




云计算平台一般都包含三个层次,即IaaS(Infrastructure as a service)、PaaS(Platform as a Service)和SaaS(Software as a Service)。IaaS提供底层的计算、网络、存储等资源,而PaaS则是在IaaS的基础上,为上层开发者提供一些基础的服务,如K8S和database就是很典型的PaaS层提供的服务,SaaS处于最上层,提供面向最终用户的应用或服务,而且一般是基于Web的应用。
K8S cluster API与云计算平台的IaaS、PaaS以及SaaS有什么关系,以及它处于一个什么位置,它又解决了什么痛点(pain point)?这就是本文要介绍的内容。
什么是K8S Cluster API
首先,直接贴出官网对cluster API的定义:
The Cluster API is a Kubernetes project to bring declarative, Kubernetes-style APIs to cluster creation, configuration, and management. It provides optional, additive functionality on top of core Kubernetes.
https://github.com/kubernetes-sigs/cluster-api
不难看出,Cluster API的主要功能就是创建并管理K8S cluster。另一个重点就是它采用的是声明(declarative)的方式,而不是命令式(imperative)。
用过K8S的人都知道,用Kubeadm创建K8S cluster非常简单。那为什么需要Cluster API呢?以前,要创建一个K8S cluster,首先你要准备好IaaS环境,也即是在cloud provider(如AWS、Azure、GCE等)上创建好VM、Network以及存储资源等,然后再用Kubeadm在这些VM上创建K8S cluster。显然,这个过程非常繁琐。而Cluster API则可以一次性将IaaS以及K8S cluster创建好,你只需要准备好配置文件,然后执行一条命令就自动将包括IaaS以及PaaS层的所有资源创建好。而且这些配置可以重复使用。听起来是不是很刺激?
Cluster API这个项目/概念出现也就短短一年的时间,却得到了极大的关注,主要原因在于它将IaaS与PaaS无缝的结合到了一起,解决了以往开发人员反复部署云开发环境的痛点,进一步完善了云计算的生态。
Cluster API实现原理
这里直接附上官网上的一张图,虽然细节有些不是很清楚,但大概逻辑还是很直观的。
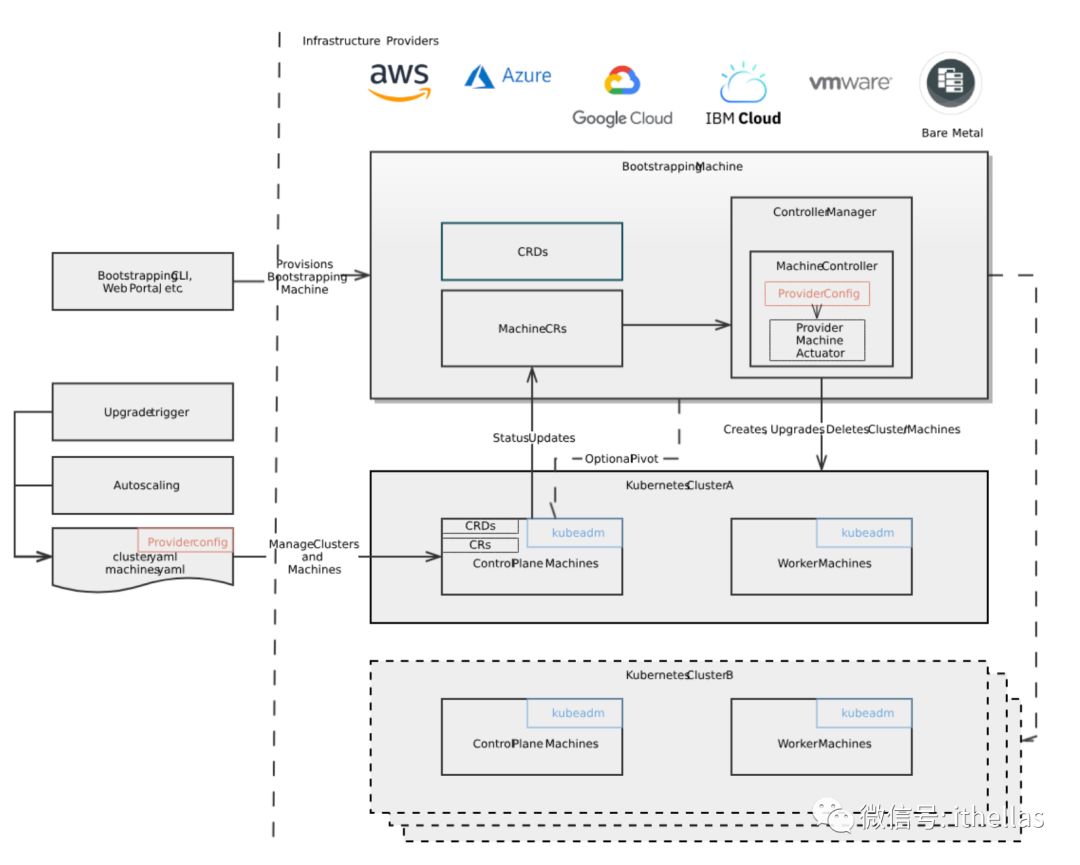
首先要准备好如下4个配置文件:
cluster.yaml
machines.yaml
provider-components.yaml
addons.yaml
然后执行如下命令(不同provider提供的工具可能有差异)即可:
clusterctl create cluster --provider <provider> --bootstrap-type <bootstrap-type> -c cluster.yaml -m machines.yaml -p provider-components.yaml -a addons.yaml
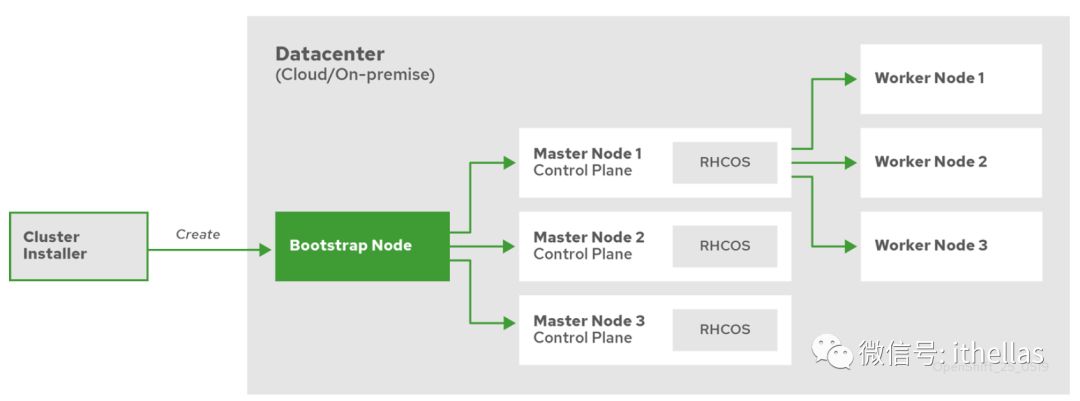
大致执行流程是,首先创建一个bootstrap机器,在上面创建一个K8S cluster,这个cluster起管理作用,我们可以称它为management cluster。然后management cluster创建目标cluster运行所需要的机器,即control plane的机器,继而创建目标cluster。最后通过目标cluster创建worker node。OpenShift Installer的一张图可以很好的说明这个过程。
Cluster API提供了三种创建Bootstrap node/cluster的方式,当然这些大多用于测试或开发的场景,
1. Kind
Kind就是Kubernetes IN Docker,用Kind可以在本地创建K8S cluster,主要用于测试的目的。具体可参考:
https://github.com/kubernetes-sigs/kind复制
2. minikube
这个相信很多人并不陌生,很多开始学习K8S的人都是从minikube开始着手实践的。
3. existing
这个就是将一个现有的K8S cluster当成bootstrap cluster使用。
创建Master Node以及目标K8S cluster就是Cluster API Provider的职责了,具体后面会讲到。
Cluster API Provider
因为Cluster API需要在各个Cloud Provider(i.e. AWS, Azure, GCE, OpenStack, libvirt...)里创建VM等资源,所以需要为各个Cloud Provider实现一个Cluster API Provider,由这些Provider来真正的执行创建VM等资源的操作。
Cluster API最初的v1alpha1定义的接口,Cluster API Provider主要是要实现如下接口,然后将实现的接口注册到Cluster API的Controller中去即可。最后只需要运行一个Controller Manager,也就是Cluster API的Controller。
/// [Actuator]// Actuator controls clusters on a specific infrastructure. All// methods should be idempotent unless otherwise specified.type Actuator interface {// Reconcile creates or applies updates to the cluster.Reconcile(*clusterv1.Cluster) error// Delete the cluster.Delete(*clusterv1.Cluster) error}复制
在Cluster API v1alpha2中,将Actuator接口删除了。Cluster API Provider也就不需要再向Cluster API core Controller注册Actuator的实现了。在v1alpha2中,Cluster API Provider需要实现两个新的Providers,也就是Bootstrap和Infrastructure providers,他们作为独立的Controller运行。Infrastructure Provider功能是在Cloud Provider中创建VM等资源,而Bootstrap的功能是将Machine(VM)转变成K8S的node。
注意:这里的bootstrap与前文中的bootstrap不是一个概念。此处的bootstrap其实就是采用kubeadm创建K8S cluster。
在v1alpha2中,最后需要运行3个Controller Manager,
Core (Cluster API)
Bootstrap Provider
Infrastructure Provider
注意,v1alpha2目标是在8月31发布,可能会延期一些时间。目前所有现存的Cluster API Provider都是基于v1alpha1实现的。同样,如果你现在就急于尽快实现自己的Cluster API Provider,那么就基于v1alpha1,否则就可以考虑v1alpha2。
v1alpha1与v1alpha2之间的详细区别,可以查看如下pull request,
https://github.com/kubernetes-sigs/cluster-api/pull/1211复制
K8S Cluster API vs K8S Cloud Provider
这里先澄清一个概念,前面所说的Cloud Provider是指AWS、Azure、GCE等云服务提供商,当然也可以是指OpenStack、libvirt等;而这里说的Cloud Provider是指K8S为各个云提供商定义的一个统一的接口,用来屏蔽云提供商特定的实现逻辑。本节所说的Cloud Provider,可以参考如下链接:
https://github.com/kubernetes/cloud-provider复制
那么问题来了,K8S Cluster API与K8S Cloud Provider有什么区别?K8S Cluster API主要是通过Cluster API Provider来初始化node和cluster;而K8S Cloud Provider则是在Cluster运行起来之后,从云提供商那里创建Load balancer、Persistent volumes等资源。所以他们之间不是竞争关系,而是相互补充的。明白自己在生态环境中的位置以及自己的界限,是很难得的品质。
Operator
Cluster API官网着重强调了Cluster API采用了声明(declarative)的方式。declarative与Imperative的区别,记得我以前在某篇文章中提过。简言之,declarative就是以一种抽象的方式定义你期望的状态,对用户屏蔽掉具体的技术实现细节;而imperative就是明确定义要怎么做,对用户暴露更多的技术实现细节。
例如,你想在K8S里启动3个nginx实例,declarative的方式就是采用deployment的方式,定义好每个container的参数,告诉K8S你要启动3个副本(replica)。Imperative的方式就是直接定义三个POD,然后提交给K8S去创建。
一个同事曾经举过温控器的例子,我觉得非常形象。declarative的方式就是,你只需要告诉温控器你期望达到的温度,至于怎么达到这个温度,你不需要关心。Imperative的方式就是你要具体告诉温控器怎么达到你期望的温度。
Operator就是基于declarative的方式来实现的。其作用用一句话总结就是:始终保证系统的实际状态与期望的状态保持一致。例如,你希望启动3个nginx实例,如果某个nginx突然崩溃了,那么Operator就会自动帮你再启动一个nginx实例,始终保证有3个实例在运行。
虽然Operator这个概念不是Kubernetes发明的,但是Kubernetes将Operator这个概念运用到了极致。现在几乎所有的Open Source Project都有自己的Operator。毫不夸张的说,现在软件开发、运维模式已经进入到了Operator时代。
关于如何创建自己的Operator,可以参考如下链接:
https://github.com/operator-framework/operator-sdk复制
--END--
