




PolarDB PostgreSQL版(以下简称 PolarDB-PG)是一款阿里云自主研发的企业级数据库产品,采用计算存储分离架构,兼容 PostgreSQL 与 Oracle。PolarDB-PG 的存储与计算能力均可横向扩展,具有高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB-PG 具有大规模并行计算能力,可以应对 OLTP 与 OLAP 混合负载;还具有时空、向量、搜索、图谱等多模创新特性,可以满足企业对数据处理日新月异的新需求。
TPC-H 性能对比
单机并行 vs 分布式 MPP
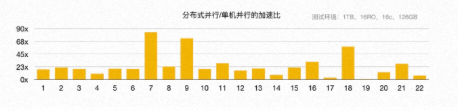
我们使用 256 GB 内存的 16 个 PolarDB-PG实例作为 RO 节点,搭建了 1 TB 的 TPC-H 环境进行对比测试。相较于单机并行,分布式 MPP 并行充分利用了所有 RO 节点的计算资源和底层共享存储的 I/O 带宽,从根本上解决了前文提及的 HTAP 诸多挑战。在 TPC-H 的 22 条 SQL 中,有 3 条 SQL 加速了 60 多倍,19 条 SQL 加速了 10 多倍,平均加速 23 倍。

此外,我们也测试了弹性扩展计算资源带来的性能变化。通过增加 CPU 的总核心数,从 16 核增加到 128 核,TPC-H 的总运行时间线性提升,每条 SQL 的执行速度也呈线性提升,这也验证了 PolarDB-PG HTAP serverless 弹性扩展的特点。
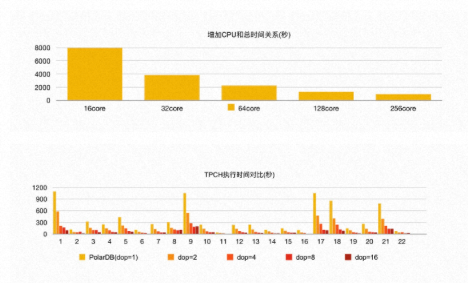


在测试中发现,当 CPU 的总核数增加到 256 核时,性能提升不再明显。原因是此时 PolarDB-PG 共享存储的 I/O 带宽已经打满,成为了瓶颈。
PolarDB-PG vs 传统 MPP 数据库
我们将 PolarDB-PG 的分布式 MPP 执行引擎与传统数据库的 MPP 执行引擎进行了对比,同样使用了 256 GB 内存的 16 个节点。
在 1 TB 的 TPC-H 数据上,当保持与传统 MPP 数据库相同单机并行度的情况下(多机单进程),PolarDB-PG 的性能是传统 MPP 数据库的 90%。其中最本质的原因是传统 MPP 数据库的数据默认是哈希分布的,当两张表的 join key 是各自的分布键时,可以不用 shuffle 直接进行本地的 Wise Join。而 PolarDB-PG 的底层是共享存储池,PxScan 算子并行扫描出来的数据等价于随机分布,必须进行 shuffle 重分布以后才能像传统 MPP 数据库一样进行后续的处理。因此,TPC-H 涉及到表连接时,PolarDB-PG 相比传统 MPP 数据库多了一次网络 shuffle 的开销。
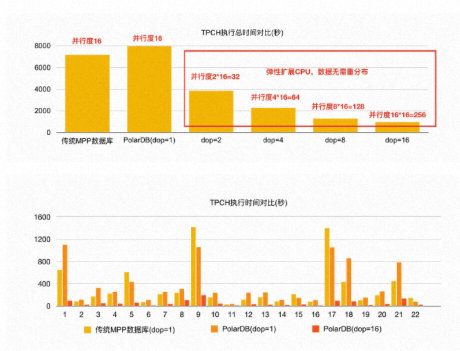


PolarDB-PG 分布式 MPP 执行引擎能够进行弹性扩展,数据无需重分布。因此,在有限的 16 台机器上执行 MPP 时,PolarDB-PG 还可以继续扩展单机并行度,充分利用每台机器的资源:当 PolarDB-PG 的单机并行度为 8 时,它的性能是传统 MPP 数据库的 5-6 倍;当 PolarDB-PG 的单机并行度呈线性增加时,PolarDB-PG 的总体性能也呈线性增加。只需要修改配置参数,就可以即时生效。
