




库版本12.7
前段时间一个pg数据库业务反馈sql突然执行的效率变得很慢,在业务量未明显增长,sql语句未修改的情况下比之前执行慢了很多。
一开始只是优化了一下几个慢sql,优化以后sql执行确实快了很多,但是这只是暂时的。
过了两天业务反馈平台又变慢了,就是点击前台页面要很长的时间。这次刚开始还是优化sql的思路但是效果不大,后来在想是不是表膨胀的比较大,因为业务说几张主表更新的比较频繁。就查看一下表相关的统计信息。
pg_stat_user_tables通过这张表可以看统计信息
relid | 17087 //表的oid
schemaname | public //schema模式
relname | t1 //表名称
seq_scan | 66 //发生全表扫描次数
seq_tup_read | 602468 //全表扫描数据行数,如果这个值很大说明对这个表进行sql很有可能都是全表扫描,需要结合具体的执行计划来看
idx_scan | 149 //索引扫描测试
idx_tup_fetch | 140 //通过索引扫描返回的行数
n_tup_ins | 10000 //插入数据行数
n_tup_upd | 40 //更新数据行数
n_tup_del | 1 //删除数据行数
n_tup_hot_upd | 35 //hot update的数据行数,这个值与n_tup_upd越接近说明update的性能较好,更新数据时不会更新索引。
n_live_tup | 9999 //活着的行数量
n_dead_tup | 34 //死亡的行数量,无效数据行
n_mod_since_analyze | 22 //上次analyze的时间
last_vacuum | //上次手动vacuum的时间
last_autovacuum | //上次autovacuum的时间
last_analyze | //上次手动analyze的时间
last_autoanalyze | 2020-10-12 14:21:44.597134+08 //上次自动analyze的时间
vacuum_count | 0 //vacuum的次数
autovacuum_count | 0 //autovacuum的次数
analyze_count | 0 //analyze的次数
autoanalyze_count | 1 //自动analyze的次数
以上为表字段的含义
主要是看last_autovacuum这个字段,当时显示的执行时间是9.14号,而出现问题的时间是9.25号也就是说将近两个星期数据库没有自动autovacuum。显然是不正常的。
手动对业务的两百多张表执行vacuum analyzer后业务经过测试表示数据库正常了。
再继续排查问题原因。
该数据库有两个实例对应的两个业务,出问题的是a实例,看下b实例的统计信息是否正常。

B实例的正常,有autovacuum,统计信息更新正常,也存在大量autovacuum(to
prevent wraparound),为防止事务id回卷收缩的autovacuum进程。
查看事务年龄监控,事务id达到2亿,开始迫切模式的vacuum freeze
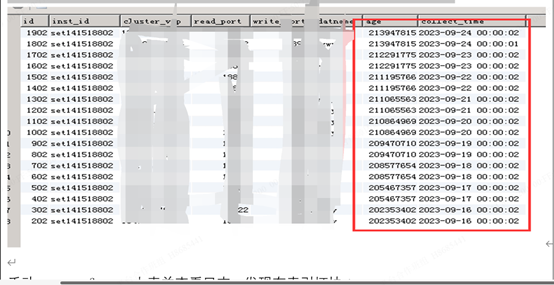
经了解该业务使用较少,而且清理年龄不应该执行这么长的时间。似乎是卡住了。
于是手动vacuum freeze大表并查看日志,发现有索引坏块。
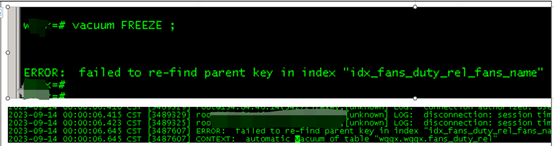
应该是这个索引坏块导致不能自动收缩age。
重建索引修复坏块,并vacuum事务年龄至2亿以下。a库autovacuum进程随即启动。
由此得出结论 b实例索引坏块>b实例不能自动收缩age>a实例的autovacuum失效。
至于索引坏块的产生原因,暂时判断可能是操作系统国产化的原因。
