




PolarDB PostgreSQL版(以下简称 PolarDB-PG)是一款阿里云自主研发的企业级数据库产品,采用计算存储分离架构,兼容 PostgreSQL 与 Oracle。PolarDB-PG 的存储与计算能力均可横向扩展,具有高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB-PG 具有大规模并行计算能力,可以应对 OLTP 与 OLAP 混合负载;还具有时空、向量、搜索、图谱等多模创新特性,可以满足企业对数据处理日新月异的新需求。
原理
架构特性
基于 PolarDB-PG 的存储计算分离架构,我们研发了分布式 MPP 执行引擎,提供了跨机并行执行、弹性计算弹性扩展的保证,使得 PolarDB-PG 初步具备了 HTAP 的能力:
- 一体化存储:毫秒级数据新鲜度
- TP / AP 共享一套存储数据,减少存储成本,提高查询时效
- TP / AP 物理隔离:杜绝 CPU / 内存的相互影响
- 单机执行引擎:在 RW / RO 节点上,处理高并发的 TP 查询
- 分布式 MPP 执行引擎: 在 RO 节点,处理高复杂度的 AP 查询
- Serverless 弹性扩展:任何一个 RO 节点均可发起 MPP 查询
- Scale Out:弹性调整 MPP 的执行节点范围
- Scale Up:弹性调整 MPP 的单机并行度
- 消除数据倾斜、计算倾斜,充分考虑 PostgreSQL 的 Buffer Pool 亲和性


分布式 MPP 执行引擎
PolarDB-PG HTAP 的核心是分布式 MPP 执行引擎,是典型的火山模型引擎。A、B 两张表先做 join 再做聚合输出,这也是 PostgreSQL 单机执行引擎的执行流程。
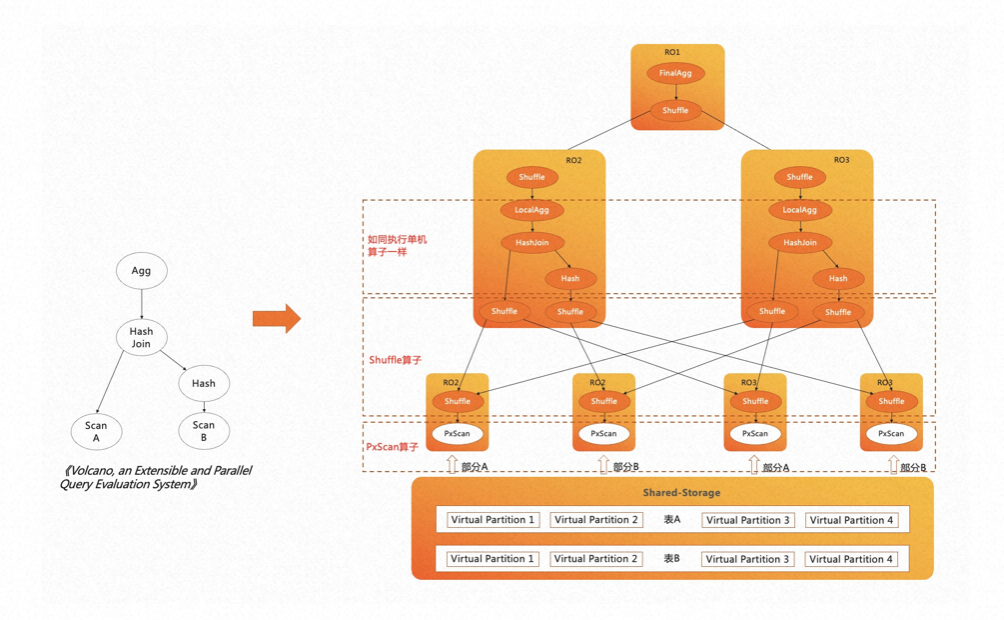

在传统的 MPP 执行引擎中,数据被打散到不同的节点上,不同节点上的数据可能具有不同的分布属性,比如哈希分布、随机分布、复制分布等。传统的 MPP 执行引擎会针对不同表的数据分布特点,在执行计划中插入算子来保证上层算子对数据的分布属性无感知。
不同的是,PolarDB-PG 是共享存储架构,存储上的数据可以被所有计算节点全量访问。如果使用传统的 MPP 执行引擎,每个计算节点 Worker 都会扫描全量数据,从而得到重复的数据;同时,也没有起到扫描时分治加速的效果,并不能称得上是真正意义上的 MPP 引擎。
因此,在 PolarDB-PG 分布式 MPP 执行引擎中,我们借鉴了火山模型论文中的思想,对所有扫描算子进行并发处理,引入了 PxScan 算子来屏蔽共享存储。PxScan 算子将 shared-storage 的数据映射为 shared-nothing 的数据,通过 Worker 之间的协调,将目标表划分为多个虚拟分区数据块,每个 Worker 扫描各自的虚拟分区数据块,从而实现了跨机分布式并行扫描。
PxScan 算子扫描出来的数据会通过 Shuffle 算子来重分布。重分布后的数据在每个 Worker 上如同单机执行一样,按照火山模型来执行。
