




PolarDB PostgreSQL版(以下简称 PolarDB-PG)是一款阿里云自主研发的企业级数据库产品,采用计算存储分离架构,兼容 PostgreSQL 与 Oracle。PolarDB-PG 的存储与计算能力均可横向扩展,具有高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB-PG 具有大规模并行计算能力,可以应对 OLTP 与 OLAP 混合负载;还具有时空、向量、搜索、图谱等多模创新特性,可以满足企业对数据处理日新月异的新需求。
Serverless 弹性扩展
传统 MPP 只能在指定节点发起 MPP 查询,因此每个节点上都只能有单个 Worker 扫描一张表。为了支持云原生下 serverless 弹性扩展的需求,我们引入了分布式事务一致性保证。
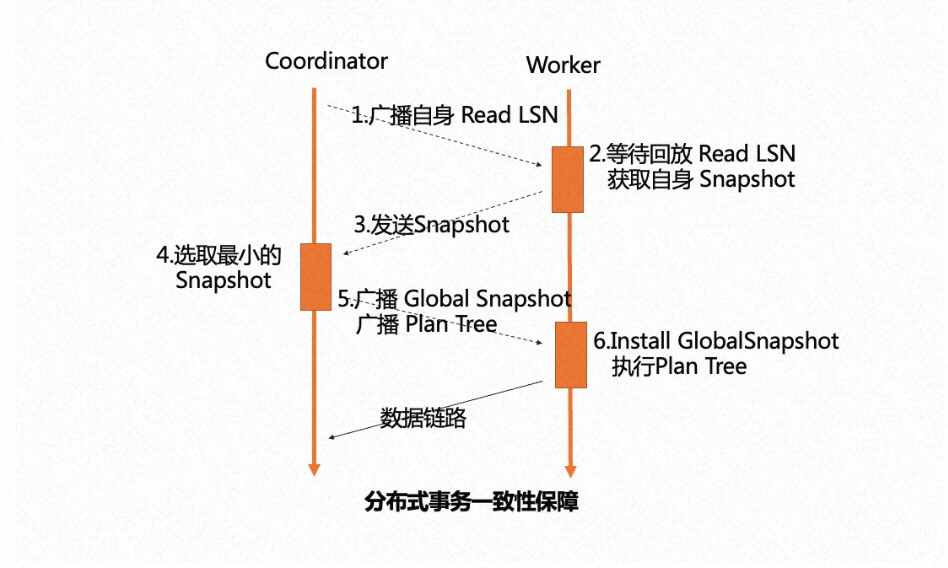

任意选择一个节点作为 Coordinator 节点,它的 ReadLSN 会作为约定的 LSN,从所有 MPP 节点的快照版本号中选择最小的版本号作为全局约定的快照版本号。通过 LSN 的回放等待和 Global Snaphot 同步机制,确保在任何一个节点发起 MPP 查询时,数据和快照均能达到一致可用的状态。
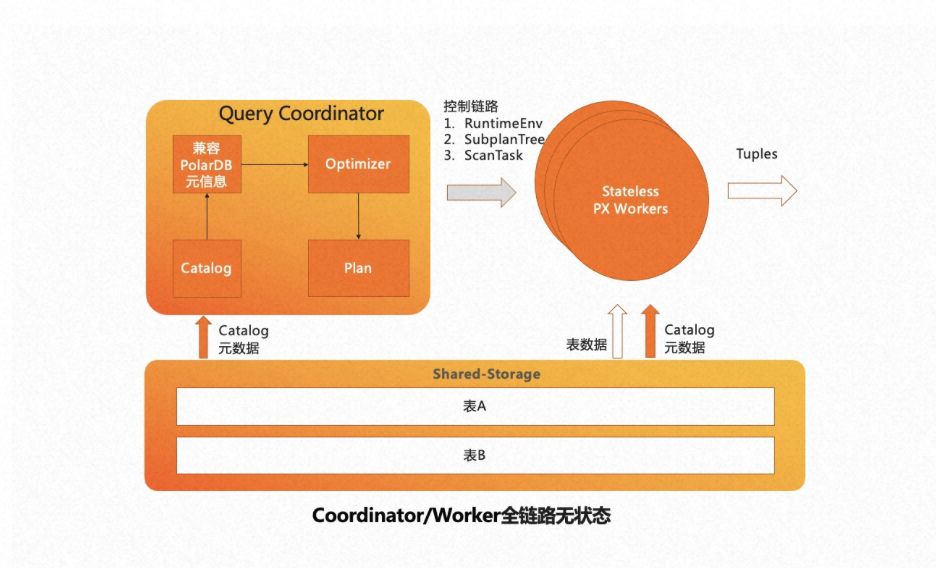

为了实现 serverless 的弹性扩展,我们从共享存储的特点出发,将 Coordinator 节点全链路上各个模块需要的外部依赖全部放至共享存储上。各个 Worker 节点运行时需要的参数也会通过控制链路从 Coordinator 节点同步过来,从而使 Coordinator 节点和 Worker 节点全链路 无状态化 (Stateless)。
基于以上两点设计,PolarDB-PG 的弹性扩展具备了以下几大优势:
- 任何节点都可以成为 Coordinator 节点,解决了传统 MPP 数据库 Coordinator 节点的单点问题。
- PolarDB-PG 可以横向 Scale Out(计算节点数量),也可以纵向 Scale Up(单节点并行度),且弹性扩展即时生效,不需要重新分布数据。
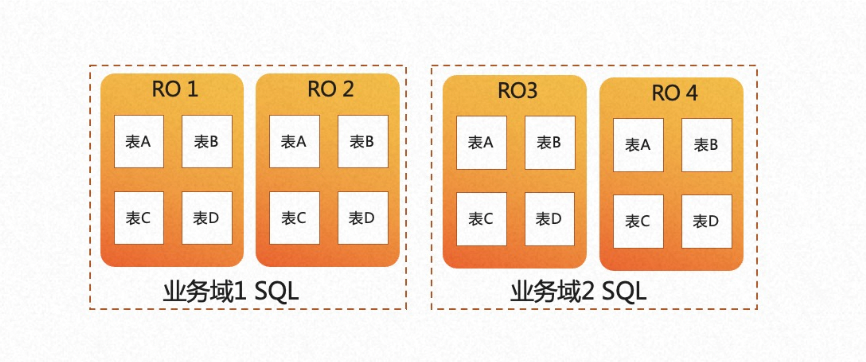
- 允许业务有更多的弹性调度策略,不同的业务域可以运行在不同的节点集合上。如下图右侧所示,业务域 1 的 SQL 可以选择 RO1 和 RO2 节点来执行 AP 查询,业务域 2 的 SQL 可以选择使用 RO3 和 RO4 节点来执行 AP 查询。两个业务域使用的计算节点可以实现弹性调度。

消除倾斜
倾斜是传统 MPP 固有的问题,其根本原因主要是数据分布倾斜和数据计算倾斜:
- 数据分布倾斜通常由数据打散不均衡导致,在 PostgreSQL 中还会由于大对象 Toast 表存储引入一些不可避免的数据分布不均衡问题;
- 计算倾斜通常由于不同节点上并发的事务、Buffer Pool、网络、I/O 抖动导致。
倾斜会导致传统 MPP 在执行时出现木桶效应,执行完成时间受制于执行最慢的子任务。
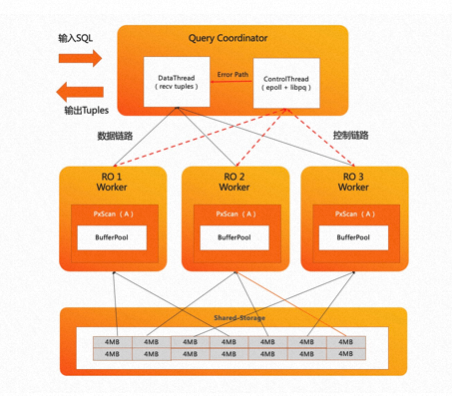

PolarDB-PG 设计并实现了 自适应扫描机制。如上图所示,采用 Coordinator 节点来协调 Worker 节点的工作模式。在扫描数据时,Coordinator 节点会在内存中创建一个任务管理器,根据扫描任务对 Worker 节点进行调度。Coordinator 节点内部分为两个线程:
- Data 线程主要负责服务数据链路、收集汇总元组
- Control 线程负责服务控制链路、控制每一个扫描算子的扫描进度
扫描进度较快的 Worker 能够扫描多个数据块,实现能者多劳。比如上图中 RO1 与 RO3 的 Worker 各自扫描了 4 个数据块, RO2 由于计算倾斜可以扫描更多数据块,因此它最终扫描了 6 个数据块。
PolarDB-PG HTAP 的自适应扫描机制还充分考虑了 PostgreSQL 的 Buffer Pool 亲和性,保证每个 Worker 尽可能扫描固定的数据块,从而最大化命中 Buffer Pool 的概率,降低 I/O 开销。
