




环境描述:
名称 | 版本 |
操作系统 | Linux version:redhat 7.4 |
Greenplum | Database:greenplum4.3.30.4 |
问题描述:
在生产环境中我们所维护的 greenplum 集群偶尔会遇到 segments 节点实例宕停的情况,导致实例宕停的因素比较多。如:硬件上的磁盘故障导致 io 较高,内网的网络波动。sql 语法的不规范导致资源消耗过大,大批量的调度语句集中在一个时间点导致集群压力太大。相关参数上的设置过小等等。。。。。。这样的原因都会导致集群某一个或多个 mirrror 实例在固定的时间点宕机,以上的情况一般不会导致 primary 宕机,但是也不一定遇到 primary 也可以按照以下方法排查原因。
排查方法:
一:排查是否是硬件的问题,查看主机日志 messages。
路径:/var/log/messages
查看是否是降级导致的,磁盘降级的关键词根据主机厂商不同一般不一样。
如果是内存或者别的硬件导致的就执行以下命令(如果是硬件导致可能会有 primary 实例宕停)
cat /var/log/messages | grep ker
具体的报错信息需根据经验判断
二:查看数据库日志
需要查看的是宕停实例的数据库日志,并且需要快速获取路径。
查看数据库状态
gpstate -e
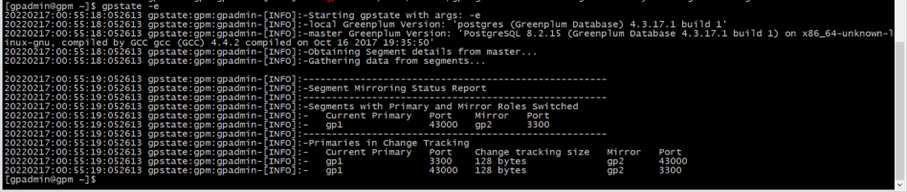
这样看到的只是宕机的实例主机名无法获取到详细的路径,执行以下命令。

可以看到主机名后面的就是宕停实例的目录路径
登录 gp2 切换到 pg_log 目录下
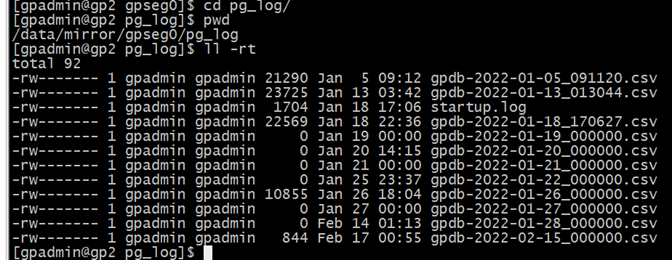
可以看到按日期生成的. csv 文件,这就是数据库日志。但是有的文件后缀不是 000000,是为什么?数据库日志文件本身就是 “gpdb - 年 - 月 - 日_时间 “,显示 000000 是因为在凌晨 12 点整生成的,而那些不是 000000 的则是因为该实例宕停不在记录日志信息只有把实例拉起时才会继续记录,而拉起宕停实例的时间就会自动生成一个对应的. csv 文件。
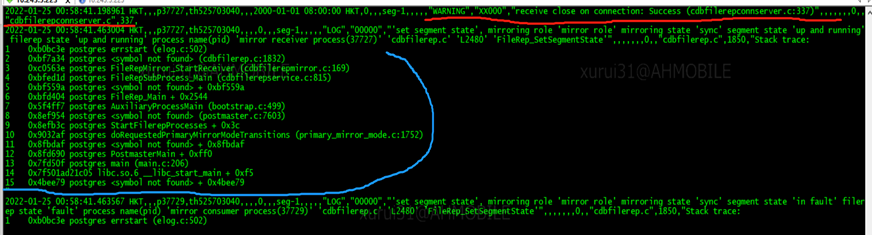
查看相应的日志文件可以看到红色标记的哪一行有 “WARING“关键词,而后面的信息就是当该实例宕停时所打印的信息。而报错信息的大概意思就是” 在连接时收到了关闭信息并且成功了“,为什么会导致这样的情况?
根据网上得到的方案可以修改的参数有这两个
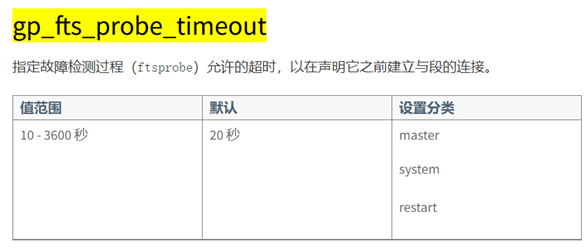
这个参数简单的说就是在 Master 和 Segment 之间的探测超时时长。导致的原因可能时那个时间点集群的压力过大,通信超时,可以将时间调高点。

这里引用 greenplum6.0.1 的解释
等待 Mirror 响应的最长时间,缺省为 600,单位是秒。 在 FTS 检测之外,gp_segment_connect_timeout 参数限制的是 Primary 等待 Mirror 响应的时间,在 Primary 向 Mirror 发送数据时,超过该参数设置的时间仍无法成功,Primary 将会报告 Master 修改 Mirror 的状态为 down,然后 Primary 将会持 续记录 WAL 日志,对于 6 之前的版本,Primary 将进入 change tracking 状态。不过, 对于该参数,至少在 6 之前的版本,真正的超时时间是设定值的 75%。
三:sql 语句的原因
这里就需要在 master 主机部署一个记录集群会话的脚本,将宕机时间点的 sql 反馈给应用让他们检查是否有问题,或者将宕机时间点的会话分散执行。




