




在工作环境中,我们可能会遇到主机硬件损坏无法在短时间内修复,故障主机的 primary 和 mirror 实例无法使用。此时属于该主机的 primary 实例是单实例状态,如果单实例再次宕机集群将变成 " 双宕”,无法使用有很大的风险。
这时就需要用到备机替换,用一台正常主机替换故障主机。具体步骤如下。
前提条件:此文章所用的主机 “正常主机” 是之前被替换下来的备机,所以环境都是准备好的,如果是一台刚装好的主机,需要按照安装教程,一直做到数据库初始化的上一步。
集群正常运行,无实例宕机。
用 gps01(192.168.210.11, 备) 替换 gps02(192.168.210.35, 旧)
1. 核查两台主机的文件内容是否一致,如果不一致以旧主机为主修改。
cat /etc/security/limits.conf
cat /etc/security/limits.d/20-nproc.conf
cat /etc/selinux/config
cat /etc/sysctl.conf
数据库安装目录版本
2. 备机不能有 gp 实例在运行,元数据目录不能有残留文件。
gps01 无 greenplum 实例

data1 data2 目录下有残留文件

3. 登录 gps01 修改主机名
sudo hostname gps02
sudo cp /etc/sysconfig/network /etc/sysconfig/network220615. bak
sudo vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME= gps02
hostnamectl --static set-hostname gps02
重新连接主机使修改生效
4. 备份集群所有主机的 / etc/hosts 文件 (在 master 节点)
gpssh -f all_hosts
=> sudo cp /etc/hosts /etc/hosts.bak220615
=> exit
单独备份备机 hosts 文件 (备机操作)
sudo cp /etc/hosts /etc/hosts.bak220615
5. 修改 hosts 文件。
sudo vi /etc/hosts
将原本的
192.168.210.35 gps02
更改为
192.168.210.11 gps02
这一步用 sudo 权限输入 root 密码,或者做主机间 root 用户的互信传文件,生产上尝试能否传输到 / etc 下 不能直接传的话 就先传到家目录下 再 sudo 覆盖
gpscp -f ~/all_hosts /etc/hosts =:/etc/hosts
备机单独传输
scp /etc/hosts 192.168.210.11: /etc/hosts
确认 hosts 文件分发成功 (在 master 节点),备机单独确认。
gpssh -f ~/all_hosts
=>cat /etc/hosts | grep gps02
=>exit
7. 集群做互信 (将 master 主机的 hosts 文件中的 ip 修改后就可以做互信)
先将 master 的 known_hosts 文件重命名 再做互信
cd /home/gpadmin/.ssh
mv known_hosts known_hosts220615.bak
gpssh-exkeys -f ~/all_hosts
8. 查看元数据目录路径,确认建立相应的文件(root 权限,master 主机)
1. 先查到 gps02 主机的 dbid

2. 再根据 dbid 查路径。
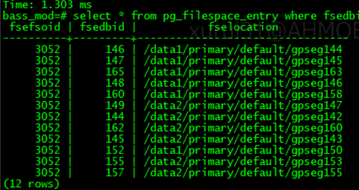
9. 在 gps01(备)建立目录,并修改权限。
mkdir -p /data1/primary/default
mkdir -p /data1/mirror/default
mkdir -p /data1/primary/gpfs
mkdir -p /data1/mirror/gpfs
mkdir -p /data2/primary/default
mkdir -p /data2/mirror/default
mkdir -p /data2/primary/gpfs
mkdir -p /data2/mirror/gpfs
chown -R gpadmin:gpadmin /data*
10. 联系应用侧停调度进行全量恢复 (在 master 节点),需要先将 gps02(192.168.210.35)上的实例全部宕停 192.168.210.11 上如果有 gp 的实例也需全部宕停。
192.168.210.11 上无实例
11. 将残余进程清理干净
psql -c “chekpoint”
gpstop -M fast
12. 以维护模式启动数据库
gpstart -R
gprecoverseg -F
使用 gpstate -e 查看同步进度
13. 等到数据同步完成需要重启数据库切换角色 (gp4 版本)
停止数据库
gpstop
14. 启动数据库 gpstart
查看数据库状态确认没问题 gpstate -e
可能会遇到的问题:
备机替换无法建立互信,需要输入密码,可能是 master 节点的 known_hosts 有旧的主机互信,需尝试删除。
如果发现宕停的实例不足 12 个,尝试重启主机恢复正常。
如果发现有的主机不能传文件,可能是 scp 命令没有 x 权限,赋权即可。
