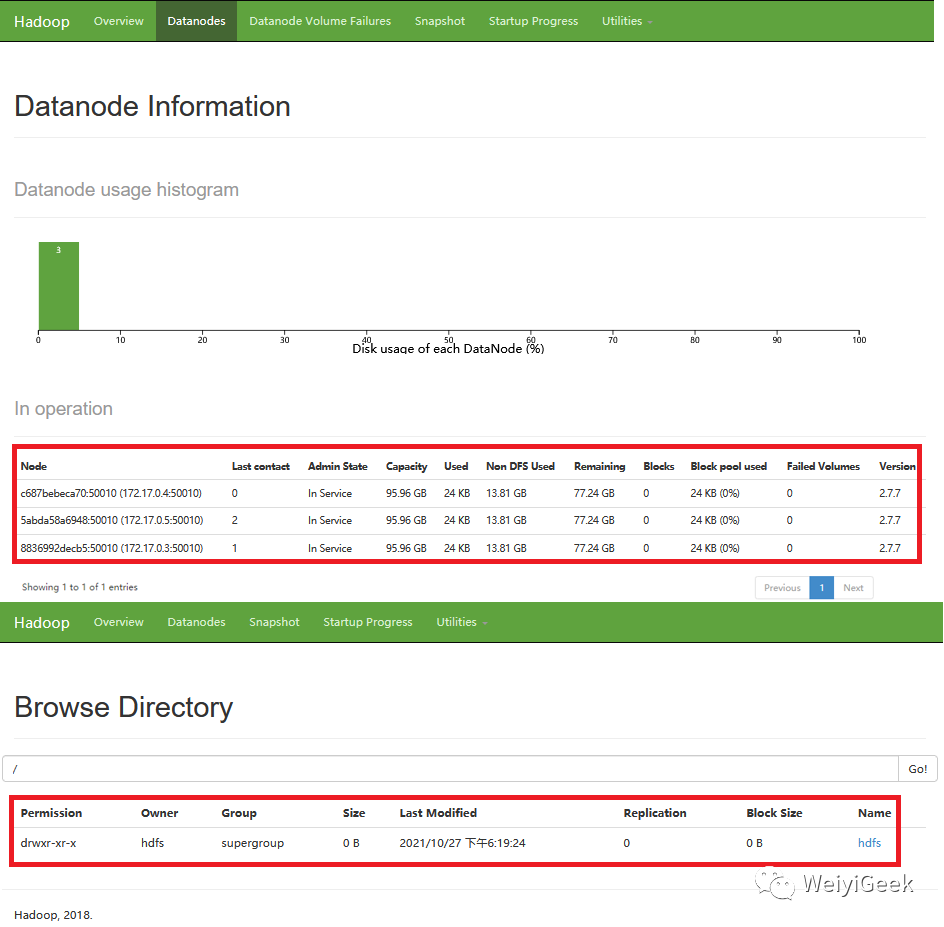
mysqlreader 快速使用说明与配置样例
(1) 关键参数&类型转换:
jdbcUrl: 描述的是到对端数据库的JDBC连接信息,使用JSON的数组描述,并支持一个库填写多个连接地址。username: 数据源的用户名password: 数据源指定用户名的密码table: 所选取的需要同步的表,支持多张表同时抽取,用户自己需保证多张表是同一schema结构.column: 所配置的表中需要同步的列名集合,用户使用*代表默认使用所有列配置,例如
['*']
一般不会采用此种方式。where: 筛选条件,MysqlReader根据指定的column、table、where条件拼接SQL,并根据这个SQL进行数据抽取,注意:不可以将where条件指定为limit 10,limit不是SQL的合法where子句。splitPk: 表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,使得提高数据同步的效能,目前splitPk仅支持整形数据切分,不支持浮点、字符串、日期等其他类型
querySql: 用户可自定义定义筛选SQL, 此参数会忽略 table、column 、where 选项,其优先级最高
MysqlReader针对Mysql类型转换列表: (注意除下述罗列字段类型外,其他类型均不支持。)
| DataX 内部类型 | Mysql 数据类型 |
|---|---|
| Long | int, tinyint, smallint, mediumint, int, bigint |
| Double | float, double, decimal |
| String | varchar, char, tinytext, text, mediumtext, longtext, year |
| Date | date, datetime, timestamp, time |
| Boolean | bit, bool |
| Bytes | tinyblob, mediumblob, blob, longblob, varbinary |
重点注意:
除上述罗列字段类型外,其他类型均不支持
。tinyint(1) DataX视作为整形
。year DataX视作为字符串类型bit DataX属于未定义行为
。
Tips : mysqlreader 插件默认不支持MySQL8.X由于其 jdbc_driver_class驱动名称"com.mysql.cj.jdbc.Driver"
(2) 配置样例(2.1) 配置一个从Mysql数据库同步抽取数据到本地的作业:
tee job/mysql2stream.json <<'EOF'{ "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "column": [ "uid", "name", "operation_time" ], "connection": [ { "jdbcUrl": ["jdbc:mysql://10.20.172.248:3305/test?useSSL=false&useUnicode=true&characterEncoding=UTF8&serverTimezone=Asia/Shanghai"], "table": ["user"] } ], "username": "test5", "password": "weiyigeek.top", "where": "uid > 0" } }, "writer": { "name": "streamwriter", "parameter": { "print": true, "encoding": "UTF-8" } } } ], "setting": { "speed": { "channel": "2" } } }}EOF复制
执行结果:
2021-10-26 21:43:04.419 [0-0-0-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select uid,name,operation_time from user where (uid > 0)] jdbcUrl:[jdbc:mysql://********&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].1 WeiyiGeek 2021-10-12 14:34:032 Elastic 2021-10-12 17:16:343 Logstash 2021-10-12 17:16:594 Beats 2021-10-12 17:17:065 Kibana 2021-10-12 17:27:386 C 2021-10-13 02:43:307 C++ 2021-10-13 10:44:598 Python 2021-10-13 10:48:45.....2021-10-26 21:43:04.497 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[103]ms2021-10-26 21:43:14.393 [job-0] INFO StandAloneJobContainerCommunicator - Total 8 records, 117 bytes | Speed 11B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%2021-10-26 21:43:14.394 [job-0] INFO JobContainer -任务启动时刻 : 2021-10-26 21:43:04任务结束时刻 : 2021-10-26 21:43:14任务总计耗时 : 10s任务平均流量 : 11B/s记录写入速度 : 0rec/s读出记录总数 : 8读写失败总数 : 0复制
(2.2) 配置一个自定义SQL的数据库同步任务到本地内容的作业:
cat job/mysql2stream1.json{ "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "connection": [ { "jdbcUrl": ["jdbc:mysql://10.20.172.248:3305/test?useSSL=false&useUnicode=true&characterEncoding=UTF8&serverTimezone=Asia/Shanghai"], "querySql": ["select uid,name,hobby,operation_time from user where (uid > 3);"], } ], "username": "test5", "password": "weiyigeek.top", } }, "writer": { "name": "streamwriter", "parameter": { "print": true, "encoding": "UTF-8" } } } ], "setting": { "speed": { "channel": "1" } } }}复制
执行结果:
# 执行SQL与Jdbc URL2021-10-26 21:50:58.904 [0-0-0-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select uid,name,hobby,operation_time from user where (uid > 3);] jdbcUrl:[jdbc:mysql://*******&rewriteBatchedStatements=true].# 打印查询到的数据到终端中 4 Beats 通用日志采集 2021-10-12 17:17:065 Kibana 数据分析,日志搜寻,日志数据展示,可视化 2021-10-12 17:27:386 C 面向过程编程语言 2021-10-13 02:43:307 C++ 面向对象 2021-10-13 10:44:598 Python 编程语言 2021-10-13 10:48:45# 任务执行结果统计2021-10-26 21:51:08.877 [job-0] INFO JobContainer -任务启动时刻 : 2021-10-26 21:50:58任务结束时刻 : 2021-10-26 21:51:08任务总计耗时 : 10s任务平均流量 : 10B/s记录写入速度 : 0rec/s读出记录总数 : 5读写失败总数 : 0复制
hdfswriter 快速使用说明与配置样例
(1) 关键参数&类型转换: HdfsWriter提供向HDFS文件系统指定路径中写入TEXTFile文件和ORCFile文件,文件内容可与hive中表关联。
defaultFS:Hadoop hdfs文件系统namenode节点地址。格式:hdfs://ip:端口fileType: 文件的类型,目前只支持用户配置为"text"(textfile文件格式)或"orc"(orc表示orcfile文件格式)。path: 存储到Hadoop hdfs文件系统的路径信息,HdfsWriter会根据并发配置在Path目录下写入多个文件fileName: HdfsWriter写入时的文件名,实际执行时会在该文件名后添加随机的后缀作为每个线程写入实际文件名。column: 写入数据的字段,不支持对部分列写入。为与hive中表关联,需要指定表中所有字段名和字段类型。writeMode: 写入前数据清理处理模式,append 写入前不做任何处理, onConflict,如果目录下有fileName前缀的文件,直接报错。fieldDelimiter: 写入时的字段分隔符,需要用户保证与创建的Hive表的字段分隔符一致,否则无法在Hive表中查到数据compress: 写入文件压缩类型,默认没有压缩。其中:text类型文件支持压缩类型有gzip、bzip2;orc类型文件支持的压缩类型有NONE、SNAPPY(需要用户安装SnappyCodec)。encoding: 写文件的编码配置, 默认值 utf-8 慎重修改。haveKerberos : 是否有Kerberos认证默认false,如果为True则配置项
kerberosKeytabFilePath,kerberosPrincipal
为必填。kerberosKeytabFilePath: Kerberos认证 keytab文件路径,绝对路径kerberosPrincipal: Kerberos认证Principal名,如xxxx/hadoopclient@xxx.xxxhadoopConfig: HadoopConfig 高级HA配置:
// 名称空间: testDfs"hadoopConfig":{ "dfs.nameservices": "testDfs", "dfs.ha.namenodes.testDfs": "namenode1,namenode2", "dfs.namenode.rpc-address.aliDfs.namenode1": "主机名:端口", "dfs.namenode.rpc-address.aliDfs.namenode2": "主机名:端口", "dfs.client.failover.proxy.provider.testDfs": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"}复制
HdfsWriter 针对 Hive 数据类型转换列表:
| DataX 内部类型 | HIVE 数据类型 |
|---|---|
| Long | TINYINT,SMALLINT,INT,BIGINT |
| Double | FLOAT,DOUBLE |
| String | STRING,VARCHAR,CHAR |
| Boolean | BOOLEAN |
| Date | DATE,TIMESTAMP |
(2) 配置样例(2.1) 从MySQL同步数据HDFS中实例演示:
// 示例生成bin/datax.py -r mysqlreader -w hdfswriter > mysql2hdfs.json// 最终示例tee job/mysql2hdfs3.json <<'EOF'{ "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "connection": [ { "jdbcUrl": ["jdbc:mysql://10.20.172.248:3305/test?useSSL=false&useUnicode=true&characterEncoding=UTF8&serverTimezone=Asia/Shanghai"], "querySql": ["select uid,name,hobby,operation_time from user where (uid > 3);"], } ], "username": "test5", "password": "weiyigeek.top", } }, "writer": { "name": "hdfswriter", "parameter": { "column": [ {"name":"uid","type":"Long"}, {"name":"name","type":"string"}, {"name":"hobby","type":"string"}, {"name":"operation_time","type":"Date"}, ], "compress": "gzip", "defaultFS": "hdfs://10.10.107.225:8020", "fieldDelimiter": "|", "fileName": "mysql-test-user", "fileType": "test", "path": "/hdfs", "writeMode": "append", "encoding": "UTF-8" } } } ], "setting": { "speed": { "channel": "1" } } }}EOF复制
执行结果:
/usr/local/datax# ./bin/datax.py job/mysql2hdfsjson# 插件加载2021-10-27 18:25:25.794 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do prepare work .2021-10-27 18:25:25.794 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] do prepare work .2021-10-27 18:25:25.853 [job-0] INFO HdfsWriter$Job - 由于您配置了writeMode append, 写入前不做清理工作, [/] 目录下写入相应文件名前缀 [mysql-test-user] 的文件# mysqlreader 开始执行SQL读取数据2021-10-27 18:25:25.895 [0-0-0-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql、# hdfswriter 准备将数据写入到临时目录和文件中2021-10-27 18:25:25.910 [0-0-0-writer] INFO HdfsWriter$Task - begin do write...2021-10-27 18:25:25.911 [0-0-0-writer] INFO HdfsWriter$Task - write to file : [hdfs://10.10.107.225:8020/__5a361c9b_5a1b_413f_aec9_d074058f0c82/mysql-test-user__f9ea0b07_9023_46f5_9f3a_dd42244bfdd8]# mysqlreader 读取完成2021-10-27 18:25:25.923 [0-0-0-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql# hdfswriter 将写入的临时文件进行重命名`mysql-test-user__f9ea0b07_9023_46f5_9f3a_dd42244bfdd8.gz`并删除临时目录和文件2021-10-27 18:25:35.885 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] do post work.2021-10-27 18:25:35.885 [job-0] INFO HdfsWriter$Job - start rename file [hdfs://10.10.107.225:8020/__5a361c9b_5a1b_413f_aec9_d074058f0c82/mysql-test-user__f9ea0b07_9023_46f5_9f3a_dd42244bfdd8.gz] to file [hdfs://10.10.107.225:8020/mysql-test-user__f9ea0b07_9023_46f5_9f3a_dd42244bfdd8.gz].2021-10-27 18:25:35.902 [job-0] INFO HdfsWriter$Job - finish rename file [hdfs://10.10.107.225:8020/__5a361c9b_5a1b_413f_aec9_d074058f0c82/mysql-test-user__f9ea0b07_9023_46f5_9f3a_dd42244bfdd8.gz] to file [hdfs://10.10.107.225:8020/mysql-test-user__f9ea0b07_9023_46f5_9f3a_dd42244bfdd8.gz].2021-10-27 18:25:35.902 [job-0] INFO HdfsWriter$Job - start delete tmp dir [hdfs://10.10.107.225:8020/__5a361c9b_5a1b_413f_aec9_d074058f0c82] .2021-10-27 18:25:35.911 [job-0] INFO HdfsWriter$Job - finish delete tmp dir [hdfs://10.10.107.225:8020/__5a361c9b_5a1b_413f_aec9_d074058f0c82] .2021-10-27 18:25:35.912 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.# 结果统计任务启动时刻 : 2021-10-27 18:25:24任务结束时刻 : 2021-10-27 18:25:36任务总计耗时 : 11s任务平均流量 : 6B/s记录写入速度 : 0rec/s读出记录总数 : 5读写失败总数 : 0# 从HDFS中读取插入的text数据$ docker inspect hdfs-datanode1 | grep '"IPAddress"' | head -n 1"IPAddress": "172.17.0.3",$ curl "http://172.17.0.3:50075/webhdfs/v1/mysql-test-user__7630c0e0_d169_43cf_a808_272ad7d907bc?op=OPEN&namenoderpcaddress=0f3e052efe21:8020&offset=0"4|Beats|通用日志采集5|Kibana|数据分析,日志搜寻,日志数据展示,可视化6|C|面向过程编程语言7|C++|面向对象8|Python|编程语言复制
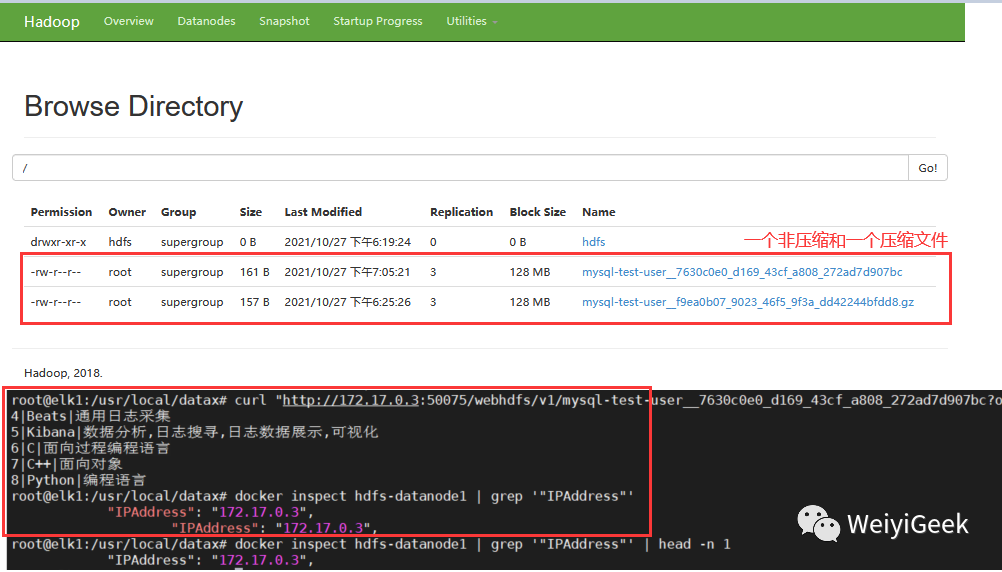
Tips : 总结Datax针对HDFS的写入流程,首先将数据写入到一个临时文件,如果全部成功则重命名(移动)
临时文件名、并删除临时目录。如果个别数据失败则Job任务失败,删除临时目录和临时文件。Tips : 从上面结果可以看出HDFS实际执行时会在该文件名后添加随机的后缀作为每个线程的实际写入文件名。
2.HDFS-To-MySQL
hdfsreader 快速使用说明与配置样例
(1) 快速介绍和参数说明HdfsReader支持的文件格式有
textfile(text)、orcfile(orc)、rcfile(rc)、sequence file(seq)和普通逻辑二维表(csv)
类型格式的文件,且文件内容存放的必须是一张逻辑意义上的二维表。
参数说明:
path: 要读取的文件路径,如果要读取多个文件,可以使用正则表达式"*",注意这里可以支持填写多个路径,比如需要读取表名叫mytable01下分区day为20150820这一天的所有数据,则配置如下:
"path": "/user/hive/warehouse/mytable01/20150820/*"
defaultFS: Hadoop hdfs文件系统namenode节点地址fileType: 文件的类型,目前只支持用户配置为"text"、"orc"、"rc"、"seq"、"csv"
column: 读取字段列表,type指定源数据的类型,index指定当前列来自于文本第几列(以0开始),value指定当前类型为常量,如{ "type": "long", "index": 0}, { "type": "string", "value": "alibaba"}
fieldDelimiter: 读取的字段分隔符encoding: 读取文件的编码配置nullFormat: 文本文件中无法使用标准字符串定义null(空指针),DataX提供nullFormat定义哪些字符串可以表示为null。haveKerberos:是否有Kerberos认证,默认false,例如如果用户配置true,则配置项kerberosKeytabFilePath,kerberosPrincipal为必填。kerberosKeytabFilePath: Kerberos认证 keytab文件路径,绝对路径kerberosPrincipal: Kerberos认证Principal名,如xxxx/hadoopclient@xxx.xxxcompress: 当fileType(文件类型)为csv下的文件压缩方式,目前仅支持 gzip、bz2、zip、lzo、lzo_deflate、hadoop-snappy、framing-snappy压缩;csvReaderConfig: 取CSV类型文件参数配置,Map类型。读取CSV类型文件使用的CsvReader进行读取,会有很多配置,不配置则使用默认值。
"csvReaderConfig":{ "safetySwitch": false, "skipEmptyRecords": false, "useTextQualifier": false}# 所有配置项及默认值,配置时 csvReaderConfig 的map中请严格按照以下字段名字进行配置:boolean caseSensitive = true;char textQualifier = 34;boolean trimWhitespace = true;boolean useTextQualifier = true;//是否使用csv转义字符char delimiter = 44;//分隔符char recordDelimiter = 0;char comment = 35;boolean useComments = false;int escapeMode = 1;boolean safetySwitch = true;//单列长度是否限制100000字符boolean skipEmptyRecords = true;//是否跳过空行boolean captureRawRecord = true;复制
HdfsReader提供了类型转换的建议表如下:
| DataX 内部类型 | Hive表 数据类型 |
|---|---|
| Long | TINYINT,SMALLINT,INT,BIGINT |
| Double | FLOAT,DOUBLE |
| String | String,CHAR,VARCHAR,STRUCT,MAP,ARRAY,UNION,BINARY |
| Boolean | BOOLEAN |
| Date | Date,TIMESTAMP |
其中:
Long是指Hdfs文件文本中使用整形的字符串表示形式,例如"123456789"。
Double是指Hdfs文件文本中使用Double的字符串表示形式,例如"3.1415"。
Boolean是指Hdfs文件文本中使用Boolean的字符串表示形式,例如"true"、"false"。不区分大小写。
Date是指Hdfs文件文本中使用Date的字符串表示形式,例如"2014-12-31"。
特别提醒:
Hive支持的数据类型TIMESTAMP可以精确到纳秒级别,所以textfile、orcfile中TIMESTAMP存放的数据类似于"2015-08-21 22:40:47.397898389",如果转换的类型配置为DataX的Date,转换之后会导致纳秒部分丢失,所以如果需要保留纳秒部分的数据,请配置转换类型为DataX的String类型。
Tips: 目前HdfsReader不支持对Hive元数据数据库进行访问查询,因此用户在进行类型转换的时候,必须指定数据类型,如果用户配置的column为"*",则所有column默认转换为string类型
。
mysqlwriter 快速使用说明与配置样例
(1) 描述: 我们使用 MysqlWriter 从数仓导入数据到 Mysql,同时 MysqlWriter 亦可以作为数据迁移工具为DBA等用户提供服务。
MysqlWriter 通过 DataX 框架获取 Reader 生成的协议数据,根据你配置的 writeMode 生成insert into...(当主键/唯一性索引冲突时会写不进去冲突的行)
或者replace into...(没有遇到主键/唯一性索引冲突时
,与 insert into 行为一致,冲突时会用新行替换原有行所有字段) 的语句写入数据到 Mysql。
MysqlWriter 可用参数:
jdbcUrl: 目的数据库的 JDBC 连接信息。username: 目的数据库的用户名。password: 目的数据库的密码。table: 目的表的表名称。
注意:table 和 jdbcUrl 必须包含在 connection 配置单元中
column: 目的表需要写入数据的字段,字段之间用英文逗号分隔。例如: "column": ["id","name","age"]。如果要依次写入全部列,使用*表示, 例如: "column":["*"]
。session: DataX在获取Mysql连接时,执行session指定的SQL语句,修改当前connection session属性。preSql: 写入数据到目的表前,会先执行这里的标准语句postSql: 写入数据到目的表后,会执行这里的标准语句。(原理同 preSql )writeMode: 控制写入数据到目标表采用 insert into 或者 replace into 或者 ON DUPLICATE KEY UPDATE 语句batchSize: 一次性批量提交的记录数大小,该值可以极大减少DataX与Mysql的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成DataX运行进程OOM情况。
MysqlWriter 针对 Mysql 类型转换列表: Long、Double、String、Date、Boolean、Bytes
与Mysqlreader插件是一致的。
配置示例演示
(1) 从HDFS同步数据到MySQL中实例演示:
# 操作重命名hadoop中指定文件名称/usr/local/datax# docker exec -it hdfs-namenode hadoop fs -mv mysql-test-user__7630c0e0_d169_43cf_a808_272ad7d907bc mysql-test-user.txt# 数据库表窗口mysql> CREATE TABLE IF NOT EXISTS test.hdfsreader like test.user;Query OK, 0 rows affected (0.48 sec)# 表结构mysql> DESC test.hdfsreader;+----------------+--------------+------+-----+---------+-----------------------------+| Field | Type | Null | Key | Default | Extra |+----------------+--------------+------+-----+---------+-----------------------------+| uid | int(11) | NO | PRI | NULL | auto_increment || name | varchar(32) | NO | | NULL | || hobby | varchar(255) | NO | | NULL | || operation_time | datetime | YES | | NULL | on update CURRENT_TIMESTAMP |+----------------+--------------+------+-----+---------+-----------------------------+4 rows in set (0.03 sec)# hdfsreader =>> mysqlwriter 示例文件生成$ bin/datax.py -r hdfsreader -w mysqlwriter# 最终的Job配置tee job/hdfs2mysql.json <<'EOF'{ "job": { "content": [ { "reader": { "name": "hdfsreader", "parameter": { "column": [ {"index":1,"type":"string"}, {"index":2,"type":"string"} ], "defaultFS": "hdfs://10.10.107.225:8020", "encoding": "UTF-8", "fieldDelimiter": "|", "fileType": "text", "path": "/mysql-test-user.txt" } }, "writer": { "name": "mysqlwriter", "parameter": { "column": [ "name", "hobby" ], "connection": [ { "jdbcUrl": "jdbc:mysql://10.20.172.248:3305/test?useSSL=false&useUnicode=true&characterEncoding=UTF8&serverTimezone=Asia/Shanghai", "table": ["hdfsreader"] } ], "username": "test5", "password": "weiyigeek.top", "writeMode": "insert" } } } ], "setting": { "speed": { "channel": "1" } } }}EOF复制
执行结果:
$ bin/datax.py job/hdfs2mysql.json# - 获取的列2021-10-27 23:20:44.255 [job-0] INFO OriginalConfPretreatmentUtil - table:[hdfsreader] all columns:[uid,name,hobby,operation_time].# - SQL语句生成2021-10-27 23:20:44.277 [job-0] INFO OriginalConfPretreatmentUtil - Write data [insert INTO %s (name,hobby) VALUES(?,?)], which jdbcUrl like:[jdbc:mysql://10.20.172.248:3305/test?useSSL=false&useUnicode=true&characterEncoding=UTF8&serverTimezone=Asia/Shanghai&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true]# - 读取HDFS中指定的mysql-test-user.txt文件2021-10-27 23:20:44.763 [job-0] INFO HdfsReader$Job - [hdfs://10.10.107.225:8020/mysql-test-user.txt]是[text]类型的文件, 将该文件加入source files列表2021-10-27 23:20:44.764 [job-0] INFO HdfsReader$Job - 您即将读取的文件数为: [1], 列表为: [hdfs://10.10.107.225:8020/mysql-test-user.txt]# - 读取开始2021-10-27 23:20:44.818 [0-0-0-reader] INFO Reader$Task - read start2021-10-27 23:20:44.818 [0-0-0-reader] INFO Reader$Task - reading file : [hdfs://10.10.107.225:8020/mysql-test-user.txt]2021-10-27 23:20:44.833 [0-0-0-reader] INFO UnstructuredStorageReaderUtil - CsvReader使用默认值[{"captureRawRecord":true,"columnCount":0,"comment":"#","currentRecord":-1,"delimiter":"|","escapeMode":1,"headerCount":0,"rawRecord":"","recordDelimiter":"\u0000","safetySwitch":false,"skipEmptyRecords":true,"textQualifier":"\"","trimWhitespace":true,"useComments":false,"useTextQualifier":true,"values":[]}],csvReaderConfig值为[null]2021-10-27 23:20:44.836 [0-0-0-reader] INFO Reader$Task - end read source files...# - 执行结果任务启动时刻 : 2021-10-27 23:20:43任务结束时刻 : 2021-10-27 23:20:54任务总计耗时 : 10s任务平均流量 : 6B/s记录写入速度 : 0rec/s读出记录总数 : 5读写失败总数 : 0# - 查看写入表的数据。mysql> select * from test.hdfsreader;+-----+--------+---------------------------------------+----------------+| uid | name | hobby | operation_time |+-----+--------+---------------------------------------+----------------+| 1 | Beats | 通用日志采集 | NULL || 2 | Kibana | 数据分析,日志搜寻,日志数据展示,可视化 | NULL || 3 | C | 面向过程编程语言 | NULL || 4 | C++ | 面向对象 | NULL || 5 | Python | 编程语言 | NULL |+-----+--------+---------------------------------------+----------------+5 rows in set (0.04 sec)复制
(2) 从MySQL中读取并写入到指定表之中。
# 表示创建create TABLE if not EXISTS mysqlwriter LIKE hdfsreader;# 示例生成bin/datax.py -r mysqlreader -w mysqlwriter# job任务配置 tee job/mysql2mysql.json <<'EOF'{ "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "connection": [ { "jdbcUrl": ["jdbc:mysql://10.20.172.248:3305/test?useSSL=false&useUnicode=true&characterEncoding=UTF8&serverTimezone=Asia/Shanghai"], "querySql": ["select name,hobby,operation_time from user where (uid > 5);"], } ], "username": "test5", "password": "weiyigeek.top", } }, "writer": { "name": "mysqlwriter", "parameter": { "column": [ "name", "hobby", "operation_time" ], "connection": [ { "jdbcUrl": "jdbc:mysql://10.20.172.248:3305/test?useSSL=false&useUnicode=true&characterEncoding=UTF8&serverTimezone=Asia/Shanghai", "table": ["mysqlwriter"] } ], "session": [ "set session sql_mode='ANSI'" ], "preSql": [ "delete from mysqlwriter" ], "username": "test5", "password": "weiyigeek.top", "writeMode": "insert" } } } ], "setting": { "speed": { "channel": "1" } } }}EOF复制
执行结果:
# -MysqlWriter 写入的字段以及SQL2021-10-28 09:57:05.554 [job-0] INFO OriginalConfPretreatmentUtil - table:[mysqlwriter] all columns:[uid,name,hobby,operation_time].2021-10-28 09:57:05.582 [job-0] INFO OriginalConfPretreatmentUtil - Write data [insert INTO %s (name,hobby,operation_time) VALUES(?,?,?)], which jdbcUrl like:[jdbc:mysql://10.20.172.248:3305/test?useSSL=false&useUnicode=true&characterEncoding=UTF8&serverTimezone=Asia/Shanghai&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true]# -写入前的SQL执行处理2021-10-28 09:57:05.628 [job-0] INFO CommonRdbmsWriter$Job - Begin to execute preSqls:[delete from mysqlwriter]. context info:jdbc:mysql://10.20.172.248:3305/test?useSSL=false&useUnicode=true&characterEncoding=UTF8&serverTimezone=Asia/Shanghai&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true.# -执行统计任务启动时刻 : 2021-10-28 09:57:05任务结束时刻 : 2021-10-28 09:57:15任务总计耗时 : 10s任务平均流量 : 5B/s记录写入速度 : 0rec/s读出记录总数 : 3读写失败总数 : 0# -查询插入到数据库的中的表数据SELECT * from test.mysqlwriter;+-----+--------+------------------+---------------------+
| uid | name | hobby | operation_time |
+-----+--------+------------------+---------------------+
| 1 | C | 面向过程编程语言 | 2021-10-13 02:43:30 |
| 2 | C++ | 面向对象 | 2021-10-13 10:44:59 |
| 3 | Python | 编程语言 | 2021-10-13 10:48:45 |
+-----+--------+------------------+---------------------+
3 rows in set (0.03 sec)复制
Tips : 非常注意读取和写入的字段数需要一致。
至此本章完毕,下节更精彩。
欢迎各位志同道合的朋友一起学习交流,如文章有误请在下方留下您宝贵的经验知识,个人邮箱地址【master#weiyigeek.top】
更多文章来源: https://weiyigeek.top 【WeiyiGeek Blog - 为了能到远方,脚下的每一步都不能少】
如果你觉得这篇文章不错,请给这篇专栏点个赞、投个币、收个藏、关个注,转个发、这将对我有很大帮助!
