




PolarDB PostgreSQL版(以下简称 PolarDB-PG)是一款阿里云自主研发的企业级数据库产品,采用计算存储分离架构,兼容 PostgreSQL 与 Oracle。PolarDB-PG 的存储与计算能力均可横向扩展,具有高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB-PG 具有大规模并行计算能力,可以应对 OLTP 与 OLAP 混合负载;还具有时空、向量、搜索、图谱等多模创新特性,可以满足企业对数据处理日新月异的新需求。
PolarDB-PG 支持多种部署形态:存储计算分离部署、X-Paxos 三节点部署、本地盘部署。
PolarDB-PG:存储计算分离架构详解
Shared-Storage 带来的挑战
基于 Shared-Storage 之后,数据库由传统的 share nothing,转变成了 shared storage 架构。需要解决如下问题:
- 数据一致性:由原来的 N 份计算+N 份存储,转变成了 N 份计算+1 份存储。
- 读写分离:如何基于新架构做到低延迟的复制。
- 高可用:如何 Recovery 和 Failover。
- IO 模型:如何从 Buffer-IO 向 Direct-IO 优化。
架构原理
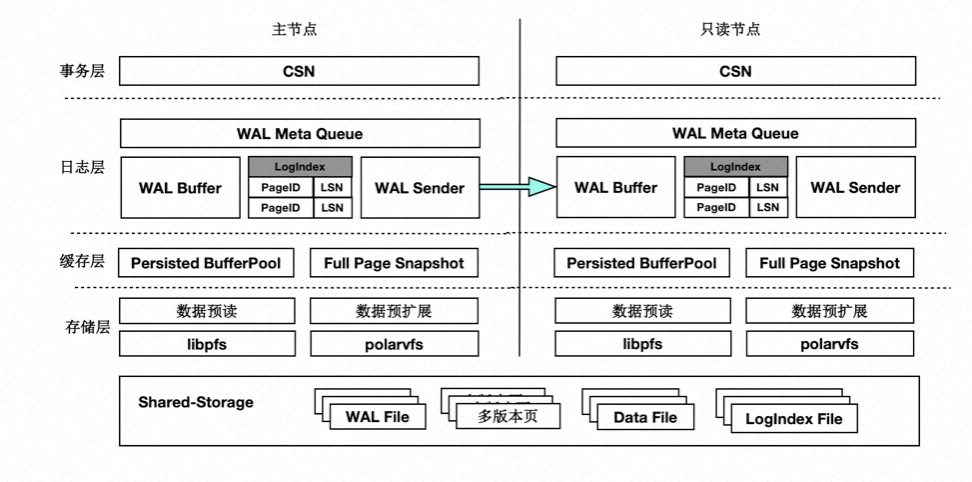

首先来看下基于 Shared-Storage 的 PolarDB-PG 的架构原理。
- 主节点为可读可写节点(RW),只读节点为只读(RO)。
- Shared-Storage 层,只有主节点能写入,因此主节点和只读节点能看到一致的落盘的数据。
- 只读节点的内存状态是通过回放 WAL 保持和主节点同步的。
- 主节点的 WAL 日志写到 Shared-Storage,仅复制 WAL 的 meta 给只读节点。
- 只读节点从 Shared-Storage 上读取 WAL 并回放。
数据一致性
传统数据库的内存状态同步
传统 share nothing 的数据库,主节点和只读节点都有自己的内存和存储,只需要从主节点复制 WAL 日志到只读节点,并在只读节点上依次回放日志即可,这也是复制状态机的基本原理。
基于 Shared-Storage 的内存状态同步
前面讲到过存储计算分离后,Shared-Storage 上读取到的页面是一致的,内存状态是通过从 Shared-Storage 上读取最新的 WAL 并回放得来,如下图:
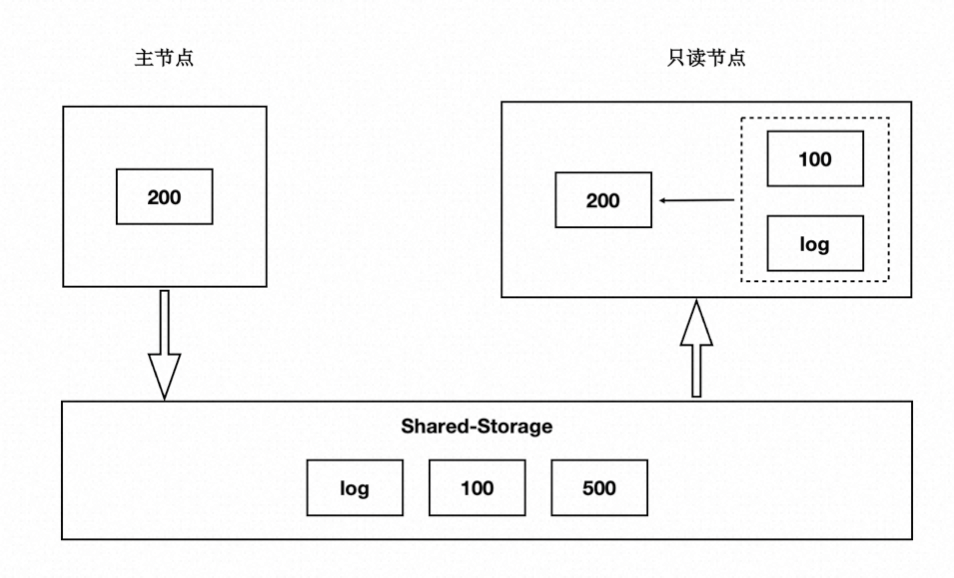

- 主节点通过刷脏把版本 200 写入到 Shared-Storage。
- 只读节点基于版本 100,并回放日志得到 200。
基于 Shared-Storage 的“过去页面”
上述流程中,只读节点中基于日志回放出来的页面会被淘汰掉,此后需要再次从存储上读取页面,会出现读取的页面是之前的老页面,称为“过去页面”。如下图:
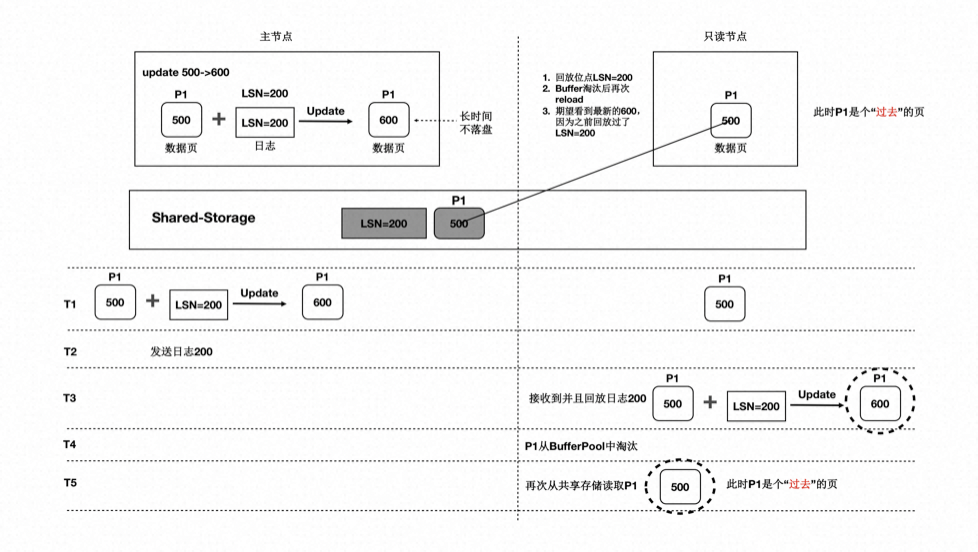

- T1 时刻,主节点在 T1 时刻写入日志 LSN=200,把页面 P1 的内容从 500 更新到 600;
- 只读节点此时页面 P1 的内容是 500;
- T2 时刻,主节点将日志 200 的 meta 信息发送给只读节点,只读节点得知存在新的日志;
- T3 时刻,此时在只读节点上读取页面 P1,需要读取页面 P1 和 LSN=200 的日志,进行一次回放,得到 P1 的最新内容为 600;
- T4 时刻,只读节点上由于 BufferPool 不足,将回放出来的最新页面 P1 淘汰掉;
- 主节点没有将最新的页面 P1 为 600 的最新内容刷脏到 Shared-Storage 上;
- T5 时刻,再次从只读节点上发起读取 P1 操作,由于内存中已把 P1 淘汰掉了,因此从 Shared-Storage 上读取,此时读取到了“过去页面”的内容;
“过去页面” 的解法
只读节点在任意时刻读取页面时,需要找到对应的 Base 页面和对应起点的日志,依次回放。如下图:
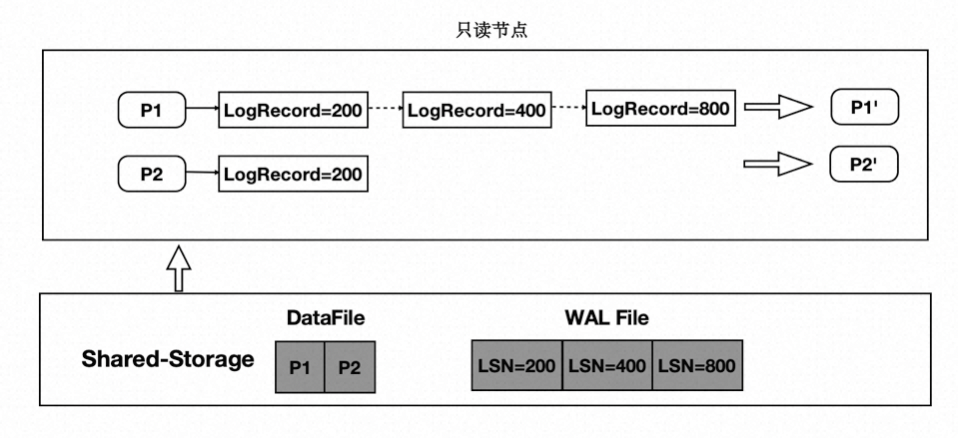

- 在只读节点内存中维护每个 Page 对应的日志 meta。
- 在读取时一个 Page 时,按需逐个应用日志直到期望的 Page 版本。
- 应用日志时,通过日志的 meta 从 Shared-Storage 上读取。
通过上述分析,需要维护每个 Page 到日志的“倒排”索引,而只读节点的内存是有限的,因此这个 Page 到日志的索引需要持久化,PolarDB-PG 设计了一个可持久化的索引结构 - LogIndex。LogIndex 本质是一个可持久化的 hash 数据结构。
- 只读节点通过 WAL receiver 接收从主节点过来的 WAL meta 信息。
- WAL meta 记录该条日志修改了哪些 Page。
- 将该条 WAL meta 插入到 LogIndex 中,key 是 PageID,value 是 LSN。
- 一条 WAL 日志可能更新了多个 Page(索引分裂),在 LogIndex 对有多条记录。
- 同时在 BufferPool 中给该该 Page 打上 outdate 标记,以便使得下次读取的时候从 LogIndex 重回放对应的日志。
- 当内存达到一定阈值时,LogIndex 异步将内存中的 hash 刷到盘上。
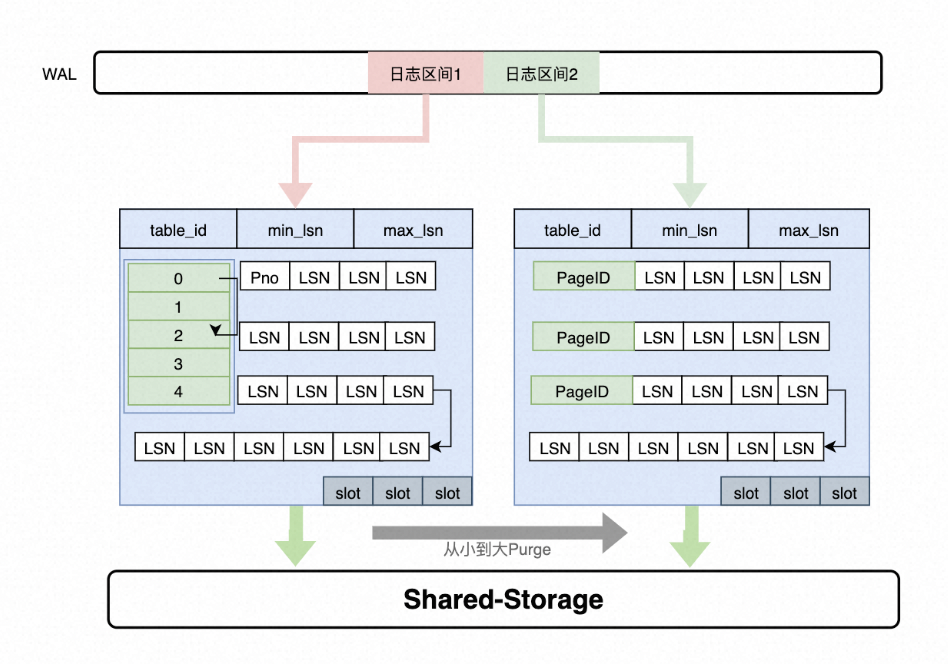

通过 LogIndex 解决了刷脏依赖“过去页面”的问题,也是得只读节点的回放转变成了 Lazy 的回放:只需要回放日志的 meta 信息即可。
基于 Shared-Storage 的“未来页面”
在存储计算分离后,刷脏依赖还存在“未来页面”的问题。如下图所示:
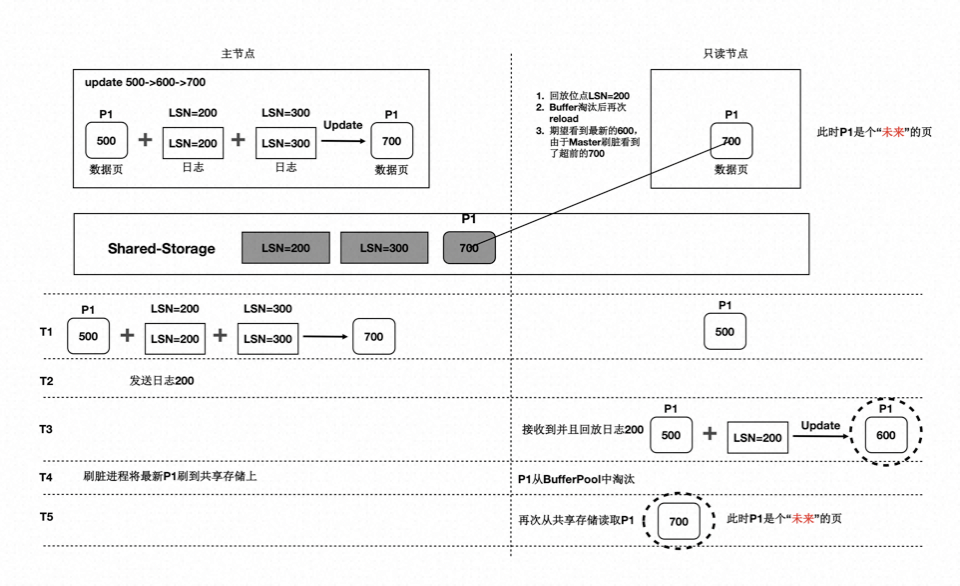

- T1 时刻,主节点对 P1 更新了 2 次,产生了 2 条日志,此时主节点和只读节点上页面 P1 的内容都是 500。
- T2 时刻, 发送日志 LSN=200 给只读节点。
- T3 时刻,只读节点回放 LSN=200 的日志,得到 P1 的内容为 600,此时只读节点日志回放到了 200,后面的 LSN=300 的日志对他来说还不存在。
- T4 时刻,主节点刷脏,将 P1 最新的内容 700 刷到了 Shared-Storage 上,同时只读节点上 BufferPool 淘汰掉了页面 P1。
- T5 时刻,只读节点再次读取页面 P1,由于 BufferPool 中不存在 P1,因此从共享内存上读取了最新的 P1,但是只读节点并没有回放 LSN=300 的日志,读取到了一个对他来说超前的“未来页面”。
- “未来页面”的问题是:部分页面是未来页面,部分页面是正常的页面,会到时数据不一致,比如索引分裂成 2 个 Page 后,一个读取到了正常的 Page,另一个读取到了“未来页面”,B+Tree 的索引结构会被破坏。
“未来页面”的解法
“未来页面”的原因是主节点刷脏的速度超过了任一只读节点的回放速度(虽然只读节点的 Lazy 回放已经很快了)。因此,解法就是对主节点刷脏进度时做控制:不能超过最慢的只读节点的回放位点。如下图所示:
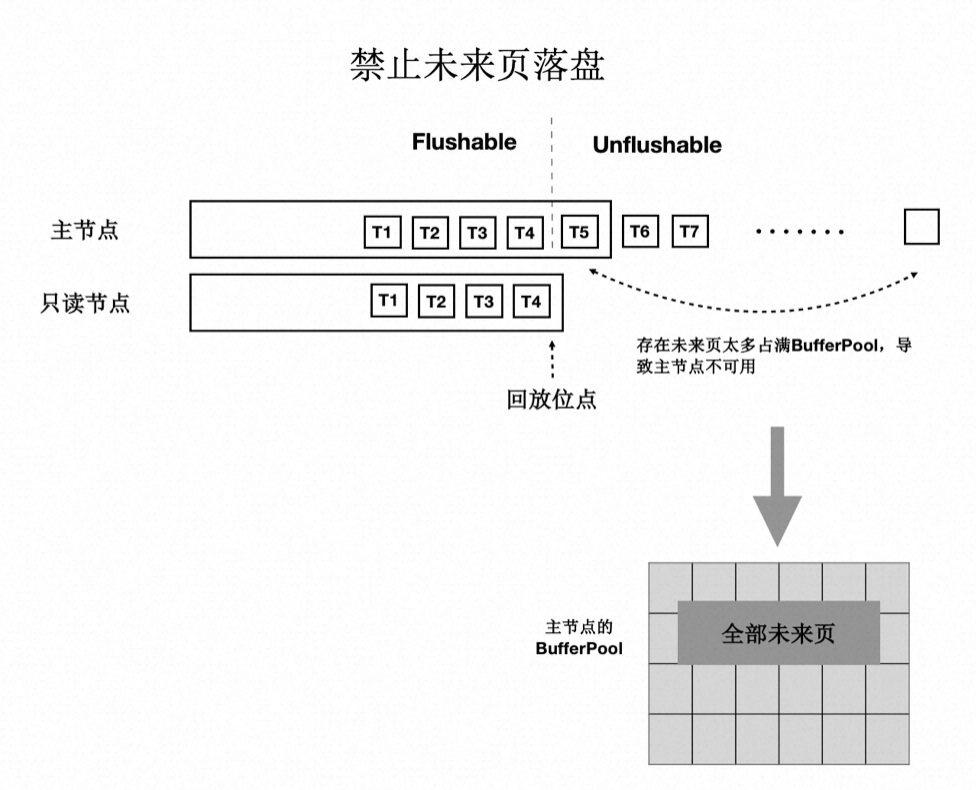

- 只读节点回放到 T4 位点。
- 主节点在刷脏时,对所有脏页按照 LSN 排序,仅刷在 T4 之前的脏页(包括 T4),之后的脏页不刷。
- 其中,T4 的 LSN 位点称为“一致性位点”。
