




在postgresql数据库的多表连接中支持三种连接操作。
1、嵌套循环连接(Nested Loop Join)
在这种连接中,外表的每一行数据都需要与内表的每一行逐行比较。如下图。
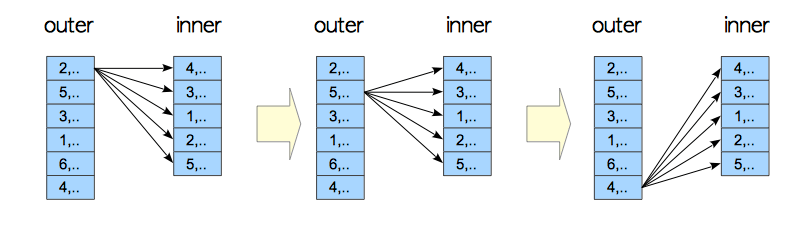
假设现在有一张表random_data2表内有11000行数据,id列有索引,另一张表dbp_sys_log有1行数据。

从上到下可以看到最先seq scan的是dbp_sys_log表,而在数据库中最先扫描的表就是外表(驱动表)。下面的才是内表(被驱动表)。
因为dbp_sys_log是外表所以需要将dbp_sys_log的每行数据逐一与random_data2表中的每行数据进行对比。而random_data2表中的id列建立了索引所以扫面方式是index scan。
建议先忽略index scan 因为这是另一种效率更高的连接方式“索引嵌套循环连接”,普通的嵌套循环连接不好举例,优化器会自动优化连接方式。
1.1 物化嵌套循环连接
在Nested Loop Join中因为是需要将外表的每一行数据与内表对比,所以外表有多少条数据就需要扫描内表多少次。Postgresql支持一种相对高效的扫描方法“materialized (物化)“。所谓物化就是执行器会使用临时元组存储(temporary tuple storage)模块扫描一次将内表的全部数据并加载到工作内存或者临时文件中。
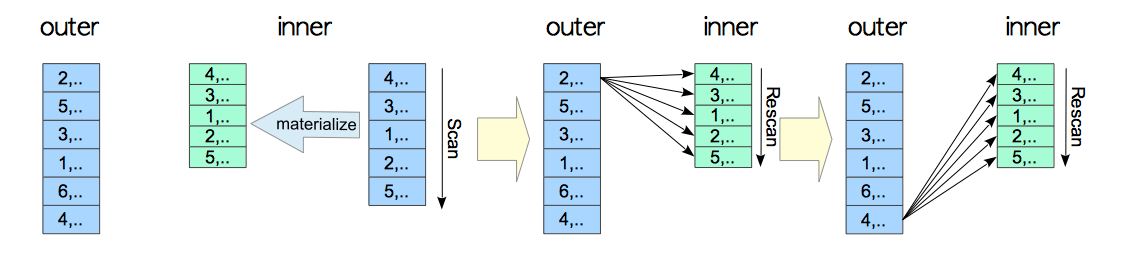

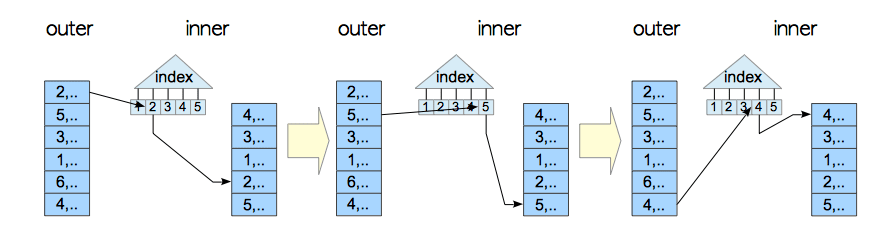
1.2索引嵌套循环连接
如果内表有索引并且满足执行索引的相关条件,也会用索引嵌套循环连接(indexed nested loop join)普通的嵌套扫描,是一种效率比较高的扫描方式。

2、归并连接(Merge Join)
归并连接就是先对内外表连接的列进行排序,再对排序过后的数据进行对比。归并连接一般只能用于自然连接(自然连接是一种特殊的等值连接,他要求两个关系表中进行比较的必须是相同的属性列,无须添加连接条件,并且在结果中消除重复的属性列。)和等值连接
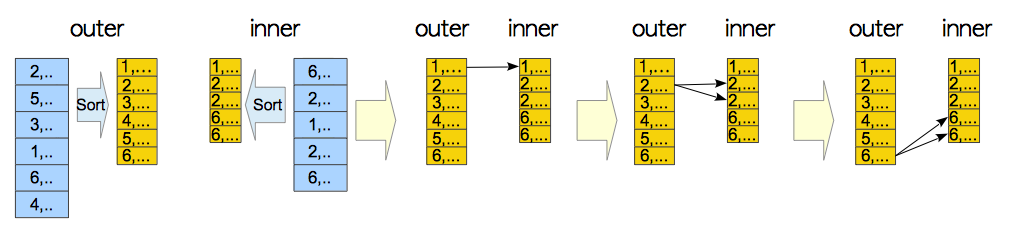
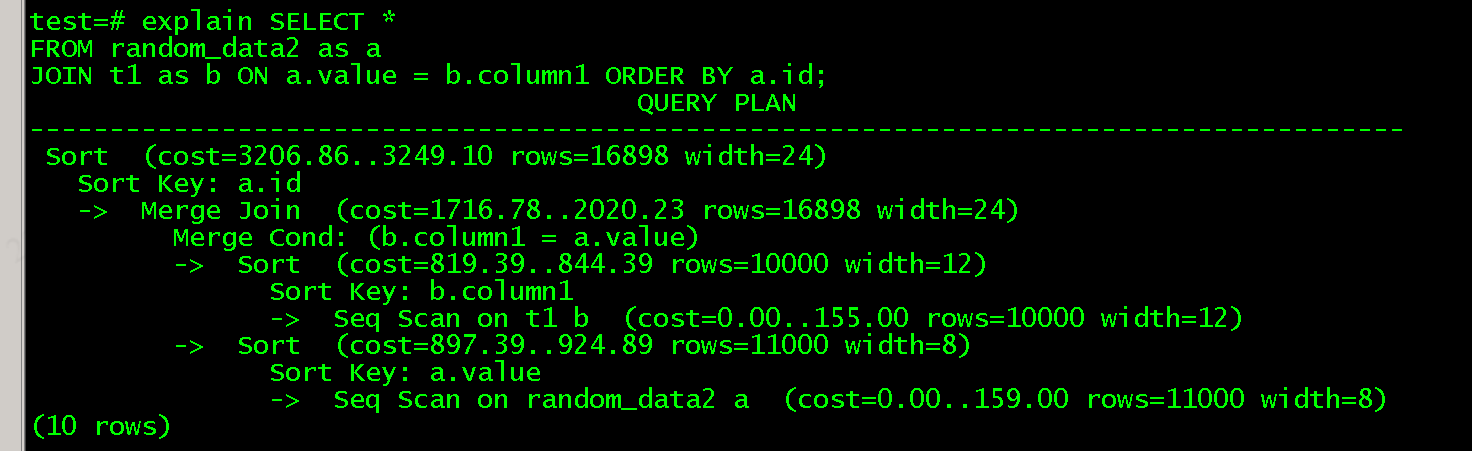
2.1物化归并连接

跟Nested Loop Join一样,归并连接也支持物化,将内表扫描一遍放到内存或者临时文件中。
归并连接同样支持索引。
3、散列连接(Hash Join)
散列连接同样只支持自然连接和等值连接。
在pg数据库中的散列连接有两种方式,当内表的大小不超过work_mem的25%时此时的散列连接就是两阶段内存散列连接(two-phase in-memory hash join);反之则是带倾斜批次的混合散列连接(hybrid hash join)。
3.1 内存散列连接
如同上文所说内存散列连接方式是在work_mem中处理,在这中连接方式中有三个名词和两个阶段。
处理批次:处理批次(batch),散列表的区域。
散列槽:一个处理批次包含多个散列槽(hash slots),pg数据库内部称其为桶(buckets)。后文中统称散列槽。
两个阶段:构建构建(build)阶段和探测(probe)阶段。
构建:在这个阶段中内表的所有元组都会被插入到处理批次中。
探测:在这个阶段每条外表元组都会跟处理批次中的内表元组一一对比,若满足连接条件则会将两条元组连接起来放到临时文件或者内存中。
例1:
SELECT * FROM tbl_outer AS outer, tbl_inner AS inner WHERE inner.attr1 = outer.attr2;
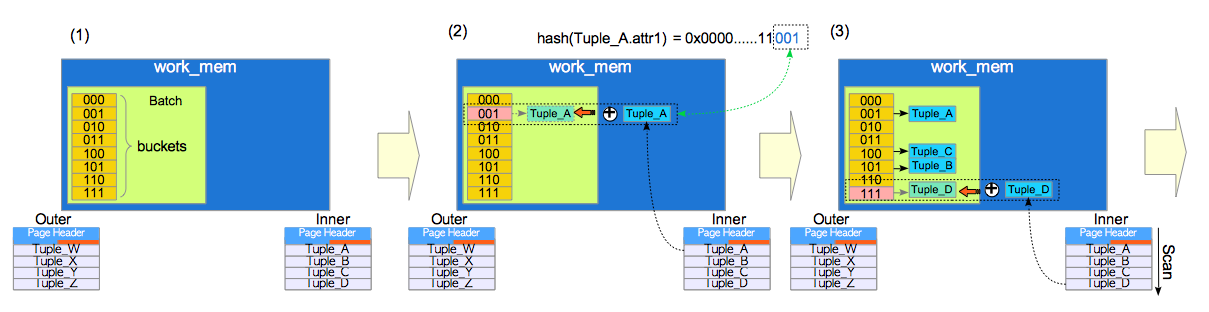
构建步骤:
- 建立处理批次,看图(1)就是batch标识的那块,如图所示在work_mem之中。并且包含buckets(散列槽或者说桶)。图(1)中有8个散列槽,一般来说散列槽的数量是2的整数次幂。
- 将内表的元组依次插入相应的桶中。看图(2)因为本次sql的WHERE子句是inner.attr1 = outer.attr2,因此内置的散列函数会对第一条元组的属性inner.attr1取散列值,用作散列键。图(2)中假设第一条元组的散列值是001就会将这个元组插入到001的散列槽中。注意将内表元组插入散列槽中并不是顺序插入第一个第二个,而是要计算其散列值再插入对应的散列槽。
探测步骤:
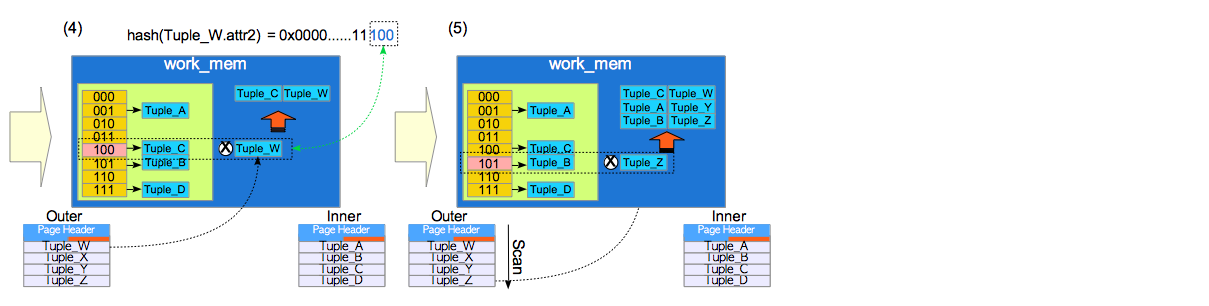
- 计算外表散列键,假设外表的tuple_W的散列键是100。
- 将散列键的值跟散列槽中内表元组的散列键值一一进行比较,如果一样则保存放入内存或临时文件中。不一样不做操作。
3.2带倾斜的混合散列连接
首先说一下混合散列连接,与内存散列连接最大的不同就是当sql的内表的元组无法一次性全部存放在work_mem的单个处理批次中时,数据库会创建多个处理批次,work_mem只会保留一个处理批次在work_mem中。其余的以临时文件的方式创建存储。处理批次的数量由内置函数决定和桶一样也是2的整数次幂。
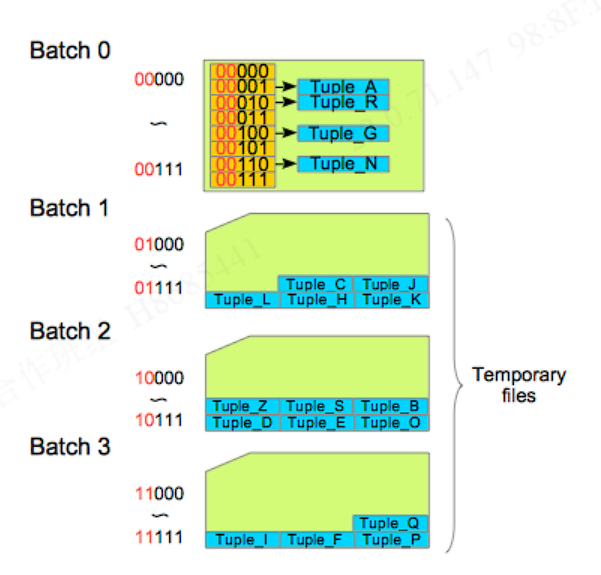
看上图,有八个槽四个批次,batch0此时放在内存中,其余三个在临时文件中。八个槽有五个比特位,前两个代表所处那个批次后三个代表所属的桶。
在第一轮的构建探测中不仅要处理第一个处理批次还会创建所有的处理批次,在之后几轮的操作中处理新的批次都需要读取临时文件,产生io操作产生的代价比较大。所以数据库会在第一轮创建一个特殊的处理批次skew(倾斜批次)。就是说数据库在第一轮中会创建两个处理批次,一个是正常的一个是倾斜的。以此达到能够在第一轮的操作中尽可能处理更多的元组,减少io操作的目的。
倾斜批次为什么能达到上述的目的?因为倾斜批次中的内表元组在连接条件内表一侧属性上的取值,会选择外表连接属性上的高频值(mcv)。
比如有这样的一条sql:
SELECT * FROM customers AS c, purchase_history AS h WHERE c.name = h.customer_name;
Customers表有两个字段“name”“address”,有一万行数据。
purchase_history表有两个字段“customer_name”“buying_item”,有一百万行数据。
假设Customers表中前一千个客户产生了七十万行的购买记录。Customers是内表,purchase_history是外表。则数据库会将内表的前一千个客户存储在倾斜批次中,使用外表的高频值。在第一轮的探测阶段外表中的70%的元组会与倾斜批次中存储的内表元组连接。因此外表越是不均匀的数据在第一轮中越是能存储更多的元组。
例图
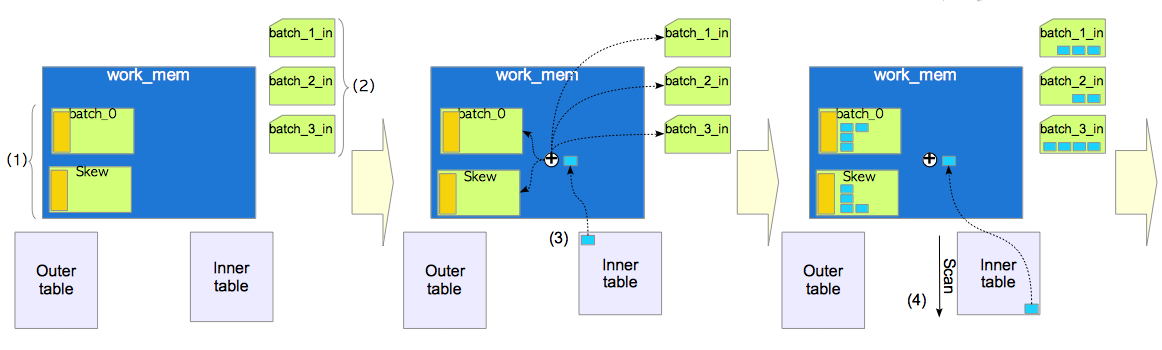
看(1)在work_mem中创建两个处理批次,一个是正常的一个是倾斜的。创建了三个临时文件(batch_1_in……)存放排好序的内表元组。
(2)属于上文说的前10%的放在倾斜批次,其余按后三位比特位放在work_mem的处理批次和临时文件的处理批次中。
(3)依次存放。
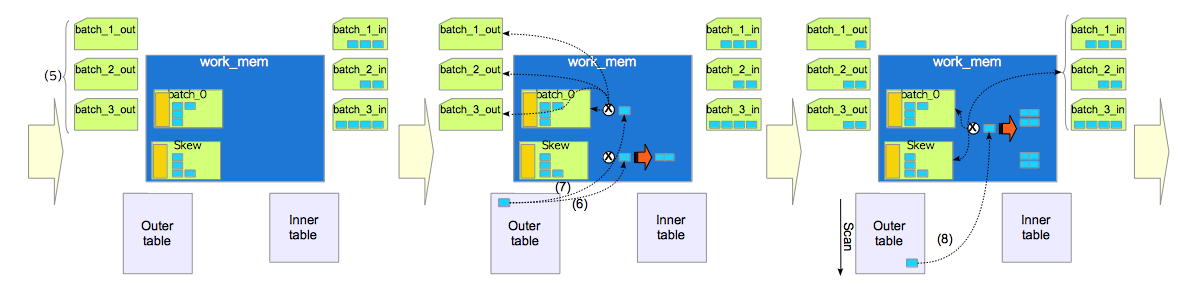
(5)创建存放外表的临时文件处理批次,用于外表排序。
(6)注意看其实是将外表的元组拿到work_mem进行比对,在这个例子中发现这个元组属于高频值就在倾斜批次探测了属于的话直接放在了work_mem中。
(7)在从外表中拿出一个元组跟batch_0和倾斜批次做比对,如果属于这俩的任意一个就直接保存在work_mem中。两个都不属于就放在(5)创建的外表处理批次的临时文件中。因为不能直接跟存放内表元组处理批次做比对。
(8)继续对比剩下的外表元组,并且因为有这个处理批次所以在第一轮中70%的外表元组已经处理完了。

(9)移除倾斜批次与Batch_0,为下一轮处理批次腾地方。
(10)为批次文件batch_1_in中的内表元组执行构建操作。
(11)为批次文件batch_1_out中的外表元组依次执行探测操作。
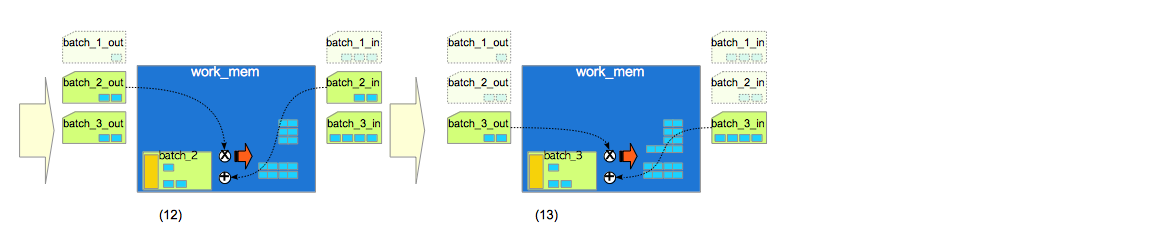
(12)为批次文件batch_2_in与batch_2_out执行构建操作与探测操作。
(13)为批次文件batch_3_in与batch_3_out执行构建操作与探测操作。
最后补充一点可能有人不理解为什么临时文件外表处理批次和临时文件内表的处理批次可以一一对应的匹配连接,会不会出现batch_1_out比batch_1_in多一个batch_1_in没有的元组。因为上文前面说过,hash用于自然和等值连接,且两个临时文件的处理批次在放入临时文件中是排好序的。
